This is the multi-page printable view of this section. Click here to print.
HugeGraph-AI
Agentic GraphRAG
项目背景
为了应对模型训练数据和现实生活中实际数据之间存在的时效性差异问题,RAG技术应运而生。RAG,顾名思义就是通过向外部数据源获取对应的数据(Retrieval),用于增强(Argument)大模型生成(Generation)回答质量的技术。
最早的RAG采用简单的Retrieval - Generation架构,我们拿到用户给出的问题,进行一定的预处理(关键词提取等等),得到预处理之后的问题,接着通过Embedding Model从海量资料中抓取相关的资料作为Prompt交给大模型用于增强模型回答的质量。
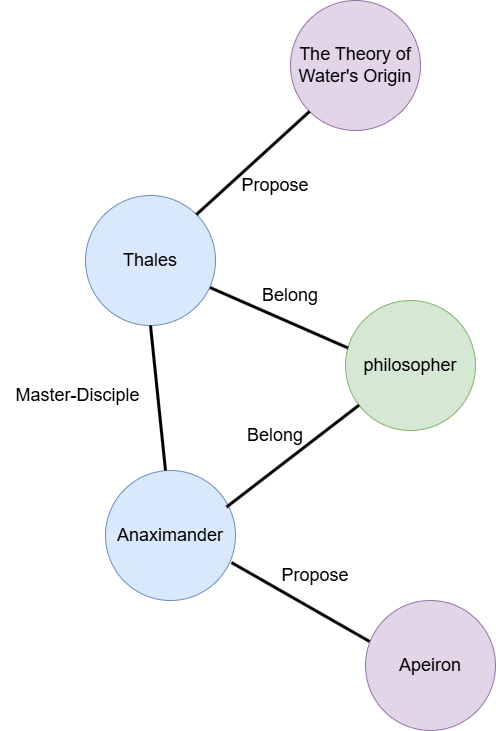
但是基于语义相似性匹配进行相关语料的抓取未必能够处理所有情况,因为能够用于增强回答质量的语料不一定和问题本身存在语义相似性。一个常见的例子就是:**告诉我“提出水是万物的本源”的哲学家的徒弟提出的本体论观点。**而我们的语料中并不直接存在这个问题的答案,语料库中可能提到:
- 泰勒斯提出水是万物的本源
- 泰勒斯的弟子有阿纳克西曼德
- 阿纳克西曼德将没有任何形式规定性的阿派朗认定为万物的本源
如果单纯从语义相似度匹配出发,我们大概率只能retrieval到第一个句子用于增强大模型的回答。但是缺失语料2和语料3的情况下,如果我们所使用的大模型训练语料中没有哲学相关知识,在缺失这些关键信息的情况下,大模型将无法正确回答这些问题,甚至会出现“幻觉”。
因此GraphRAG技术诞生了,常见的GraphRAG包含两个步骤:
- Offline: 我们需要离线对语料库进行图索引的构建(将非结构化语料转化为结构化数据存储到图数据库中)
- Online: 当GraphRAG系统接收到用户问题时,根据图数据库捕捉到的语料库中不同实体之间的关联关系,我们可以从图数据库中抓取到上面的三句话(具体图数据库索引可能如下图所示)
但是GraphRAG本身也存在几个问题:
- 如何构建Graph Index是一门学问,Graph Index会影响到模型回答质量。
- GraphRAG索引构建过程Token消耗巨大
- GraphRAG中存在各种各样的图算法,如何Retrieval效果最好呢?(配置空间过大)
本次项目主要针对第三个问题展开。我们希望借助大模型的泛化能力使其自动识别用户问题中的意图,然后选择合适配置(比如选择最合适的图算法)从图数据库中读取对应的数据用于增强大模型回答质量——也就是本次项目Agentic GraphRAG的目的所在。
现有 Workflow:优雅的解耦,未竟的并行
现在的HugeGraph-AI项目中存在两个核心抽象:
- Operator:表示「原子式的操作单元」,负责完成一个明确的子任务,如向量索引构建、向量相似度查询、图数据相关操作等等
- Workflow:由Operator作为节点构成的链状执行流。项目中预定义好的Workflow和项目Demo用例一一对应(如GraphRAG, Vector-Similarity-Based RAG)
由于Operator的实现需要遵循下面的接口:
class Operator:
@abstractmethod
def run(context: dict[str, Any]) -> dict[str,Any]:
return {}
Operator在实际运行时接受字典类型的context对象作为输入,返回的对象也是一个字典,可以用来作为下一个Operator的输入,这样的设计有一个很高明的地方——他将不同的Operator之间的依赖关系和Operator本身的具体实现解耦了,每个Operator是一个相对独立的存在,如果Operator A需要依赖Operator B的输出,那么只需要检查context对象中是否存有Operator B的输出即可。这是一种低耦合的设计。好处是我们能很方便地将不同的Operator自由组合。根据不同的用户输入组装(配置)合适Workflow Serving用户请求,那不正是我们在项目背景中提到的Agentic GraphRAG的目的所在吗?
👉🏼 理论上现有设计已经可以正常过渡到Agentic GraphRAG,但是现有设计存在诸多悬而未决的问题:
1. 现有调度器仅仅支持链状Workflow,缺失了可能存在的并行空间
2. 现有调度器无法复用被反复使用到的Workflow
打破链式束缚,拥抱全新架构
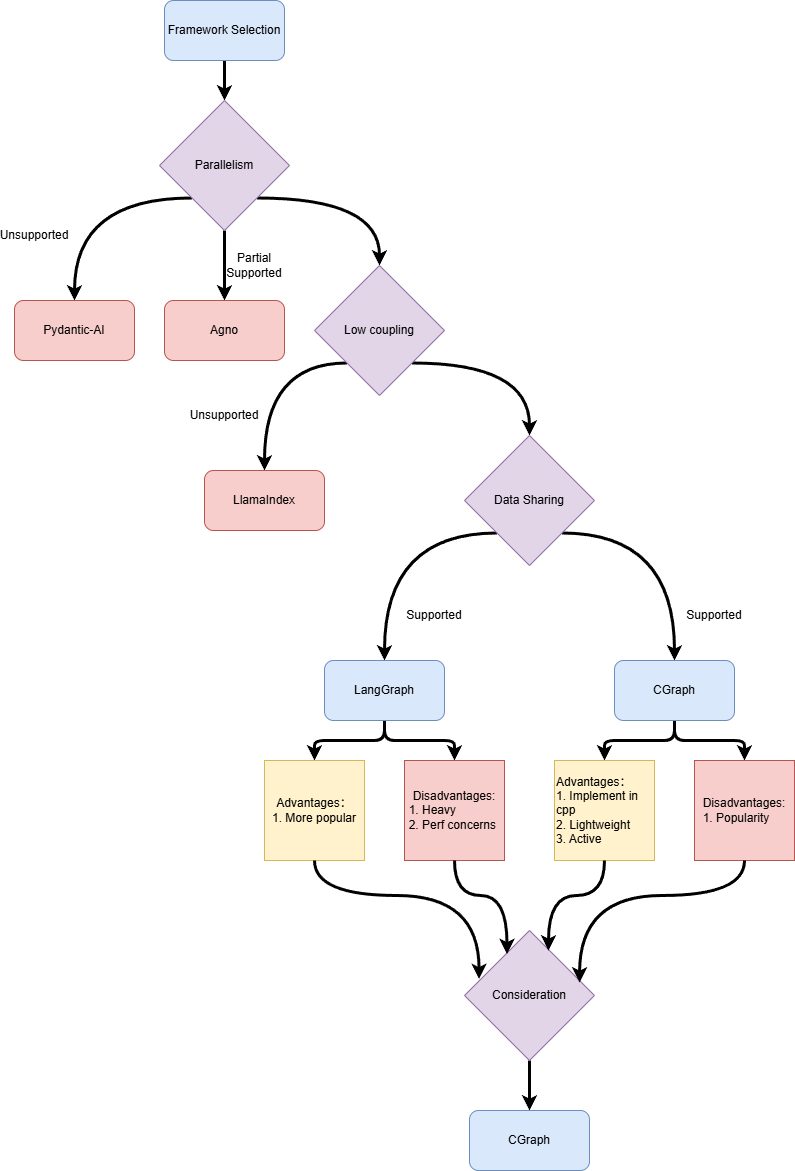
之前的调度器给我们的启发是Operator粒度的解耦是一个不错的设计理念,但是调度器本身能力有限,限制了Workflow的能力。因此我们计划替换项目中的调度器!经过对几种不同的Workflow编排框架进行简单的调研之后,我们认为下面几个特性是我们筛选调度器的标准。(下面我们统一将框架编排对象称为Workflow,Workflow由一系列Task组成)
- 并行性:Workflow中没有数据依赖关系的不同Task能否支持自动并行
- 低耦合:Task的具体实现应该和Workflow本身解耦(用人话:一种Task可以作为多种不同的Workflow的节点,同时Task的实现是否需要包含与其他Task依赖关系约束?)
- 数据共享:由于我们希望不同的Task之间的依赖关系解耦,那我们就需要Workflow粒度的数据共享机制用来在不同的Task共享数据(用于参数传递)
- 提供Python接口
AI框架大乱斗
我们首先将目光放到了现在炙手可热的AI Workflow调度框架。围绕前面提到的几个维度,我们分别调研了下面几种不同的Workflow编排框架——LlamaIndex,Agno,Pydantic-Ai,LangGraph。
LlamaIndex
对于LlamaIndex,我们用一个常见的例子说明LlamaIndex这个框架的设计理念。
from workflows import Workflow, Context, step
from workflows.events import StartEvent, StopEvent, Event
class StepEvent(Event):
message: str
class MyWorkflow(Workflow):
@step
async def step_one(self, ctx: Context, ev: StartEvent) -> StepEvent:
current_count = await ctx.store.get("count", default=0)
current_count += 1
await ctx.store.set("count", current_count)
print("step one called once")
return StepEvent("launch step two")
@step
async def step_two(self, ctx: Context, ev: StepEvent) -> StopEvent:
print("step two called once")
return StopEvent()
从上面这个简单的例子我们可以看到很多问题。首先明确一个观念:Workflow由两个元素构成:Task,Task之间的依赖关系。只要这两个元素确定之后一个Workflow就确定下来了。我们可以看到LlamaIndex中每个Task(对应代码中用@step注解的函数)的实现和Workflow存在依赖关系。因为每个Task的实现都需要传入Event对象作为参数,但是Event参数其实就是对Task之间依赖关系的一种限定。所以LlamaIndex不具备低耦合的特点。同时我们也发现Task作为Workflow类成员函数本身就违背了我们前面提到的Task需要能够在多种不同Workflow中使用的诉求。但是经过调研,LlamaIndex的数据共享和并行特性支持还算不错。只不过从基于事件驱动模型构建的编程接口在保证了接口易用性的同时也牺牲了编程的灵活性。
Agno
同样还是从例子入手
from agno.workflow import Router, Step, Workflow
def route_by_topic(step_input) -> List[Step]:
topic = step_input.input.lower()
if "tech" in topic:
return [Step(name="Tech Research", agent=tech_expert)]
elif "business" in topic:
return [Step(name="Business Research", agent=biz_expert)]
else:
return [Step(name="General Research", agent=generalist)]
workflow = Workflow(
name="Expert Routing",
steps=[
Router(
name="Topic Router",
selector=route_by_topic,
choices=[tech_step, business_step, general_step]
),
Step(name="Synthesis", agent=synthesizer),
]
)
workflow.print_response("Latest developments in artificial intelligence and machine learning", markdown=True)
从这个例子我们可以看到Workflow本身和Task之间的绑定关系是通过指定steps参数确定的。理论上来说定义好一种Task之后我们可以将其用于不同的Workflow中,Agno的设计符合我们的低耦合标准。
但是数据共享和任务并行方面的支持就存在一定的限制。
首先是任务并行,例子如下:
workflow = Workflow(
name="Parallel Research Pipeline",
steps=[
Parallel(
Step(name="HackerNews Research", agent=hn_researcher),
Step(name="Web Research", agent=web_researcher),
Step(name="Academic Research", agent=academic_researcher),
name="Research Step"
),
Step(name="Synthesis", agent=synthesizer), # Combines the results and produces a report
]
)
Agno专门设计了并行接口,我们需要在静态编译时(Python哪有编译时?应该叫写代码的时候哈哈😀)明确哪些任务可以并行。但是Agentic GraphRAG最终构造的Workflow有可能是在运行时由模型规划出来的,是动态运行时明确的,出于这样的考量,我们认为Agno的并行特性并不符合我们的要求
接下来是数据共享,Agno框架中支持三种不同的Task:
- Agent
- 由多个Agent构成的Team
- Pure Function
我们检查了调研时最新版本的Agno源代码,发现Agno支持的状态共享仅限于Agent和Team。那么对于那些适合用Pure Function实现的Task,我们就需要额外支持数据共享的机制。因此Agno的数据共享机制也不符合我们的要求。
Pydantic-Ai
我们从官方文档中就看到

Pydantic-Ai框架竟然不支持Task粒度的自动并行。
和LlamaIndex框架类似采用事件驱动的编程模型,因此Workflow和Task之间不算是完全解耦,但是值得注意的时Pydantic-Ai的Task是可以用到多个不同的Workflow的。
LangGraph
最后的最后,终于还是遇到了LangGraph,之前一直没有调研LangGraph的原因是因为由团队伙伴认为LangGraph本身太重了。在上一个版本中,即使只是使用LangGraph的部分功能(调度),也需要引入LangGraph的完整依赖,引入LangGraph可能会让项目变“重”。时不时在其他开源项目中看到“xxx比LangGraph快xxx倍”诸如此类的字眼也确实影响到我们的决策判断。所以直到此时此刻才把它提上调研日程。
我们还是来看看LangGraph的例子
class State(TypedDict):
topic: str
joke: str
improved_joke: str
# Nodes
def generate_joke(state: State):
"""First LLM call to generate initial joke"""
msg = llm.invoke(f"Write a short joke about {state['topic']}")
return {"joke": msg.content}
def check_punchline(state: State):
"""Gate function to check if the joke has a punchline"""
# Simple check - does the joke contain "?" or "!"
if "?" in state["joke"] or "!" in state["joke"]:
return "Pass"
return "Fail"
def improve_joke(state: State):
"""Second LLM call to improve the joke"""
msg = llm.invoke(f"Make this joke funnier by adding wordplay: {state['joke']}")
return {"improved_joke": msg.content}
# Build workflow
workflow = StateGraph(State)
# Add nodes
workflow.add_node("generate_joke", generate_joke)
workflow.add_node("improve_joke", improve_joke)
# Add edges to connect nodes
workflow.add_edge(START, "generate_joke")
workflow.add_conditional_edges(
"generate_joke", check_punchline, {"Fail": "improve_joke", "Pass": END}
)
workflow.add_edge("improve_joke", END)
# Compile
chain = workflow.compile()
# Invoke
state = chain.invoke({"topic": "cats"}
这是一个我简化后的官方文档中的例子,我们可以看到基于GraphAPI的LangGraph通过调用workflow.add_edge指定Workflow的依赖关系,将Workflow和Task解耦。同时支持全局State作为Workflow的状态进行Task之间的数据共享。根据官方文档的说法,LangGraph是支持Task自动并行执行的。我们总算是找到了符合所有要求的Workflow编排框架了!
总结
| 并行性 | 低耦合 | 数据共享 | Python Interface | |
|---|---|---|---|---|
| LlamaIndex | 支持 | 不支持 | 支持 | 支持 |
| Agno | 支持但不符合要求 | 支持 | 支持但不符合要求 | 支持 |
| Pydantic-Ai | 不支持 | 不支持 | 支持 | 支持 |
| LangGraph | 支持 | 支持 | 支持 | 支持 |
CGraph —— Graph with Python Interaface Implement in C++
正当我们将目光聚焦于 LangGraph 时,团队伙伴提到了一个新的方案——CGraph,这是由开源创作者Chunel使用C++开发的图调度框架,对标SOTA任务调度框架——taskflow。CGraph,学名Color Graph,虽然是C++项目,但是它很贴心地提供了Python接口。深入了解后,我们发现 CGraph 的设计理念与我们不谋而合:和LangGraph一样,CGraph基于图的声明式 API,完美支持我们所需的并行化、低耦合和数据共享需求。
如果说“C++ 站在编程语言鄙视链顶端”是个有趣的玩笑,那它背后反映的其实是程序员对底层性能的极致追求。除去这个“先天”优势, CGraph 相比 LangGraph 最大的不同,在于它的纯粹——它不构建庞大的生态,只专注于将“任务调度”这一件事做到极致。
然而,真正让我们下定决心的,是这个项目的“心跳”。我们联系上了作者 Chunel,感受到了 CGraph 作为一个项目旺盛的生命力。在开源世界里,活力即未来。一个持续进化、积极响应的社区,远比一个功能冻结的庞然大物更值得信赖。
我们相信,优秀的技术选型,不仅是功能的匹配,更是对项目未来潜力的认同。(欢迎一同见证它的成长:https://github.com/ChunelFeng/CGraph)
架构设计
起初,我们的目标很纯粹:基于CGraph,打造一个属于我们自己的调度器。然而深入思考之后,我们发现:一个好的调度器,源于对调度对象的深刻理解(是时候拷问自己了🤣)。就像CPU调度器和GPU调度器由于其调度对象以及生态定位的不同也会采取不同调度策略。
抽象设计是否合理?
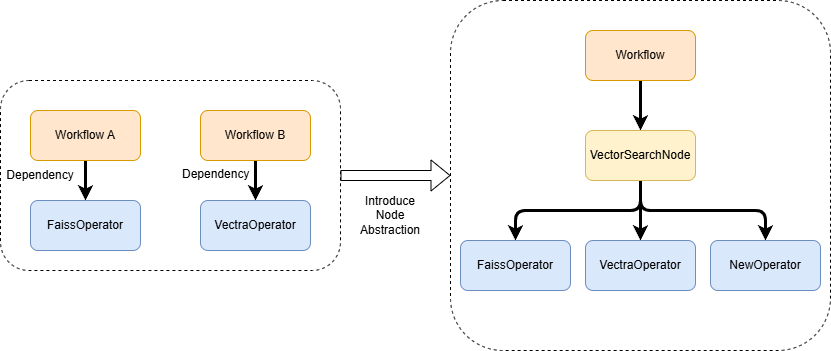
所以我们开始考察那个被我们称之为Workflow的抽象,在上一个设计中,它是由一系列Operator组成的链表。这样的设计否定了并行的可能,那么如果我们说Workflow是一系列Operator组成的DAG图是否合理呢?
直观来说这样的定义很合理,但是实际实践下来,我们发现Workflow中的每个节点(后面我们称之为Node)和Operator一一对应却不是一个好的设计,因为我们需要在不同的请求之间复用Workflow(这样可以节省Workflow构造过程中不可避免的资源创建以及一些DAG图校验带来的性能开销)。
举个例子,向量相似度查询是一个很常见的RAG流程,但是根据不同底层向量数据库暴露的接口不同,我们可能需要提供FaissVectorSearch、VectraVectorSearch等多种目的相同但是具体实现不同的Operator。如果我们将Operator和Workflow中的Node等同,那么我们对于Workflow的复用机会将大大减少,因为使用Faiss进行搜索和使用Vectra进行搜索的Workflow将会是不同的Workflow,但是如果我们将功能类似的向量索引Operator都封装到VectorSearchNode中,那么我们是不是能够有更多的Workflow复用机会呢?在VectorSearchNode的具体实现中我们只需要根据需要调用对应的Operator即可。通过在Workflow和Operator中间加一层的方式,有下面三个好处:
- 新增新的Operator,我们只需要修改对应Node的具体实现即可,不需要修改上层Workflow的逻辑。Operator对Node负责,Node对Workflow负责,很好地实现了职能分离。
- 拥有更多的Workflow复用的机会。
- 通过引入新的Node抽象,我们在重构的过程中不需要修改底层Operator的实现,减轻了重构过程中的心智负担。
既然我们希望跨请求复用同类Workflow,那么我们就需要保证Workflow本身是无状态的,因为如果复用的Workflow还带着上一个请求的状态,用户就可能得到发生意料之外的结果。而Workflow的状态可以分为两种:
- 用户输入的状态(我们称之为WorkflowInput):这部分由用户的请求构成
- Workflow的中间状态(我们称之为WorkflowState):由Workflow中各节点(Node)在执行过程中产生的临时数据、计算结果等。
我们需要保证Workflow执行的过程中这两部分状态是干净的。但是这两种不同的状态使用时机又不同,这也就决定了他们截然不同的生命周期:
- WorkflowInput在Workflow执行前被构建和注入,在Workflow执行结束后其使命便已完成,应被销毁。
- WorkflowState在Workflow执行前必须为空或处于初始状态(pristine),在执行过程中被动态读写。
我们利用 CGraph 框架提供的 GParam(全局参数)抽象来实现精细化的状态隔离:
- 分离上下文: 我们为WorkflowInput和WorkflowState定义两个独立的
GParam上下文。 - 注入生命周期钩子: 我们在工作流的执行逻辑外层进行封装,实现以下自动化清理机制:
- 执行前 (Pre-execution Hook): 自动重置(reset)WorkflowState上下文,确保每次执行都在一个“干净的画布”上开始。
- 执行后 (Post-execution Hook): 自动清理(clear)WorkflowInput上下文,防止其数据泄露到下一次调用。
这样我们可以保证每次Workflow执行时这两种状态中都只包含本次请求的状态。由于WorkflowInput状态在Workflow执行结束就被重置了,我们只能从WorkflowState中有选择性地选择部分数据返回给用户。因此我们得到了一个Flow抽象应该实现的接口。

class BaseFlow(ABC):
"""
Base class for flows, defines three interface methods: prepare, build_flow, and post_deal.
"""
@abstractmethod
def prepare(self, prepared_input: WkFlowInput, **kwargs):
"""
根据用户请求初始化Workflow输入状态(WkFlowInput)
"""
@abstractmethod
def build_flow(self, **kwargs) -> GPipeline:
"""
用来构建可以运行在CGraph之上的Workflow对象
"""
@abstractmethod
def post_deal(self, **kwargs):
"""
从中间状态(WkFlowState)中组装返回给用户的Response
"""
那么回到Node抽象本身,Node本身是对某个功能的抽象,其底层可能对应着多种不同的抽象。我们大致需要考虑下面几个问题:
- 如何将Node层和Operator层尽可能解耦
- Node本身是可以并行的,而Workflow内部存在共享数据,那么如何解决可能存在的并发问题
我们知道Operator的run方法输入输出都是字典(见上面现有Workflow架构的介绍),为了使得Node层和Operator层尽可能地解耦,我们希望Node层也按照相同的方式调用Operator,因此我们需要为WorkflowState实现一个json序列化方法,在调用Operator前将当前Workflow中间状态转化为字典格式然后交给Operator,然后将Operator执行结果重新反序列化为WorkflowState。为了解决并发访问带来的数据竞争问题,我们可以采用MVCC的并发控制方法,保证Operator操作的是多个不同的副本,得到Operator的返回结果之后,在有并发安全的锁保护的情况下将返回的结果同步到WorkflowState中。因此我们可以得到Node的抽象大致如下:
class BaseNode(GNode):
// Workflow中间状态
context: Optional[WkFlowState] = None
// Workflow输入状态
wk_input: Optional[WkFlowInput] = None
def init(self):
// 从Pipeline中获取对应状态
return init_context(self)
def node_init(self):
"""
重写这个方法定制化Node初始化逻辑
"""
return CStatus()
def run(self):
"""
Main logic for node execution, can be overridden by subclasses.
Returns a CStatus object indicating whether execution succeeded.
"""
sts = self.node_init()
if sts.isErr():
return sts
if self.context is None:
return CStatus(-1, "Context not initialized")
self.context.lock()
try:
data_json = self.context.to_json()
finally:
self.context.unlock()
res = self.operator_schedule(data_json)
self.context.lock()
try:
if res is not None and isinstance(res, dict):
self.context.assign_from_json(res)
elif res is not None:
log.warning("operator_schedule returned non-dict type: %s", type(res))
finally:
self.context.unlock()
return CStatus()
def operator_schedule(self, data_json) -> Optional[Dict]:
"""
根据用户请求或者Workflow状态决定调用哪些Operator
"""
raise NotImplementedError("Subclasses must implement operator_schedule")
至此,我们完成了调度对象Workflow的抽象设计。
调度器设计
在新的调度器体系中,Workflow 对象的实例化与销毁是一项不可忽视的资源开销。为了最大限度地降低延迟、减少内存抖动,我们引入了 Workflow Pool 机制,旨在实现 Workflow 实例的高效复用。 我们充分利用了 CGraph 框架底层提供的 Pool 抽象,并将其应用于 Workflow 的生命周期管理。其核心机制如下:
- 分类池化: 系统为每种类型的 Workflow 维护一个专属的、独立的 Workflow Pool。这确保了请求只会被分发给结构完全相同的 Workflow 实例。
- 按需获取与动态扩容: 当一个新请求到达时,调度器的执行逻辑遵循以下策略:
- 查询(Pool Hit): 首先,调度器会尝试从对应类型的 Workflow Pool 中获取一个空闲的 Workflow 实例。如果成功,则立即使用该实例处理请求,实现了零开销复用。
- 创建(Pool Miss): 如果池中无可用实例,调度器将动态创建一个新的 Workflow。这个新实例会立即用于服务当前请求。这种策略保证了系统在高负载下依然具备良好的弹性。
- 自动归还: 无论是从池中获取的实例还是新创建的实例,在完成请求处理后,都将被自动归还到其所属的 Workflow Pool 中,等待下一次调度。
🤔 当前版本的 Scheduler 实现了其最核心的职责,为整个系统提供了一个稳定且高效的调度基座。其主要特性包括:
1. 能够根据请求类型,准确地调度对应的 Workflow 实例进行处理。
2. 内置了基于 Workflow 类型的池化(Pooling)机制,通过复用已有实例,显著降低了高并发场景下的对象创建与销毁开销。
但是在未来,Scheduler值得优化的地方还有很多,比如:
1. 工作负载感知的资源隔离:并非所有 Workflow 的资源消耗都是均等的。我们将利用 CGraph 提供的线程池绑定功能,为不同类型的 Workflow Pool 分配专属的计算资源。
2. 生产级容量管理与稳定性:为每个 Workflow Pool 引入可配置的容量上限。在生产环境中,无限制的资源池是潜在的风险点。通过设置池大小的上限,我们可以防止系统在极端负载下耗尽内存,确保服务的稳定性。
现在我们可以得到整个项目的整体架构图
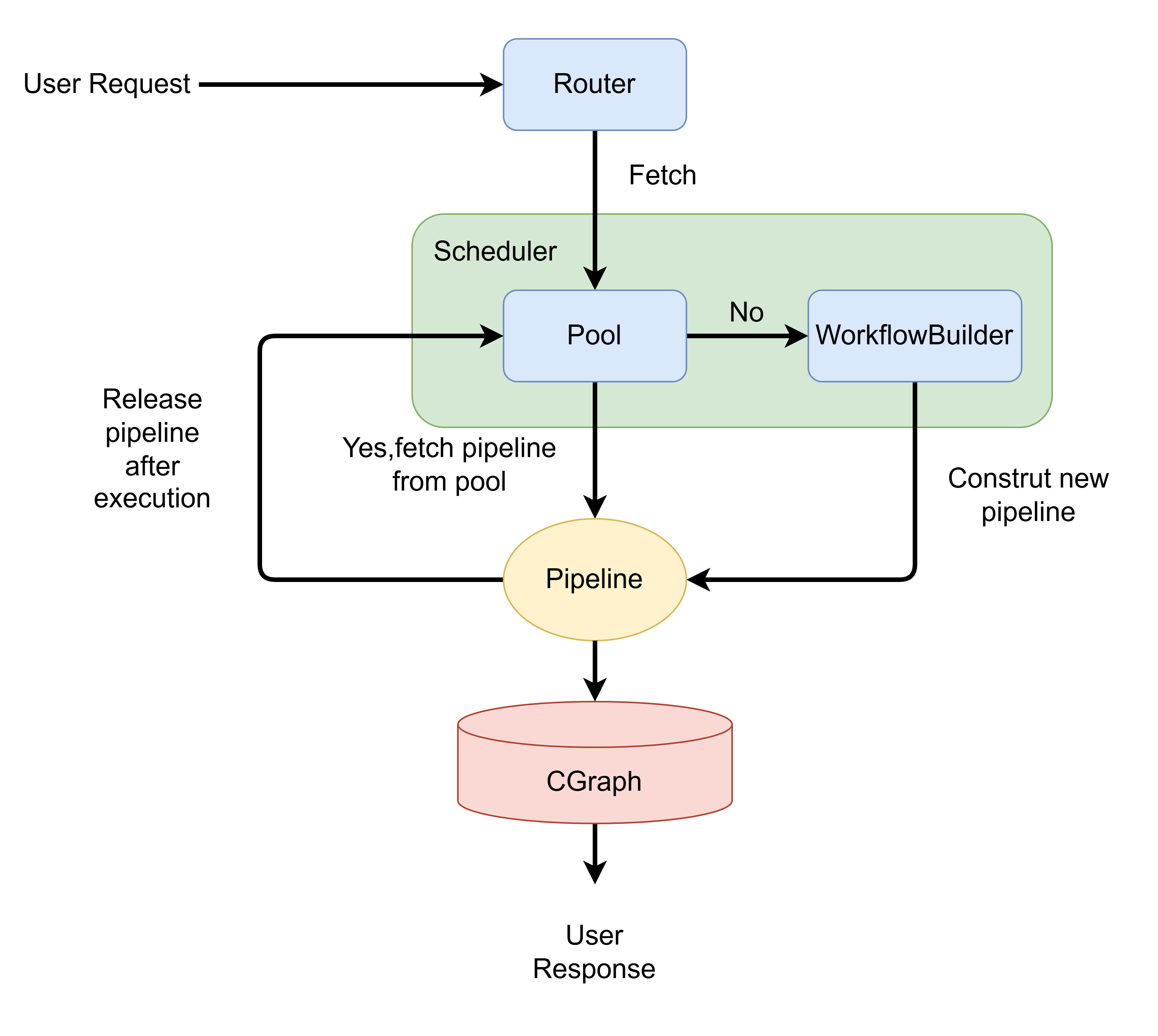
- Scheduler收到请求后,首先向PipelinePool查询是否存在对应类型的空闲Pipeline
- 当用户请求到来时,Http Router根据请求的类型将任务委托给核心的Scheduler,请求一个能够处理该类型任务的Pipeline实例。
- 若PipelinePool中存在空闲Pipeline,则Scheduler直接返回该Pipeline
- 若PipelinePool中不存在空闲Pipeline,则调用对应类型的WorkflowBuilder构建该类型的Pipeline并返回
- 无论Pipeline是从池中获取的还是新创建的,它都会立即执行请求处理,并将Response返回给用户。处理完成后,该Pipeline实例并不会被销毁。相反,它会被自动释放并归还到PipelinePool中,状态重置后等待下一次被调度。
Agentic GraphRAG: 理想与现实的碰撞
项目之初,我们畅想一个完全“Agentic”的 GraphRAG。你只需告诉它你的问题,一个强大的 LLM 就能像一位资深架构师,从一堆工具(Nodes/Operators)中为你量身定制一套最高效的执行流程(Workflow)。 但理想与现实之间总有距离。我们深入调研了 chat2graph 等类似项目,并实际动手检验效果。结果发现,让 LLM 凭空“创造”一个完美的、无懈可击的执行计划,比我们想象的要难得多。即使是使用 Gemini 2.5 Flash 这样的模型,它在理解复杂指令并将其精确映射到一系列操作时,也时常力不从心。一方面,因为chat2graph的调用链可能会很长,即便大模型推理单步准确率高达95%,但随着调用链路的延长,误差会逐级累积,导致整体任务的成功率急剧下降。另一方面,即使调用链的问题不存在,通过prompt的方式让模型自动规划的准确度目前仍然不能使人满意。完全依赖大模型进行零样本工作流规划的时代,或许还未完全到来。 “一口吃不成胖子”,于是我们做出了一个关键决策:让大模型从零开始构建工作流存在阻碍,但是如果让大模型基于Workflow模板“实例化”具体的Workflow或许是一种可行的方案。我们构建了一个功能强大、高度模块化的 GraphRAG 工作流,而 LLM 的任务,就是根据观众用户请求的特点,为Workflow选择最优配置。这是我们在Agentic GraphRAG和GraphRAG之间找到的一个平衡点。 这让我们的核心问题发生了转变,不再是“如何从零构建”,而是:
我们如何从用户的寥寥数语中,让大模型知道什么是GraphRAG的最优配置?
举个具体的例子:
👉🏼 给定一个用户请求,我们怎么通过用户的请求推断出最优配置呢?
具体例子:用户的请求是:告诉我“提出水是万物的本源”的哲学家的徒弟提出的本体论观点。那么采用什么图算法进行知识图谱检索会使得结果更精确呢?
综上所述,LLM需要站在自然语言处理和图数据库这两座大山上才能真正窥见问题全貌,而他现在还处于山脚🤣。而这,就是我们下一座亟待翻越的高山。
反思
在本项目中,我们采用了 CGraph 作为底层的图调度框架。其基于 Graph API 的设计,成功地将 Workflow 的定义与各个 Node 的具体实现解耦,赋予了系统良好的扩展性。
然而,我们也注意到,这种声明式 API 在带来灵活性的同时,也引入了新的编程复杂度。随着我们越来越多地使用 Condition、Region 等 CGraph 的高级特性,用于构建 Workflow 的代码可读性和可维护性开始面临挑战。这引发了我们的一个核心思考:是否存在一种更为直观和用户友好的接口,既能保持框架的灵活性,又能降低定义复杂流程时的认知负担?
举一个具体的例子:当我们需要定义一个主 Workflow 和一个作为其子集的子 Workflow 时,目前的实现方式倾向于将子 Workflow 封装为 GRegion,并利用 Condition 节点来控制其执行。这种“合并”式的定义方式虽然功能上可行,但无疑增加了 Workflow 的内在复杂度和理解难度。我们设想,如果 CGraph 框架能原生提供子图组合 (Subgraph Composition) 的能力,允许开发者将一个 Workflow 显式声明为另一个 Workflow 的一部分,或许能从根本上简化这类场景的实现。
尽管存在上述挑战,CGraph 框架在项目中依然发挥了重要作用,显著提升了我们的工程效率:
- 性能诊断简化:框架自带的 Perf 工具使性能瓶颈定位更为便捷,即使大部分耗时最终集中在 LLM 调用上,该工具依然为我们提供了清晰的性能视图。
- 调度逻辑下沉:底层的 Pooling 抽象机制,使我们能够将部分调度逻辑无缝下沉至 C++ 侧,而上层业务代码无需关心其具体实现。
最后,我想说,技术上的探索固然重要,但这段旅程中最宝贵的财富,是与优秀的同行者共事的经历以及从中获得的成长与感悟。这才是推动我们不断前行的真正动力。
结语
在 HugeGraph-AI 的重构与革新过程中,AI工具的引入大大提升了开发效率,但最终的决策和取舍,仍然需要严谨的思考,Talk is not cheap, thinking is necessary。每当遇到新的技术难题,我们总能提出多种解决方案,而真正的考验在于如何在它们之间进行权衡 (trade-off)。技术世界并非非黑即白,不同的架构选择、方案取舍,往往对应着不同的目标用户与应用场景。我们对 CGraph 的选择,正是这一理念的最佳实践。它并非业界首个图调度框架,但在性能、灵活性与开发成本等诸多维度的考量中,它为我们提供了最契合当前需求的平衡点——在这条充满权衡的道路上,它离我们最近。
这也让我们更加坚信:一个产品或技术最终被选择,往往不只因其理念的先进,更在于它能否在复杂的现实约束下,为特定问题提供最务实的解法。
项目暂告一段落,由衷感谢每一位并肩作战的伙伴!这段经历因你们而精彩。