This is the multi-page printable view of this section. Click here to print.
HugeGraph-AI
Agentic GraphRAG
Project Background
To address the problem of temporal discrepancies between model training data and real-world data, Retrieval-Augmented Generation (RAG) technology has emerged. RAG, as the name suggests, is a technique that retrieves relevant data from external data sources (Retrieval) to augment (Argument) the quality of the answers generated (Generation) by large language models.
The earliest RAG employed a simple Retrieval-Generation architecture. We take the user’s question, perform some pre-processing (keyword extraction, etc.), obtain the pre-processed question, and then use an Embedding Model to grab relevant information from a vast amount of data as a Prompt, which is then fed to the large language model to enhance the quality of its responses.
However, relying solely on semantic similarity matching to retrieve relevant information may not handle all situations, as the information that can enhance answer quality may not always be semantically similar to the question itself. A common example is: “Tell me the ontological view of the disciple of the philosopher who proposed that water is the origin of all things.” Our data may not directly contain the answer to this question. The knowledge base might contain:
- Thales proposed that water is the origin of all things.
- Anaximander was a disciple of Thales.
- Anaximander identified the Apeiron, which has no formal definition, as the origin of all things.
If we rely solely on semantic similarity matching, we are likely to only retrieve the first sentence to augment the large language model’s answer. However, without information from sentences 2 and 3, and if the large language model lacks philosophy-related knowledge in its training data, it will be unable to correctly answer the question and might even “hallucinate.”
Therefore, GraphRAG technology was developed. A typical GraphRAG involves two steps:
- Offline: We need to build a graph index for the knowledge base offline (converting unstructured data into structured data and storing it in a graph database).
- Online: When the GraphRAG system receives a user question, it can capture the relationships between different entities in the knowledge base using the graph database. Consequently, we can retrieve the three sentences above (the specific graph database index might look like the following example).
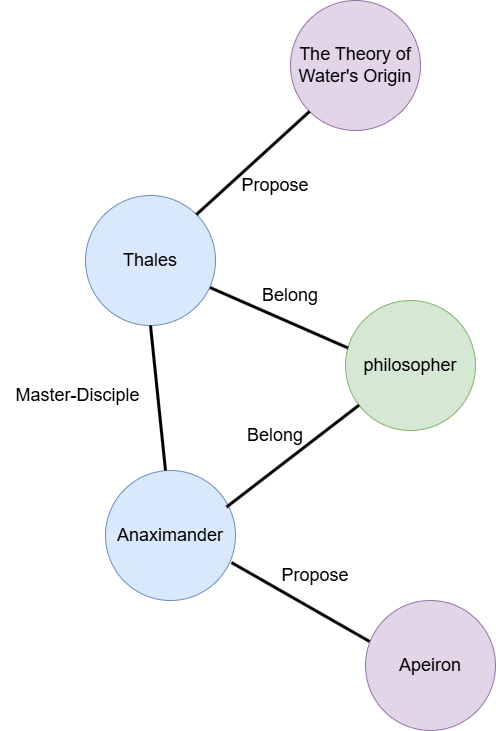
However, GraphRAG itself also presents several challenges:
- How to construct the Graph Index is a complex task, and the quality of the Graph Index impacts the quality of the model’s answers.
- The GraphRAG index construction process consumes a significant number of tokens.
- GraphRAG involves a variety of graph algorithms. How can we achieve the best Retrieval performance? (The configuration space is too large).
This project primarily focuses on the third issue. We aim to leverage the generalization capabilities of large language models to automatically identify the user’s intent within the question and then select the appropriate configuration (such as choosing the most suitable graph algorithm) to retrieve the corresponding data from the graph database to enhance the quality of the large language model’s answer. This is the objective of Agentic GraphRAG.
Existing Workflow: Elegant Decoupling, Unfinished Parallelism
The current HugeGraph-AI project has two core abstractions:
- Operator: Represents an “atomic operation unit” responsible for completing a specific subtask, such as vector index construction, vector similarity search, graph data related operations, and so on.
- Workflow: An execution flow composed of Operators as nodes in a chain-like structure. The pre-defined Workflows in the project correspond one-to-one with the project’s demo use cases (e.g., GraphRAG, Vector-Similarity-Based RAG).
The implementation of an Operator needs to adhere to the following interface:
class Operator:
@abstractmethod
def run(context: dict[str, Any]) -> dict[str,Any]:
return {}
During actual runtime, an Operator accepts a dictionary-type context object as input, and the returned object is also a dictionary, which can be used as input for the next Operator. This design has one very clever aspect: it decouples the dependencies between different Operators from the specific implementation of the Operator itself. Each Operator is a relatively independent entity. If Operator A needs to rely on the output of Operator B, it only needs to check if the context object contains the output of Operator B. This is a loosely coupled design. The advantage is that we can easily combine different Operators freely. Assembling (configuring) a suitable Workflow to serve user requests based on different user inputs - isn’t that precisely the goal of Agentic GraphRAG mentioned in the project background?
👉🏼 Theoretically, the existing design can already transition smoothly to Agentic GraphRAG. However, the current design has several outstanding issues:
1. The existing scheduler only supports chain-like Workflows, missing potential parallelism.
2. The existing scheduler cannot reuse Workflows that are repeatedly used.
Breaking Free from Chains: Embracing a New Architecture
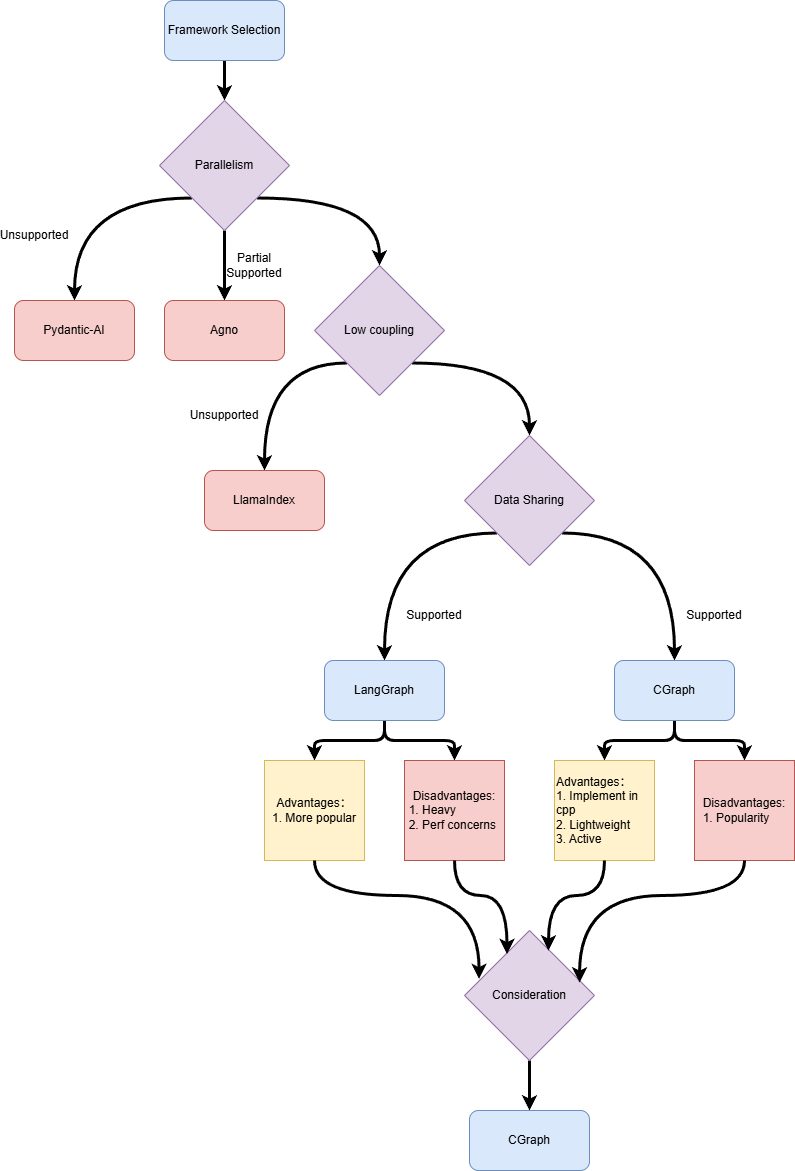
The previous scheduler inspired us with the idea that decoupling at the Operator level is a good design principle. However, the limited capabilities of the scheduler itself restrict the potential of the Workflow. Therefore, we plan to replace the scheduler in the project! After a brief survey of several different Workflow orchestration frameworks, we believe the following features are the criteria for selecting a scheduler (hereinafter, we uniformly refer to the framework’s orchestration object as Workflow, and Workflow consists of a series of Tasks):
- Parallelism: Can different Tasks in a Workflow without data dependencies be automatically executed in parallel?
- Low Coupling: The specific implementation of a Task should be decoupled from the Workflow itself (in layman’s terms: can a Task be a node in several different Workflows, and does the implementation of a Task need to include constraints related to dependencies on other Tasks?)
- Data Sharing: Since we want to decouple the dependencies between different Tasks, we need a Workflow-level data sharing mechanism to share data (for parameter passing) between different Tasks.
- Provides a Python Interface.
AI Framework Rumble
We first turned our attention to the currently popular AI Workflow scheduling frameworks. Around the aforementioned dimensions, we investigated several different Workflow orchestration frameworks - LlamaIndex, Agno, Pydantic-Ai, and LangGraph.
LlamaIndex
Regarding LlamaIndex, we will use a common example to illustrate the design philosophy of this framework.
from workflows import Workflow, Context, step
from workflows.events import StartEvent, StopEvent, Event
class StepEvent(Event):
message: str
class MyWorkflow(Workflow):
@step
async def step_one(self, ctx: Context, ev: StartEvent) -> StepEvent:
current_count = await ctx.store.get("count", default=0)
current_count += 1
await ctx.store.set("count", current_count)
print("step one called once")
return StepEvent("launch step two")
@step
async def step_two(self, ctx: Context, ev: StepEvent) -> StopEvent:
print("step two called once")
return StopEvent()
From the above simple example, we can see many problems. First, let’s clarify a concept: a Workflow consists of two elements: Tasks and the dependencies between Tasks. Once these two elements are determined, a Workflow is established. We can see that in LlamaIndex, the implementation of each Task (corresponding to the function annotated with @step in the code) has a dependency on the Workflow. This is because the implementation of each Task needs to pass the Event object as a parameter, but the Event parameter is actually a constraint on the dependencies between Tasks. Therefore, LlamaIndex does not have the characteristic of low coupling. At the same time, we also found that the Task being a member function of the Workflow class itself violates our earlier requirement that Tasks should be able to be used in multiple different Workflows. However, after investigation, LlamaIndex’s data sharing and parallel features are reasonably good. It’s just that the programming interface built on the event-driven model sacrifices programming flexibility while ensuring ease of use.
Agno
Still starting with the example:
from agno.workflow import Router, Step, Workflow
def route_by_topic(step_input) -> List[Step]:
topic = step_input.input.lower()
if "tech" in topic:
return [Step(name="Tech Research", agent=tech_expert)]
elif "business" in topic:
return [Step(name="Business Research", agent=biz_expert)]
else:
return [Step(name="General Research", agent=generalist)]
workflow = Workflow(
name="Expert Routing",
steps=[
Router(
name="Topic Router",
selector=route_by_topic,
choices=[tech_step, business_step, general_step]
),
Step(name="Synthesis", agent=synthesizer),
]
)
workflow.print_response("Latest developments in artificial intelligence and machine learning", markdown=True)
From this example, we can see that the binding relationship between the Workflow itself and the Task is determined by specifying the steps parameter. Theoretically, after defining a Task, we can use it in different Workflows. Agno’s design meets our low-coupling standard.
However, there are certain limitations in terms of data sharing and task parallelism.
First, let’s look at task parallelism, with the following example:
workflow = Workflow(
name="Parallel Research Pipeline",
steps=[
Parallel(
Step(name="HackerNews Research", agent=hn_researcher),
Step(name="Web Research", agent=web_researcher),
Step(name="Academic Research", agent=academic_researcher),
name="Research Step"
),
Step(name="Synthesis", agent=synthesizer), # Combines the results and produces a report
]
)
Agno specifically designed a parallel interface, requiring us to explicitly define which tasks can be executed in parallel during static compilation (although Python doesn’t really have a compilation time; it should be called “when writing code” haha 😀). However, the Workflow ultimately constructed by Agentic GraphRAG might be planned by the model at runtime, determined dynamically. Considering this, we believe Agno’s parallelism feature does not meet our requirements.
Next is data sharing. The Agno framework supports three different types of Tasks:
- Agent
- Team (composed of multiple Agents)
- Pure Function
We inspected the latest version of the Agno source code at the time of our research and found that Agno supports state sharing only between Agents and Teams. Therefore, for those Tasks that are suitable for implementation with Pure Functions, we need to support an additional data-sharing mechanism. Consequently, Agno’s data-sharing mechanism also does not meet our requirements.
Pydantic-Ai
We saw from the official documentation

Surprisingly, the Pydantic-Ai framework doesn’t support automatic parallelism at the Task level.
Similar to the LlamaIndex framework, it adopts an event-driven programming model. Therefore, the Workflow and Task are not completely decoupled. However, it’s worth noting that a Pydantic-Ai Task can be used in multiple different Workflows.
LangGraph
Finally, we’ve arrived at LangGraph. The reason we hadn’t researched LangGraph before was because a teammate believed LangGraph itself was too heavy. In the previous version, even when using only a part of LangGraph’s functionality (scheduling), it was necessary to import LangGraph’s full dependencies. Importing LangGraph might make the project “heavy.” Seeing phrases like “xxx is xxx times faster than LangGraph” in other open-source projects also influenced our decision-making. So, it’s only now that we’re putting it on the research agenda.
Let’s take a look at a LangGraph example.
class State(TypedDict):
topic: str
joke: str
improved_joke: str
# Nodes
def generate_joke(state: State):
"""First LLM call to generate initial joke"""
msg = llm.invoke(f"Write a short joke about {state['topic']}")
return {"joke": msg.content}
def check_punchline(state: State):
"""Gate function to check if the joke has a punchline"""
# Simple check - does the joke contain "?" or "!"
if "?" in state["joke"] or "!" in state["joke"]:
return "Pass"
return "Fail"
def improve_joke(state: State):
"""Second LLM call to improve the joke"""
msg = llm.invoke(f"Make this joke funnier by adding wordplay: {state['joke']}")
return {"improved_joke": msg.content}
# Build workflow
workflow = StateGraph(State)
# Add nodes
workflow.add_node("generate_joke", generate_joke)
workflow.add_node("improve_joke", improve_joke)
# Add edges to connect nodes
workflow.add_edge(START, "generate_joke")
workflow.add_conditional_edges(
"generate_joke", check_punchline, {"Fail": "improve_joke", "Pass": END}
)
workflow.add_edge("improve_joke", END)
# Compile
chain = workflow.compile()
# Invoke
state = chain.invoke({"topic": "cats"}
This is a simplified example from the official documentation. We can see that LangGraph, based on the Graph API, decouples the Workflow and Task by calling workflow.add_edge to specify the Workflow’s dependencies. It also supports a global State as the Workflow’s state for data sharing between Tasks. According to the official documentation, LangGraph supports automatic parallel execution of Tasks. We’ve finally found a Workflow orchestration framework that meets all of our requirements!
总结
| Parallelism | Low Coupling | Data Sharing | Python Interface | |
|---|---|---|---|---|
| LlamaIndex | Supported | Not Supported | Supported | Supported |
| Agno | Supported but doesn’t meet requirements | Supported | Supported but doesn’t meet requirements | Supported |
| Pydantic-Ai | Not Supported | Not Supported | Supported | Supported |
| LangGraph | Supported | Supported | Supported | Supported |
CGraph —— Graph with Python Interaface Implement in C++
Just as we were focusing on LangGraph, a teammate mentioned a new solution - CGraph. This is a graph scheduling framework developed by open-source creator Chunel using C++, and it aims to compete with the state-of-the-art task scheduling framework, Taskflow. CGraph, formally known as Color Graph, is a C++ project, but it thoughtfully provides a Python interface. After delving deeper, we discovered that CGraph’s design philosophy aligns perfectly with ours: Like LangGraph, CGraph is based on a graph-based declarative API, perfectly supporting the parallelization, low coupling, and data sharing requirements we need.
If the statement “C++ stands at the top of the programming language contempt chain” is a funny joke, it actually reflects programmers’ ultimate pursuit of underlying performance. Apart from this “inherent” advantage, the biggest difference between CGraph and LangGraph is its purity - it doesn’t build a huge ecosystem, but focuses solely on making “task scheduling” as good as possible.
However, what truly made us decide was the project’s “heartbeat”. We contacted the author, Chunel, and felt the vigorous vitality of CGraph. In the open-source world, vitality is the future. A constantly evolving, actively responsive community is far more trustworthy than a frozen, behemoth feature-set.
We believe that an excellent technology selection is not only about matching functionality but also about recognizing the project’s future potential. (Welcome to witness its growth together: https://github.com/ChunelFeng/CGraph)
Architectural Design
Initially, our goal was very simple: to build our own scheduler based on CGraph. However, after deeper reflection, we realized that a good scheduler stems from a profound understanding of the scheduling target (time for some self-reflection 🤣). Just like CPU schedulers and GPU schedulers adopt different scheduling strategies due to the differences in their scheduling targets and ecosystem positioning.
Is the Abstraction Design Reasonable?
So, we began to examine the abstraction we call Workflow. In the previous design, it was a linked list of Operators. Such a design negated the possibility of parallelism. So, is it reasonable to say that a Workflow is a DAG graph composed of a series of Operators?
Intuitively, this definition is reasonable. However, in practice, we found that it’s not a good design for each node in the Workflow (which we’ll call a Node from now on) to correspond one-to-one with an Operator. This is because we need to reuse Workflows between different requests (this can save on the inevitable resource creation during Workflow construction and the performance overhead brought about by DAG graph validation).
For example, vector similarity search is a very common RAG process. However, depending on the interfaces exposed by different underlying vector databases, we may need to provide FaissVectorSearch, VectraVectorSearch, and other Operators with the same purpose but different specific implementations. If we equate Operators with Nodes in the Workflow, our chances of reusing Workflows will be greatly reduced because the Workflow for searching using Faiss and the Workflow for searching using Vectra will be different Workflows. But if we encapsulate similar vector index Operators into a VectorSearchNode, will we be able to have more Workflow reuse opportunities? In the specific implementation of VectorSearchNode, we only need to call the corresponding Operator as needed. Adding a layer in between Workflow and Operator has the following three benefits:
- When adding a new Operator, we only need to modify the specific implementation of the corresponding Node, without modifying the logic of the upper-level Workflow. The Operator is responsible for the Node, and the Node is responsible for the Workflow, which achieves a good separation of duties.
- We have more opportunities for Workflow reuse.
- By introducing a new Node abstraction, we don’t need to modify the implementation of the underlying Operator during the refactoring process, which reduces the mental burden during refactoring.
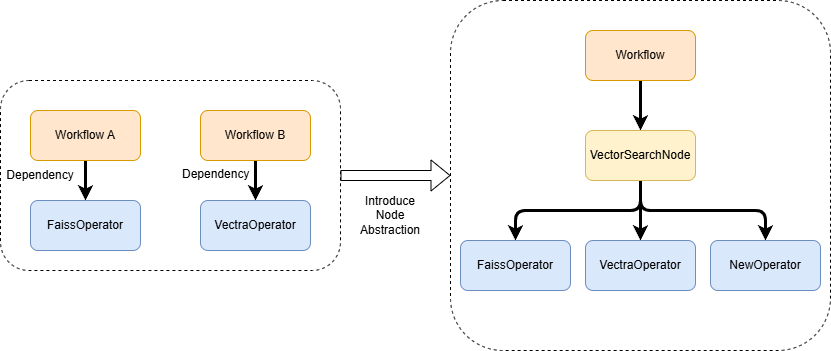
Since we want to reuse the same type of Workflow across requests, we need to ensure that the Workflow itself is stateless. Because if the reused Workflow still carries the state of the previous request, users may get unexpected results. The state of the Workflow can be divided into two types:
- User input state (which we call WorkflowInput): This part is constituted by the user’s request.
- Workflow intermediate state (which we call WorkflowState): This is the temporary data, calculation results, etc., generated by each Node in the Workflow during execution.
We need to ensure that both of these states are clean during Workflow execution. However, these two different states are used at different times, which also determines their completely different lifecycles:
- WorkflowInput is constructed and injected before Workflow execution, and its mission is completed after Workflow execution, and it should be destroyed.
- WorkflowState must be empty or in an initial (pristine) state before Workflow execution, and is dynamically read and written during the execution process.
We use the GParam (global parameter) abstraction provided by the CGraph framework to achieve fine-grained state isolation:
- Separate Contexts: We define two independent
GParamcontexts for WorkflowInput and WorkflowState. - Inject Lifecycle Hooks: We encapsulate the execution logic of the workflow to implement the following automated cleanup mechanisms:
- Pre-execution Hook: Automatically resets the WorkflowState context, ensuring that each execution starts on a “clean canvas.”
- Post-execution Hook: Automatically clears the WorkflowInput context, preventing its data from leaking to the next call.
This way we can ensure that each time the Workflow is executed, these two states only contain the state of the current request. Since the WorkflowInput state is reset after Workflow execution, we can only selectively choose some data from the WorkflowState to return to the user. Therefore, we get the interface that a Flow abstraction should implement.

class BaseFlow(ABC):
"""
Base class for flows, defines three interface methods: prepare, build_flow, and post_deal.
"""
@abstractmethod
def prepare(self, prepared_input: WkFlowInput, **kwargs):
"""
Initalize the WkFlowInput according to the user request
"""
@abstractmethod
def build_flow(self, **kwargs) -> GPipeline:
"""
Used to construct Workflow objects that can be run on top of CGraph.
"""
@abstractmethod
def post_deal(self, **kwargs):
"""
Assemble the response to be returned to the user from the WorkflowState
"""
Okay, returning to the Node abstraction itself, the Node is an abstraction of a certain functionality, and its underlying implementation may correspond to multiple different abstractions. We need to consider the following questions:
- How to decouple the Node layer and the Operator layer as much as possible.
- Nodes can be parallel, but there is shared data within the Workflow. How do we solve potential concurrency problem?
We know that the input and output of the Operator’s run method are dictionaries (see the introduction to the existing Workflow architecture above). To decouple the Node layer and the Operator layer as much as possible, we want the Node layer to also call Operators in the same way. Therefore, we need to implement a JSON serialization method for the WorkflowState. Before calling the Operator, we convert the WorkflowState into a dictionary format and pass it to the Operator. Then, we deserialize the Operator’s execution result back into WorkflowState.
To solve the data race problem caused by concurrent access, we can use MVCC (Multi-Version Concurrency Control) to ensure that the Operator operates on multiple different copies. After obtaining the Operator’s return result, we synchronize the result to the WorkflowState under the protection of a concurrency-safe lock. Therefore, we can obtain the following Node abstraction:
class BaseNode(GNode):
// WorkflowState
context: Optional[WkFlowState] = None
// WorkflowInput
wk_input: Optional[WkFlowInput] = None
def init(self):
// initalize the WorkflowState & WorkflowInput from pipeline
return init_context(self)
def node_init(self):
"""
Overload this method to customize the node initalization logic
"""
return CStatus()
def run(self):
"""
Main logic for node execution, can be overridden by subclasses.
Returns a CStatus object indicating whether execution succeeded.
"""
sts = self.node_init()
if sts.isErr():
return sts
if self.context is None:
return CStatus(-1, "Context not initialized")
self.context.lock()
try:
data_json = self.context.to_json()
finally:
self.context.unlock()
res = self.operator_schedule(data_json)
self.context.lock()
try:
if res is not None and isinstance(res, dict):
self.context.assign_from_json(res)
elif res is not None:
log.warning("operator_schedule returned non-dict type: %s", type(res))
finally:
self.context.unlock()
return CStatus()
def operator_schedule(self, data_json) -> Optional[Dict]:
"""
Decide how to call Operators accroding to user request or WorkflowState
"""
raise NotImplementedError("Subclasses must implement operator_schedule")
Okay, we have now completed the abstract design of the scheduling object, Workflow.
Scheduler Design
In the new scheduler system, the instantiation and destruction of Workflow objects are non-negligible resource overheads. To minimize latency and reduce memory churn, we introduced a Workflow Pool mechanism to achieve efficient reuse of Workflow instances. We fully leverage the Pool abstraction provided by the underlying CGraph framework and apply it to the lifecycle management of Workflows. Its core mechanism is as follows:
- Categorized Pooling: The system maintains a dedicated and independent Workflow Pool for each type of Workflow. This ensures that requests are only distributed to Workflow instances with identical structures.
- On-Demand Acquisition and Dynamic Expansion: When a new request arrives, the scheduler’s execution logic follows the following strategy:
- Query (Pool Hit): First, the scheduler attempts to obtain an idle Workflow instance from the corresponding Workflow Pool. If successful, it immediately uses the instance to process the request, achieving zero-overhead reuse.
- Creation (Pool Miss): If there are no available instances in the pool, the scheduler dynamically creates a new Workflow. This new instance is immediately used to serve the current request. This strategy ensures that the system maintains good elasticity under high load.
- Automatic Return: Whether it is an instance obtained from the pool or a newly created instance, after completing the request processing, it will be automatically returned to its Workflow Pool, waiting for the next schedule.
🤔 The current version of the Scheduler implements its core responsibility, providing a stable and efficient scheduling base for the entire system. Its main features include:
1. Ability to accurately schedule corresponding Workflow instances for processing based on request type.
2. Built-in pooling mechanism based on Workflow type, which significantly reduces the cost of object creation and destruction in high-concurrency scenarios by reusing existing instances.
However, there are many areas where the Scheduler deserves optimization in the future, such as:
1. Workload-aware resource isolation: Not all Workflows consume resources equally. We will leverage the thread pool binding feature provided by CGraph to allocate dedicated computing resources to different types of Workflow Pools.
2. Production-grade capacity management and stability: Introduce configurable capacity limits for each Workflow Pool. In a production environment, unlimited resource pools are a potential risk. By setting a limit on the pool size, we can prevent the system from exhausting memory under extreme load, ensure the stability of the service.
Now we can get the overall architecture diagram of the entire project.
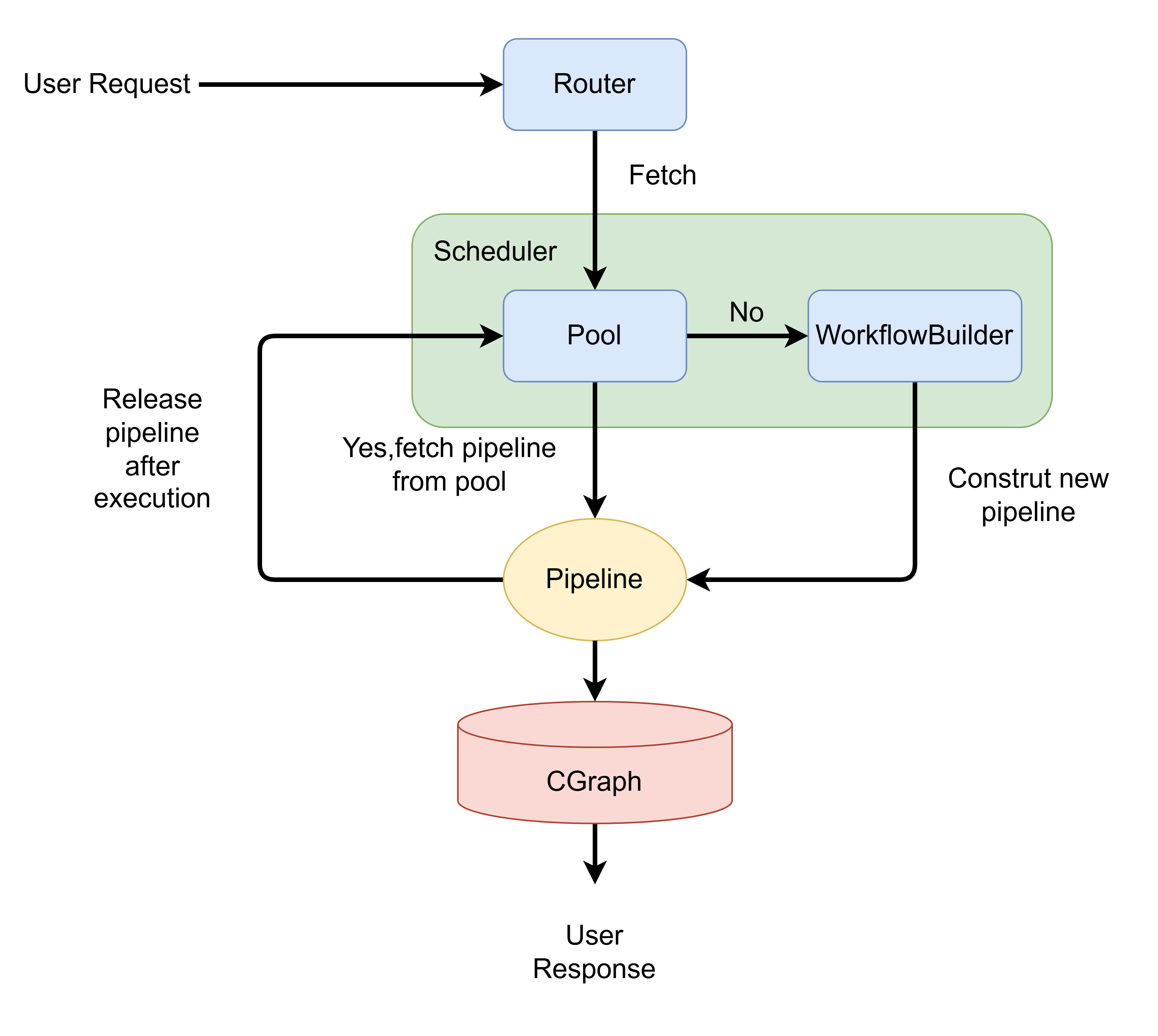
- After receiving a request, the Scheduler first queries the PipelinePool to check if there is a idle Pipeline of the corresponding type.
- When a user request arrives, the Http Router delegates the task to the core Scheduler based on the request type, requesting a Pipeline instance capable of handling that type of task.
- If there is a idle Pipeline in the PipelinePool, the Scheduler directly returns that Pipeline.
- If there is no idle Pipeline in the PipelinePool, it calls the corresponding type of WorkflowBuilder to construct a Pipeline of that type and returns it.
- When a user request arrives, the Http Router delegates the task to the core Scheduler based on the request type, requesting a Pipeline instance capable of handling that type of task.
- Whether the Pipeline is obtained from the pool or newly created, it immediately executes request processing and returns the Response to the user. After processing is complete, the Pipeline instance is not destroyed. Instead, it is automatically released and returned to the PipelinePool, and waits to be scheduled again after resetting its state.
Agentic GraphRAG: The Collision of Ideal and Reality
At the beginning of the project, we envisioned a fully “Agentic” GraphRAG. You would simply tell it your problem, and a powerful LLM, like a seasoned architect, would tailor the most efficient execution process (Workflow) for you from a collection of tools (Nodes/Operators).
However, there is always a gap between ideal and reality. We conducted in-depth research into similar projects such as chat2graph and verified the results through hands-on testing. The results showed that letting LLMs “create” a perfect and flawless execution plan out of thin air is much more difficult than we imagined. Even when using models like Gemini 2.5 Flash, it often struggles to understand complex instructions and accurately map them to a series of operations. On one hand, because the call chain of chat2graph can be very long, even if the single-step inference accuracy of large language models reaches as high as 95%, errors will accumulate progressively as the call chain extends, causing the overall task success rate to drop sharply. On the other hand, even without the call chain issue, the accuracy of having models automatically plan through prompting is still unsatisfactory at present. The era of relying entirely on large models for zero-shot workflow planning may not have fully arrived yet.
“Rome wasn’t built in a day.” So, we made a crucial decision: letting a large model build a workflow from scratch is challenging, but allowing a large model to “instantiate” a specific Workflow based on a Workflow template might be a feasible solution. We built a powerful, highly modular GraphRAG workflow, and the LLM’s task is to select the optimal configuration for the Workflow based on the characteristics of the audience’s user requests. This is the balance we found between Agentic GraphRAG and GraphRAG.
This shifts our core problem from “how to build from scratch” to:
How can we make the large model understand the optimal configuration of GraphRAG from a few words from the user?
For a concrete example:
👉🏼 Given a user request, how do we infer the optimal configuration from the user's request?
Specific example: The user's request is: Tell me the ontological views of the disciple of the philosopher who proposed "water is the origin of all things." So, what graph algorithm should be used for knowledge graph retrieval to make the results more accurate?
In summary, the LLM needs to stand on the two great mountains of natural language processing and graph databases to truly see the whole picture, but it is currently still at the foot of the mountain🤣. And this is the next high mountain we urgently need to cross.
Reflection
In this project, we used CGraph as the underlying graph scheduling framework. Its Graph API-based design successfully decoupled the definition of the Workflow from the specific implementation of each Node, giving the system good scalability.
However, we also noticed that this declarative API, while bringing flexibility, also introduces new programming complexity. As we use more and more of CGraph’s advanced features such as Condition and Region, the readability and maintainability of the code used to build Workflows begin to face challenges. This raises a core question for us: Is there a more intuitive and user-friendly interface that can both maintain the flexibility of the framework and reduce the cognitive burden when defining complex processes?
For a concrete example: when we need to define a main Workflow and a sub-Workflow as a subset of it, the current implementation tends to encapsulate the sub-Workflow as a GRegion and use Condition nodes to control its execution. This “merged” definition method is functionally feasible, but it undoubtedly increases the internal complexity and difficulty of understanding the Workflow. We envision that if the CGraph framework could natively provide Subgraph Composition capabilities, allowing developers to explicitly declare one Workflow as part of another Workflow, it might fundamentally simplify the implementation of such scenarios.
Despite the above challenges, the CGraph framework still played an important role in the project, significantly improving our engineering efficiency:
- Simplified Performance Diagnosis: The framework’s built-in Perf tool makes performance bottleneck localization easier, even if most of the time is ultimately focused on LLM calls, the tool still provides us with a clear performance view.
- Scheduling Logic Sink: The underlying Pooling abstraction mechanism enables us to seamlessly sink some scheduling logic to the C++ side, while the upper-layer business code does not need to care about its specific implementation.
Finally, I want to say that technical exploration is important, but the most valuable asset in this journey is the experience of working with excellent colleagues and the growth and insights gained from it. This is the real motivation that drives us forward.
Conclusion
In the reconstruction and innovation process of HugeGraph-AI, the introduction of AI tools has greatly improved development efficiency, but the final decisions and trade-offs still require rigorous thinking. Talk is not cheap, thinking is necessary. Whenever we encounter new technical problems, we can always propose multiple solutions, and the real test lies in how to weigh them (trade-off). The technical world is not black and white. Different architectural choices and program trade-offs often correspond to different target users and application scenarios. Our choice of CGraph is the best practice of this philosophy. It is not the first graph scheduling framework in the industry, but in the consideration of performance, flexibility and development costs, it provides us with the most balanced point that meets our current needs - on this road full of trade-offs, it is closest to us.
This also makes us more convinced that a product or technology is ultimately chosen, often not only because of the advanced nature of its philosophy, but also because it can provide the most pragmatic solution to a specific problem under complex real-world constraints.
The project has come to an end for now, and I sincerely thank every partner who fought alongside me! This experience is wonderful because of you.