HugeGraph Design Concepts
1. Property Graph
常见的图数据表示模型有两种,分别是RDF(Resource Description Framework)模型和属性图(Property Graph)模型。 RDF和Property Graph都是最基础、最有名的图表示模式,都能够表示各种图的实体关系建模。 RDF是W3C标准,而Property Graph是工业标准,受到广大图数据库厂商的广泛支持。HugeGraph目前采用Property Graph。
HugeGraph对应的存储概念模型也是参考Property Graph而设计的,具体示例详见下图:(此图为旧版设计已过时,请忽略它,后续更新)
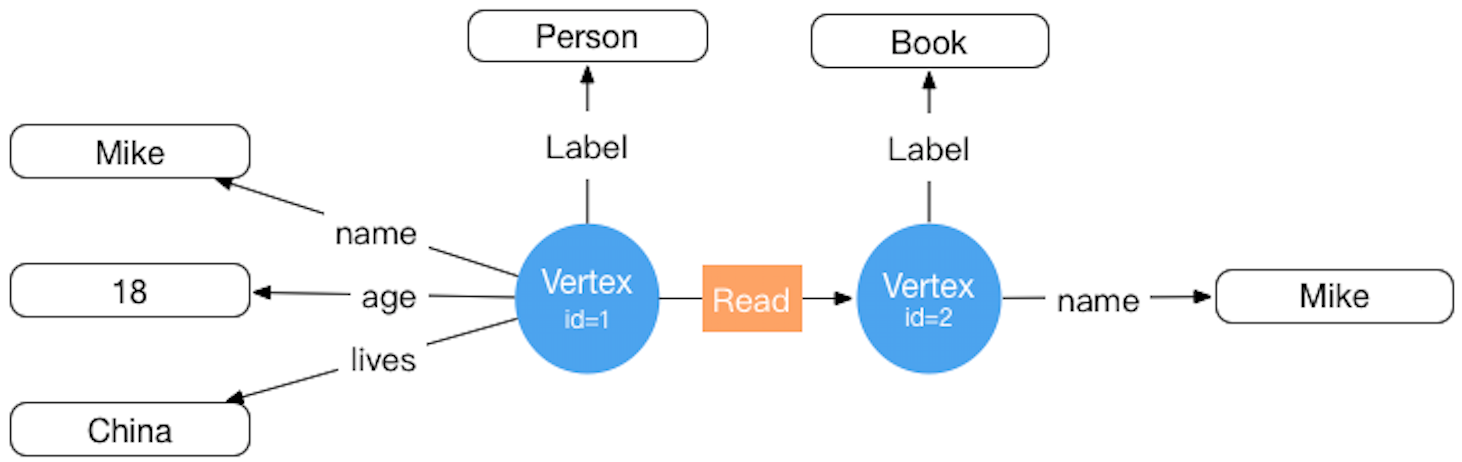
在HugeGraph内部,每个顶点 / 边由唯一的 VertexId / EdgeId 标识,属性存储在对应点 / 边内部。而顶点与顶点之间的关系 / 映射则是通过边来存储的。
顶点属性值通过边指针方式存储时,如果要更新一个顶点特定的属性值直接通过覆盖写入即可,其弊端是冗余存储了VertexId; 如果要更新关系的属性需要通过read-and-modify方式,先读取所有属性,修改部分属性,然后再写入存储系统,更新效率较低。 从经验来看顶点属性的修改需求较多,而边的属性修改需求较少,例如PageRank和Graph Cluster等计算都需要频繁修改顶点的属性值。
2. 图分区方案
对于分布式图数据库而言,图的分区存储方式有两种:分别是边分割存储(Edge Cut)和点分割存储(Vertex Cut),如下图所示。 使用Edge Cut方式存储图时,任何一个顶点只会出现在一台机器上,而边可能分布在不同机器上,这种存储方式有可能导致边多次存储。 使用Vertex Cut方式存储图时,任何一条边只会出现在一台机器上,而每相同的一个点可能分布到不同机器上,这种存储方式可能会导致顶点多次存储。
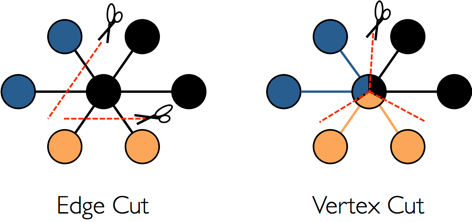
采用EdgeCut分区方案可以支持高性能的插入和更新操作,而VertexCut分区方案更适合静态图查询分析,因此EdgeCut适合OLTP图查询,VertexCut更适合OLAP的图查询。 HugeGraph目前采用EdgeCut的分区方案。
3. VertexId 策略
HugeGraph的Vertex支持三种ID策略,在同一个图数据库中不同的VertexLabel可以使用不同的Id策略,目前HugeGraph支持的Id策略分别是:
- 自动生成(AUTOMATIC):使用Snowflake算法自动生成全局唯一Id,Long类型;
- 主键(PRIMARY_KEY):通过VertexLabel+PrimaryKeyValues生成Id,String类型;
- 自定义(CUSTOMIZE_STRING|CUSTOMIZE_NUMBER):用户自定义Id,分为String和Long类型两种,需自己保证Id的唯一性;
默认的Id策略是AUTOMATIC,如果用户调用primaryKeys()方法并设置了正确的PrimaryKeys,则自动启用PRIMARY_KEY策略。 启用PRIMARY_KEY策略后HugeGraph能根据PrimaryKeys实现数据去重。
- AUTOMATIC ID策略
schema.vertexLabel("person")
.useAutomaticId()
.properties("name", "age", "city")
.create();
graph.addVertex(T.label, "person","name", "marko", "age", 18, "city", "Beijing");
- PRIMARY_KEY ID策略
schema.vertexLabel("person")
.usePrimaryKeyId()
.properties("name", "age", "city")
.primaryKeys("name", "age")
.create();
graph.addVertex(T.label, "person","name", "marko", "age", 18, "city", "Beijing");
- CUSTOMIZE_STRING ID策略
schema.vertexLabel("person")
.useCustomizeStringId()
.properties("name", "age", "city")
.create();
graph.addVertex(T.label, "person", T.id, "123456", "name", "marko","age", 18, "city", "Beijing");
- CUSTOMIZE_NUMBER ID策略
schema.vertexLabel("person")
.useCustomizeNumberId()
.properties("name", "age", "city")
.create();
graph.addVertex(T.label, "person", T.id, 123456, "name", "marko","age", 18, "city", "Beijing");
如果用户需要Vertex去重,有三种方案分别是:
- 采用PRIMARY_KEY策略,自动覆盖,适合大数据量批量插入,用户无法知道是否发生了覆盖行为
- 采用AUTOMATIC策略,read-and-modify,适合小数据量插入,用户可以明确知道是否发生覆盖
- 采用CUSTOMIZE_STRING或CUSTOMIZE_NUMBER策略,用户自己保证唯一
4. EdgeId 策略
HugeGraph的EdgeId是由srcVertexId+edgeLabel+sortKey+tgtVertexId四部分组合而成。其中sortKey是HugeGraph的一个重要概念。
在Edge中加入sortKey作为Edge的唯一标识的原因有两个:
- 如果两个顶点之间存在多条相同Label的边可通过
sortKey来区分 - 对于SuperNode的节点,可以通过
sortKey来排序截断。
由于EdgeId是由srcVertexId+edgeLabel+sortKey+tgtVertexId四部分组合,多次插入相同的Edge时HugeGraph会自动覆盖以实现去重。
需要注意的是如果批量插入模式下Edge的属性也将会覆盖。
另外由于HugeGraph的EdgeId采用自动去重策略,对于self-loop(一个顶点存在一条指向自身的边)的情况下HugeGraph认为仅有一条边,对于采用AUTOMATIC策略的图数据库(例如TitianDB )则会认为该图存在两条边。
HugeGraph的边仅支持有向边,无向边可以创建Out和In两条边来实现。
5. HugeGraph transaction overview
TinkerPop事务概述
TinkerPop transaction事务是指对数据库执行操作的工作单元,一个事务内的一组操作要么执行成功,要么全部失败。 详细介绍请参考TinkerPop官方文档:http://tinkerpop.apache.org/docs/current/reference/#transactions
TinkerPop事务操作接口
- open 打开事务
- commit 提交事务
- rollback 回滚事务
- close 关闭事务
TinkerPop事务规范
- 事务必须显式提交后才可生效(未提交时修改操作只有本事务内查询可看到)
- 事务必须打开之后才可提交或回滚
- 如果事务设置自动打开则无需显式打开(默认方式),如果设置手动打开则必须显式打开
- 可设置事务关闭时:自动提交、自动回滚(默认方式)、手动(禁止显式关闭)等3种模式
- 事务在提交或回滚后必须是关闭状态
- 事务在查询后必须是打开状态
- 事务(非threaded tx)必须线程隔离,多线程操作同一事务互不影响
更多事务规范用例见:Transaction Test
HugeGraph事务实现
- 一个事务中所有的操作要么成功要么失败
- 一个事务只能读取到另外一个事务已提交的内容(Read committed)
- 所有未提交的操作均能在本事务中查询出来,包括:
- 增加顶点能够查询出该顶点
- 删除顶点能够过滤掉该顶点
- 删除顶点能够过滤掉该顶点相关边
- 增加边能够查询出该边
- 删除边能够过滤掉该边
- 增加/修改(顶点、边)属性能够在查询时生效
- 删除(顶点、边)属性能够在查询时生效
- 所有未提交的操作在事务回滚后均失效,包括:
- 顶点、边的增加、删除
- 属性的增加/修改、删除
示例:一个事务无法读取另一个事务未提交的内容
static void testUncommittedTx(final HugeGraph graph) throws InterruptedException {
final CountDownLatch latchUncommit = new CountDownLatch(1);
final CountDownLatch latchRollback = new CountDownLatch(1);
Thread thread = new Thread(() -> {
// this is a new transaction in the new thread
graph.tx().open();
System.out.println("current transaction operations");
Vertex james = graph.addVertex(T.label, "author",
"id", 1, "name", "James Gosling",
"age", 62, "lived", "Canadian");
Vertex java = graph.addVertex(T.label, "language", "name", "java",
"versions", Arrays.asList(6, 7, 8));
james.addEdge("created", java);
// we can query the uncommitted records in the current transaction
System.out.println("current transaction assert");
assert graph.vertices().hasNext() == true;
assert graph.edges().hasNext() == true;
latchUncommit.countDown();
try {
latchRollback.await();
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
System.out.println("current transaction rollback");
graph.tx().rollback();
});
thread.start();
// query none result in other transaction when not commit()
latchUncommit.await();
System.out.println("other transaction assert for uncommitted");
assert !graph.vertices().hasNext();
assert !graph.edges().hasNext();
latchRollback.countDown();
thread.join();
// query none result in other transaction after rollback()
System.out.println("other transaction assert for rollback");
assert !graph.vertices().hasNext();
assert !graph.edges().hasNext();
}
事务实现原理
- 服务端内部通过将事务与线程绑定实现隔离(ThreadLocal)
- 本事务未提交的内容按照时间顺序覆盖老数据以供本事务查询最新版本数据
- 底层依赖后端数据库保证事务原子性操作(如Cassandra/RocksDB的batch接口均保证原子性)
注意
RESTful API暂时未暴露事务接口
TinkerPop API允许打开事务,请求完成时会自动关闭(Gremlin Server强制关闭)