This is the multi-page printable view of this section. Click here to print.
QUERY LANGUAGE
1 - HugeGraph Gremlin
概述
HugeGraph支持Apache TinkerPop3的图形遍历查询语言Gremlin。 SQL是关系型数据库查询语言,而Gremlin是一种通用的图数据库查询语言,Gremlin可用于创建图的实体(Vertex和Edge)、修改实体内部属性、删除实体,也可执行图的查询操作。
Gremlin可用于创建图的实体(Vertex和Edge)、修改实体内部属性、删除实体,更主要的是可用于执行图的查询及分析操作。
TinkerPop Features
HugeGraph实现了TinkerPop框架,但是并没有实现TinkerPop所有的特性。
下表列出HugeGraph对TinkerPop各种特性的支持情况:
Graph Features
| Name | Description | Support |
|---|---|---|
| Computer | Determines if the {@code Graph} implementation supports {@link GraphComputer} based processing | false |
| Transactions | Determines if the {@code Graph} implementations supports transactions. | true |
| Persistence | Determines if the {@code Graph} implementation supports persisting it’s contents natively to disk.This feature does not refer to every graph’s ability to write to disk via the Gremlin IO packages(.e.g. GraphML), unless the graph natively persists to disk via those options somehow. For example,TinkerGraph does not support this feature as it is a pure in-sideEffects graph. | true |
| ThreadedTransactions | Determines if the {@code Graph} implementation supports threaded transactions which allow a transaction be executed across multiple threads via {@link Transaction#createThreadedTx()}. | false |
| ConcurrentAccess | Determines if the {@code Graph} implementation supports more than one connection to the same instance at the same time. For example, Neo4j embedded does not support this feature because concurrent access to the same database files by multiple instances is not possible. However, Neo4j HA could support this feature as each new {@code Graph} instance coordinates with the Neo4j cluster allowing multiple instances to operate on the same database. | false |
Vertex Features
| Name | Description | Support |
|---|---|---|
| UserSuppliedIds | Determines if an {@link Element} can have a user defined identifier. Implementation that do not support this feature will be expected to auto-generate unique identifiers. In other words, if the {@link Graph} allows {@code graph.addVertex(id,x)} to work and thus set the identifier of the newly added {@link Vertex} to the value of {@code x} then this feature should return true. In this case, {@code x} is assumed to be an identifier data type that the {@link Graph} will accept. | false |
| NumericIds | Determines if an {@link Element} has numeric identifiers as their internal representation. In other words,if the value returned from {@link Element#id()} is a numeric value then this method should be return {@code true}. Note that this feature is most generally used for determining the appropriate tests to execute in the Gremlin Test Suite. | false |
| StringIds | Determines if an {@link Element} has string identifiers as their internal representation. In other words, if the value returned from {@link Element#id()} is a string value then this method should be return {@code true}. Note that this feature is most generally used for determining the appropriate tests to execute in the Gremlin Test Suite. | false |
| UuidIds | Determines if an {@link Element} has UUID identifiers as their internal representation. In other words,if the value returned from {@link Element#id()} is a {@link UUID} value then this method should be return {@code true}.Note that this feature is most generally used for determining the appropriate tests to execute in the Gremlin Test Suite. | false |
| CustomIds | Determines if an {@link Element} has a specific custom object as their internal representation.In other words, if the value returned from {@link Element#id()} is a type defined by the graph implementations, such as OrientDB’s {@code Rid}, then this method should be return {@code true}.Note that this feature is most generally used for determining the appropriate tests to execute in the Gremlin Test Suite. | false |
| AnyIds | Determines if an {@link Element} any Java object is a suitable identifier. TinkerGraph is a good example of a {@link Graph} that can support this feature, as it can use any {@link Object} as a value for the identifier. Note that this feature is most generally used for determining the appropriate tests to execute in the Gremlin Test Suite. This setting should only return {@code true} if {@link #supportsUserSuppliedIds()} is {@code true}. | false |
| AddProperty | Determines if an {@link Element} allows properties to be added. This feature is set independently from supporting “data types” and refers to support of calls to {@link Element#property(String, Object)}. | true |
| RemoveProperty | Determines if an {@link Element} allows properties to be removed. | true |
| AddVertices | Determines if a {@link Vertex} can be added to the {@code Graph}. | true |
| MultiProperties | Determines if a {@link Vertex} can support multiple properties with the same key. | false |
| DuplicateMultiProperties | Determines if a {@link Vertex} can support non-unique values on the same key. For this value to be {@code true}, then {@link #supportsMetaProperties()} must also return true. By default this method, just returns what {@link #supportsMultiProperties()} returns. | false |
| MetaProperties | Determines if a {@link Vertex} can support properties on vertex properties. It is assumed that a graph will support all the same data types for meta-properties that are supported for regular properties. | false |
| RemoveVertices | Determines if a {@link Vertex} can be removed from the {@code Graph}. | true |
Edge Features
| Name | Description | Support |
|---|---|---|
| UserSuppliedIds | Determines if an {@link Element} can have a user defined identifier. Implementation that do not support this feature will be expected to auto-generate unique identifiers. In other words, if the {@link Graph} allows {@code graph.addVertex(id,x)} to work and thus set the identifier of the newly added {@link Vertex} to the value of {@code x} then this feature should return true. In this case, {@code x} is assumed to be an identifier data type that the {@link Graph} will accept. | false |
| NumericIds | Determines if an {@link Element} has numeric identifiers as their internal representation. In other words,if the value returned from {@link Element#id()} is a numeric value then this method should be return {@code true}. Note that this feature is most generally used for determining the appropriate tests to execute in the Gremlin Test Suite. | false |
| StringIds | Determines if an {@link Element} has string identifiers as their internal representation. In other words, if the value returned from {@link Element#id()} is a string value then this method should be return {@code true}. Note that this feature is most generally used for determining the appropriate tests to execute in the Gremlin Test Suite. | false |
| UuidIds | Determines if an {@link Element} has UUID identifiers as their internal representation. In other words,if the value returned from {@link Element#id()} is a {@link UUID} value then this method should be return {@code true}.Note that this feature is most generally used for determining the appropriate tests to execute in the Gremlin Test Suite. | false |
| CustomIds | Determines if an {@link Element} has a specific custom object as their internal representation.In other words, if the value returned from {@link Element#id()} is a type defined by the graph implementations, such as OrientDB’s {@code Rid}, then this method should be return {@code true}.Note that this feature is most generally used for determining the appropriate tests to execute in the Gremlin Test Suite. | false |
| AnyIds | Determines if an {@link Element} any Java object is a suitable identifier. TinkerGraph is a good example of a {@link Graph} that can support this feature, as it can use any {@link Object} as a value for the identifier. Note that this feature is most generally used for determining the appropriate tests to execute in the Gremlin Test Suite. This setting should only return {@code true} if {@link #supportsUserSuppliedIds()} is {@code true}. | false |
| AddProperty | Determines if an {@link Element} allows properties to be added. This feature is set independently from supporting “data types” and refers to support of calls to {@link Element#property(String, Object)}. | true |
| RemoveProperty | Determines if an {@link Element} allows properties to be removed. | true |
| AddEdges | Determines if an {@link Edge} can be added to a {@code Vertex}. | true |
| RemoveEdges | Determines if an {@link Edge} can be removed from a {@code Vertex}. | true |
Data Type Features
| Name | Description | Support |
|---|---|---|
| BooleanValues | true | |
| ByteValues | true | |
| DoubleValues | true | |
| FloatValues | true | |
| IntegerValues | true | |
| LongValues | true | |
| MapValues | Supports setting of a {@code Map} value. The assumption is that the {@code Map} can contain arbitrary serializable values that may or may not be defined as a feature itself | false |
| MixedListValues | Supports setting of a {@code List} value. The assumption is that the {@code List} can contain arbitrary serializable values that may or may not be defined as a feature itself. As this{@code List} is “mixed” it does not need to contain objects of the same type. | false |
| BooleanArrayValues | false | |
| ByteArrayValues | true | |
| DoubleArrayValues | false | |
| FloatArrayValues | false | |
| IntegerArrayValues | false | |
| LongArrayValues | false | |
| SerializableValues | false | |
| StringArrayValues | false | |
| StringValues | true | |
| UniformListValues | Supports setting of a {@code List} value. The assumption is that the {@code List} can contain arbitrary serializable values that may or may not be defined as a feature itself. As this{@code List} is “uniform” it must contain objects of the same type. | false |
Gremlin的步骤
HugeGraph支持Gremlin的所有步骤。有关Gremlin的完整参考信息,请参与Gremlin官网。
| 步骤 | 说明 | 文档 |
|---|---|---|
| addE | 在两个顶点之间添加边 | addE step |
| addV | 将顶点添加到图形 | addV step |
| and | 确保所有遍历都返回值 | and step |
| as | 用于向步骤的输出分配变量的步骤调制器 | as step |
| by | 与group和order配合使用的步骤调制器 | by step |
| coalesce | 返回第一个返回结果的遍历 | coalesce step |
| constant | 返回常量值。 与coalesce配合使用 | constant step |
| count | 从遍历返回计数 | count step |
| dedup | 返回已删除重复内容的值 | dedup step |
| drop | 丢弃值(顶点/边缘) | drop step |
| fold | 充当用于计算结果聚合值的屏障 | fold step |
| group | 根据指定的标签将值分组 | group step |
| has | 用于筛选属性、顶点和边缘。 支持hasLabel、hasId、hasNot 和 has 变体 | has step |
| inject | 将值注入流中 | inject step |
| is | 用于通过布尔表达式执行筛选器 | is step |
| limit | 用于限制遍历中的项数 | limit step |
| local | 本地包装遍历的某个部分,类似于子查询 | local step |
| not | 用于生成筛选器的求反结果 | not step |
| optional | 如果生成了某个结果,则返回指定遍历的结果,否则返回调用元素 | optional step |
| or | 确保至少有一个遍历会返回值 | or step |
| order | 按指定的排序顺序返回结果 | order step |
| path | 返回遍历的完整路径 | path step |
| project | 将属性投影为映射 | project step |
| properties | 返回指定标签的属性 | properties step |
| range | 根据指定的值范围进行筛选 | range step |
| repeat | 将步骤重复指定的次数。 用于循环 | repeat step |
| sample | 用于对遍历返回的结果采样 | sample step |
| select | 用于投影遍历返回的结果 | select step |
| store | 用于遍历返回的非阻塞聚合 | store step |
| tree | 将顶点中的路径聚合到树中 | tree step |
| unfold | 将迭代器作为步骤展开 | unfold step |
| union | 合并多个遍历返回的结果 | union step |
| V | 包括顶点与边之间的遍历所需的步骤:V、E、out、in、both、outE、inE、bothE、outV、inV、bothV 和 otherV | order step |
| where | 用于筛选遍历返回的结果。 支持 eq、neq、lt、lte、gt、gte 和 between 运算符 | where step |
2 - HugeGraph Examples
1 概述
本示例将TitanDB Getting Started 为模板来演示 HugeGraph 的使用方法。通过对比 HugeGraph 和 TitanDB,了解 HugeGraph 和 TitanDB 的差异。
1.1 HugeGraph 与 TitanDB 的异同
HugeGraph 和 TitanDB 都是基于Apache TinkerPop3框架的图数据库,均支持Gremlin图查询语言,在使用方法和接口方面具有很多相似的地方。然而 HugeGraph 是全新设计开发的,其代码结构清晰,功能较为丰富,接口更为友好等特点。
HugeGraph 相对于 TitanDB 而言,其主要特点如下:
- HugeGraph 目前有 HugeGraph-API、HugeGraph-Client、HugeGraph-Loader、HugeGraph-Studio、HugeGraph-Spark 等完善的工具组件,可以完成系统集成、数据载入、图可视化查询、Spark 连接等功能;
- HugeGraph 具有 Server 和 Client 的概念,第三方系统可以通过 jar 引用、client、api 等多种方式接入,而 TitanDB 仅支持 jar 引用方式接入。
- HugeGraph 的 Schema 需要显式定义,所有的插入和查询均需要通过严格的 schema 校验,目前暂不支持 schema 的隐式创建。
- HugeGraph 充分利用后端存储系统的特点来实现数据高效存取,而 TitanDB 以统一的 Kv 结构无视后端的差异性。
- HugeGraph 的更新操作可以实现按需操作(例如:更新某个属性)性能更好。TitanDB 的更新是 read and update 方式。
- HugeGraph 的 VertexId 和 EdgeId 均支持拼接,可实现自动去重,同时查询性能更好。TitanDB 的所有 Id 均是自动生成,查询需要经索引。
1.2 人物关系图谱
本示例通过 Property Graph Model 图数据模型来描述希腊神话中各人物角色的关系(也被成为人物关系图谱),具体关系详见下图。
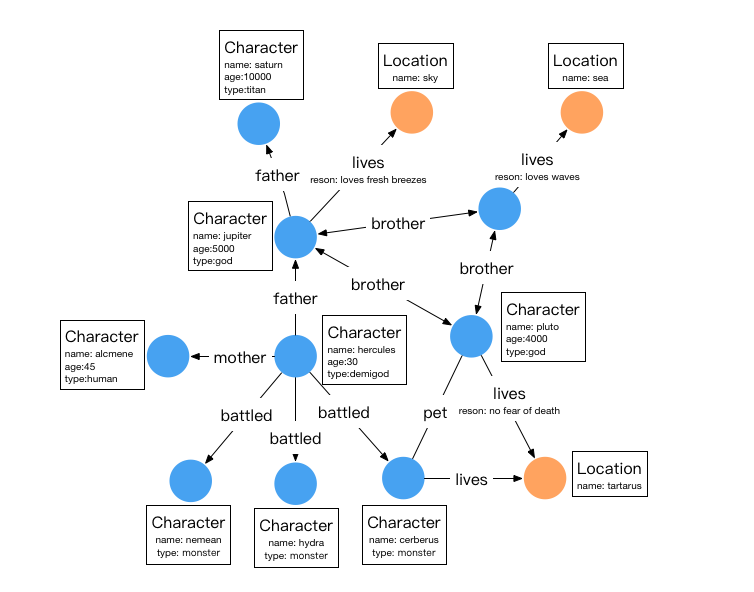
其中,圆形节点代表实体 (Vertex),箭头代表关系(Edge),方框的内容为属性。
该关系图谱中有两类顶点,分别是人物(character)和位置(location)如下表:
| 名称 | 类型 | 属性 |
|---|---|---|
| character | vertex | name,age,type |
| location | vertex | name |
有六种关系,分别是父子(father)、母子(mother)、兄弟(brother)、战斗(battled)、居住 (lives)、拥有宠物(pet)关于关系图谱的具体信息如下:
| 名称 | 类型 | source vertex label | target vertex label | 属性 |
|---|---|---|---|---|
| father | edge | character | character | - |
| mother | edge | character | character | - |
| brother | edge | character | character | - |
| pet | edge | character | character | - |
| lives | edge | character | location | reason |
在 HugeGraph 中,每个 edge label 只能作用于一对 source vertex label 和 target vertex label。也就是说,如果一个图内定义了一种关系 father 连接 character 和 character,那 farther 就不能再连接其他的 vertex labels。
因此本例子将原TitanDB中的monster, god, human, demigod均使用相同的vertex label: character来表示, 同时增加属性type来标识人物的类型。edge label与原TitanDB保持一致。当然为了满足edge label约束,也可以通过调整edge label的name来实现。
2 Graph Schema and Data Ingest Examples
HugeGraph 需要显示创建 Schema,因此需要依次创建 PropertyKey、VertexLabel、EdgeLabel,如果有需要索引还需要创建 IndexLabel。
2.1 Graph Schema
schema = hugegraph.schema()
schema.propertyKey("name").asText().ifNotExist().create()
schema.propertyKey("age").asInt().ifNotExist().create()
schema.propertyKey("time").asInt().ifNotExist().create()
schema.propertyKey("reason").asText().ifNotExist().create()
schema.propertyKey("type").asText().ifNotExist().create()
schema.vertexLabel("character").properties("name", "age", "type").primaryKeys("name").nullableKeys("age").ifNotExist().create()
schema.vertexLabel("location").properties("name").primaryKeys("name").ifNotExist().create()
schema.edgeLabel("father").link("character", "character").ifNotExist().create()
schema.edgeLabel("mother").link("character", "character").ifNotExist().create()
schema.edgeLabel("battled").link("character", "character").properties("time").ifNotExist().create()
schema.edgeLabel("lives").link("character", "location").properties("reason").nullableKeys("reason").ifNotExist().create()
schema.edgeLabel("pet").link("character", "character").ifNotExist().create()
schema.edgeLabel("brother").link("character", "character").ifNotExist().create()
2.2 Graph Data
// add vertices
Vertex saturn = graph.addVertex(T.label, "character", "name", "saturn", "age", 10000, "type", "titan")
Vertex sky = graph.addVertex(T.label, "location", "name", "sky")
Vertex sea = graph.addVertex(T.label, "location", "name", "sea")
Vertex jupiter = graph.addVertex(T.label, "character", "name", "jupiter", "age", 5000, "type", "god")
Vertex neptune = graph.addVertex(T.label, "character", "name", "neptune", "age", 4500, "type", "god")
Vertex hercules = graph.addVertex(T.label, "character", "name", "hercules", "age", 30, "type", "demigod")
Vertex alcmene = graph.addVertex(T.label, "character", "name", "alcmene", "age", 45, "type", "human")
Vertex pluto = graph.addVertex(T.label, "character", "name", "pluto", "age", 4000, "type", "god")
Vertex nemean = graph.addVertex(T.label, "character", "name", "nemean", "type", "monster")
Vertex hydra = graph.addVertex(T.label, "character", "name", "hydra", "type", "monster")
Vertex cerberus = graph.addVertex(T.label, "character", "name", "cerberus", "type", "monster")
Vertex tartarus = graph.addVertex(T.label, "location", "name", "tartarus")
// add edges
jupiter.addEdge("father", saturn)
jupiter.addEdge("lives", sky, "reason", "loves fresh breezes")
jupiter.addEdge("brother", neptune)
jupiter.addEdge("brother", pluto)
neptune.addEdge("lives", sea, "reason", "loves waves")
neptune.addEdge("brother", jupiter)
neptune.addEdge("brother", pluto)
hercules.addEdge("father", jupiter)
hercules.addEdge("mother", alcmene)
hercules.addEdge("battled", nemean, "time", 1)
hercules.addEdge("battled", hydra, "time", 2)
hercules.addEdge("battled", cerberus, "time", 12)
pluto.addEdge("brother", jupiter)
pluto.addEdge("brother", neptune)
pluto.addEdge("lives", tartarus, "reason", "no fear of death")
pluto.addEdge("pet", cerberus)
cerberus.addEdge("lives", tartarus)
2.3 Indices
HugeGraph 默认是自动生成 Id,如果用户通过primaryKeys指定VertexLabel的primaryKeys字段列表后,VertexLabel的 Id 策略将会自动切换到primaryKeys策略。启用primaryKeys策略后,HugeGraph 通过vertexLabel+primaryKeys拼接生成VertexId ,可实现自动去重,同时无需额外创建索引即可以使用primaryKeys中的属性进行快速查询。例如 “character” 和 “location” 都有primaryKeys("name")属性,因此在不额外创建索引的情况下可以通过g.V().hasLabel('character') .has('name','hercules')查询 vertex。
3 Graph Traversal Examples
3.1 Traversal Query
1. Find the grandfather of hercules
g.V().hasLabel('character').has('name','hercules').out('father').out('father')
也可以通过repeat方式:
g.V().hasLabel('character').has('name','hercules').repeat(__.out('father')).times(2)
2. Find the name of Hercules’s father
g.V().hasLabel('character').has('name','hercules').out('father').value('name')
3. Find the characters with age > 100
g.V().hasLabel('character').has('age',gt(100))
4. Find who are pluto’s cohabitants
g.V().hasLabel('character').has('name','pluto').out('lives').in('lives').values('name')
5. Find pluto can’t be his own cohabitant
pluto = g.V().hasLabel('character').has('name', 'pluto')
g.V(pluto).out('lives').in('lives').where(is(neq(pluto)).values('name')
// use 'as'
g.V().hasLabel('character').has('name', 'pluto').as('x').out('lives').in('lives').where(neq('x')).values('name')
6. Pluto’s Brothers
pluto = g.V().hasLabel('character').has('name', 'pluto').next()
// where do pluto's brothers live?
g.V(pluto).out('brother').out('lives').values('name')
// which brother lives in which place?
g.V(pluto).out('brother').as('god').out('lives').as('place').select('god','place')
// what is the name of the brother and the name of the place?
g.V(pluto).out('brother').as('god').out('lives').as('place').select('god','place').by('name')
推荐使用HugeGraph-Hubble 通过可视化的方式来执行上述代码。另外也可以通过 HugeGraph-Client、HugeApi、GremlinConsole 和 GremlinDriver 等多种方式执行上述代码。
3.2 总结
HugeGraph 目前支持 Gremlin 的语法,用户可以通过 Gremlin / REST-API 实现各种查询需求。