HugeGraph-AI


DeepWiki 提供实时更新的项目文档,内容更全面准确,适合快速了解项目最新情况。
📖 https://deepwiki.com/apache/hugegraph-ai
hugegraph-ai 整合了 HugeGraph 与人工智能功能,为开发者构建 AI 驱动的图应用提供全面支持。
✨ 核心功能
- GraphRAG:利用图增强检索构建智能问答系统
- Text2Gremlin:自然语言到图查询的转换,支持 REST API
- 知识图谱构建:使用大语言模型从文本自动构建图谱
- 图机器学习:集成 21 种图学习算法(GCN、GAT、GraphSAGE 等)
- Python 客户端:易于使用的 HugeGraph Python 操作接口
- AI 智能体:提供智能图分析与推理能力
🎉 v1.5.0 新特性
- Text2Gremlin REST API:通过 REST 端点将自然语言查询转换为 Gremlin 命令
- 多模型向量支持:每个图实例可以使用独立的嵌入模型
- 双语提示支持:支持英文和中文提示词切换(EN/CN)
- 半自动 Schema 生成:从文本数据智能推断 Schema
- 半自动 Prompt 生成:上下文感知的提示词模板
- 增强的 Reranker 支持:集成 Cohere 和 SiliconFlow 重排序器
- LiteLLM 多供应商支持:统一接口支持 OpenAI、Anthropic、Gemini 等
🚀 快速开始
[!NOTE]
如需完整的部署指南和详细示例,请参阅 hugegraph-llm/README.md。
环境要求
- Python 3.10+(hugegraph-llm 必需)
- uv 0.7+(推荐的包管理器)
- HugeGraph Server 1.5+(必需)
- Docker(可选,用于容器化部署)
方案一:Docker 部署(推荐)
# 克隆仓库
git clone https://github.com/apache/hugegraph-ai.git
cd hugegraph-ai
# 设置环境并启动服务
cp docker/env.template docker/.env
# 编辑 docker/.env 设置你的 PROJECT_PATH
cd docker
docker-compose -f docker-compose-network.yml up -d
# 访问服务:
# - HugeGraph Server: http://localhost:8080
# - RAG 服务: http://localhost:8001
方案二:源码安装
# 1. 启动 HugeGraph Server
docker run -itd --name=server -p 8080:8080 hugegraph/hugegraph
# 2. 克隆并设置项目
git clone https://github.com/apache/hugegraph-ai.git
cd hugegraph-ai/hugegraph-llm
# 3. 安装依赖
uv venv && source .venv/bin/activate
uv pip install -e .
# 4. 启动演示
python -m hugegraph_llm.demo.rag_demo.app
# 访问 http://127.0.0.1:8001
基本用法示例
GraphRAG - 问答
from hugegraph_llm.operators.graph_rag_task import RAGPipeline
# 初始化 RAG 工作流
graph_rag = RAGPipeline()
# 对你的图进行提问
result = (graph_rag
.extract_keywords(text="给我讲讲 Al Pacino 的故事。")
.keywords_to_vid()
.query_graphdb(max_deep=2, max_graph_items=30)
.synthesize_answer()
.run())
知识图谱构建
from hugegraph_llm.models.llms.init_llm import LLMs
from hugegraph_llm.operators.kg_construction_task import KgBuilder
# 从文本构建知识图谱
TEXT = "你的文本内容..."
builder = KgBuilder(LLMs().get_chat_llm())
(builder
.import_schema(from_hugegraph="hugegraph")
.chunk_split(TEXT)
.extract_info(extract_type="property_graph")
.commit_to_hugegraph()
.run())
图机器学习
from pyhugegraph.client import PyHugeClient
# 连接 HugeGraph 并运行机器学习算法
# 详细示例请参阅 hugegraph-ml 文档
📦 模块
用于图应用的大语言模型集成:
- GraphRAG:基于图数据的检索增强生成
- 知识图谱构建:从文本自动构建知识图谱
- 自然语言接口:使用自然语言查询图
- AI 智能体:智能图分析与推理
包含 21 种算法的图机器学习:
- 节点分类:GCN、GAT、GraphSAGE、APPNP、AGNN、ARMA、DAGNN、DeeperGCN、GRAND、JKNet、Cluster-GCN
- 图分类:DiffPool、GIN
- 图嵌入:DGI、BGRL、GRACE
- 链接预测:SEAL、P-GNN、GATNE
- 欺诈检测:CARE-GNN、BGNN
- 后处理:C&S(Correct & Smooth)
用于 HugeGraph 操作的 Python 客户端:
- Schema 管理:定义顶点/边标签和属性
- CRUD 操作:创建、读取、更新、删除图数据
- Gremlin 查询:执行图遍历查询
- REST API:完整的 HugeGraph REST API 覆盖
📚 了解更多
🔗 相关项目
🤝 贡献
我们欢迎贡献!详情请参阅我们的贡献指南。
开发设置:
- 使用 GitHub Desktop 更轻松地管理 PR
- 提交 PR 前运行
./style/code_format_and_analysis.sh - 报告错误前检查现有问题

📄 许可证
hugegraph-ai 采用 Apache 2.0 许可证。
📞 联系我们

1 - HugeGraph-LLM
本文为中文翻译版本,内容基于英文版进行,我们欢迎您随时提出修改建议。我们推荐您阅读 AI 仓库 README 以获取最新信息,官网会定期同步更新。
连接图数据库与大语言模型的桥梁
AI 总结项目文档:
🎯 概述
HugeGraph-LLM 是一个功能强大的工具包,它融合了图数据库和大型语言模型的优势,实现了 HugeGraph 与 LLM 之间的无缝集成,助力开发者构建智能应用。
核心功能
- 🏗️ 知识图谱构建:利用 LLM 和 HugeGraph 自动构建知识图谱。
- 🗣️ 自然语言查询:通过自然语言(Gremlin/Cypher)操作图数据库。
- 🔍 图增强 RAG:借助知识图谱提升问答准确性(GraphRAG 和 Graph Agent)。
更多源码文档,请访问我们的 DeepWiki 页面(推荐)。
📋 环境要求
[!IMPORTANT]
- Python:3.10+(未在 3.12 版本测试)
- HugeGraph Server:1.3+(推荐 1.5+)
- UV 包管理器:0.7+
🚀 快速开始
请选择您偏好的部署方式:
方案一:Docker Compose(推荐)
这是同时启动 HugeGraph Server 和 RAG 服务的最快方法:
# 1. 设置环境
cp docker/env.template docker/.env
# 编辑 docker/.env,将 PROJECT_PATH 设置为您的实际项目路径
# 2. 部署服务
cd docker
docker-compose -f docker-compose-network.yml up -d
# 3. 验证部署
docker-compose -f docker-compose-network.yml ps
# 4. 访问服务
# HugeGraph Server: http://localhost:8080
# RAG 服务: http://localhost:8001
方案二:独立 Docker 容器
如果您希望对各组件进行更精细的控制:
可用镜像
hugegraph/rag:开发镜像,可访问源代码hugegraph/rag-bin:生产优化的二进制文件(使用 Nuitka 编译)
# 1. 创建网络
docker network create -d bridge hugegraph-net
# 2. 启动 HugeGraph Server
docker run -itd --name=server -p 8080:8080 --network hugegraph-net hugegraph/hugegraph
# 3. 启动 RAG 服务
docker pull hugegraph/rag:latest
docker run -itd --name rag \
-v /path/to/your/hugegraph-llm/.env:/home/work/hugegraph-llm/.env \
-p 8001:8001 --network hugegraph-net hugegraph/rag
# 4. 监控日志
docker logs -f rag
方案三:从源码构建
适用于开发和自定义场景:
# 1. 启动 HugeGraph Server
docker run -itd --name=server -p 8080:8080 hugegraph/hugegraph
# 2. 安装 UV 包管理器
curl -LsSf https://astral.sh/uv/install.sh | sh
# 3. 克隆并设置项目
git clone https://github.com/apache/hugegraph-ai.git
cd hugegraph-ai/hugegraph-llm
# 4. 创建虚拟环境并安装依赖
uv venv && source .venv/bin/activate
uv pip install -e .
# 5. 启动 RAG 演示
python -m hugegraph_llm.demo.rag_demo.app
# 访问: http://127.0.0.1:8001
# 6. (可选) 自定义主机/端口
python -m hugegraph_llm.demo.rag_demo.app --host 127.0.0.1 --port 18001
额外设置(可选)
# 下载 NLTK 停用词以优化文本处理
python ./hugegraph_llm/operators/common_op/nltk_helper.py
# 更新配置文件
python -m hugegraph_llm.config.generate --update
[!TIP]
查看我们的快速入门指南获取详细用法示例和查询逻辑解释。
💡 用法示例
知识图谱构建
交互式 Web 界面
使用 Gradio 界面进行可视化知识图谱构建:
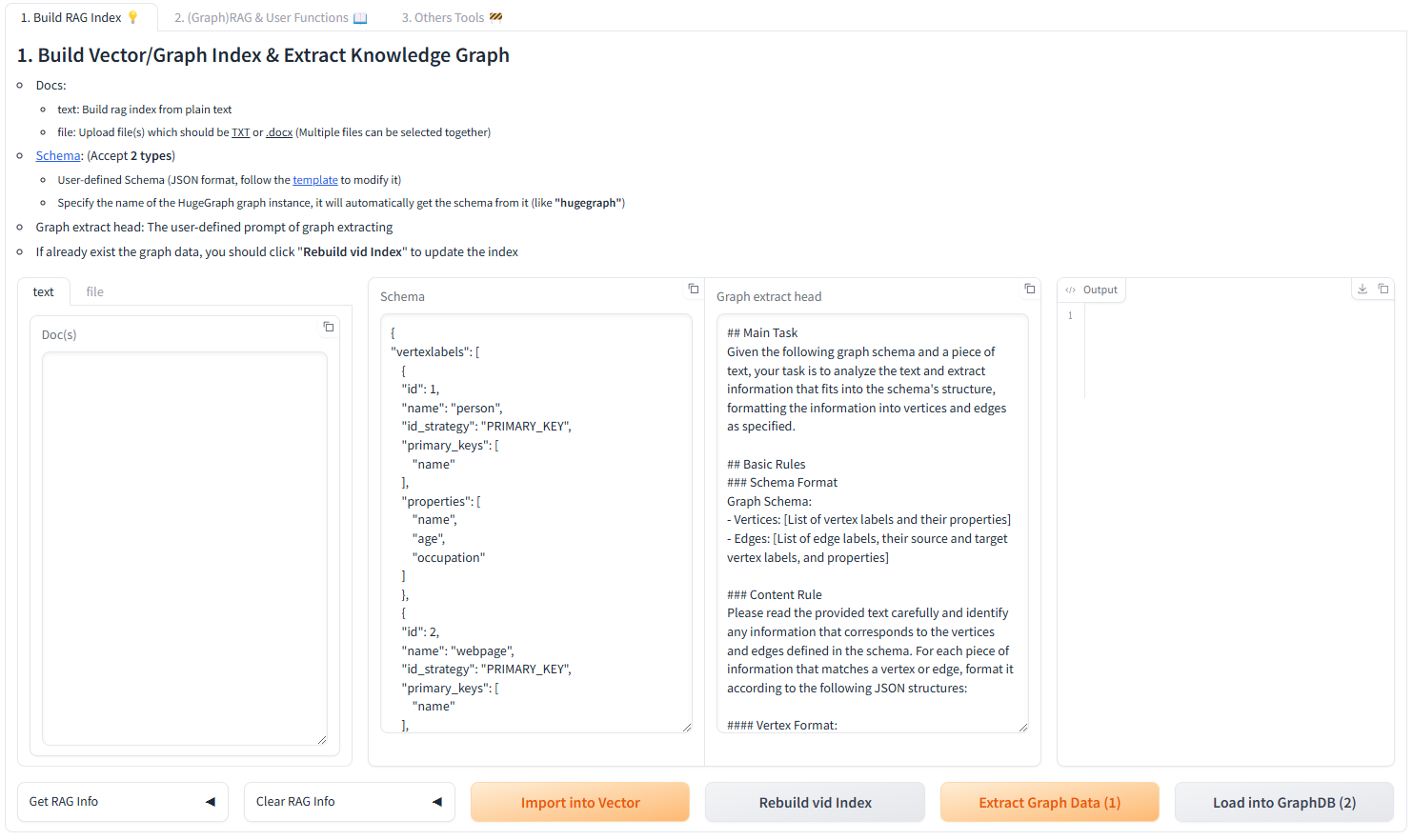
输入选项:
- 文本:直接输入文本用于 RAG 索引创建
- 文件:上传 TXT 或 DOCX 文件(支持多选)
Schema 配置:
- 自定义 Schema:遵循我们模板的 JSON 格式
- HugeGraph Schema:使用现有图实例的 Schema(例如,“hugegraph”)
代码构建
使用 KgBuilder 类通过代码构建知识图谱:
from hugegraph_llm.models.llms.init_llm import LLMs
from hugegraph_llm.operators.kg_construction_task import KgBuilder
# 初始化并链式操作
TEXT = "在此处输入您的文本内容..."
builder = KgBuilder(LLMs().get_chat_llm())
(
builder
.import_schema(from_hugegraph="talent_graph").print_result()
.chunk_split(TEXT).print_result()
.extract_info(extract_type="property_graph").print_result()
.commit_to_hugegraph()
.run()
)
工作流:
graph LR
A[导入 Schema] --> B[文本分块]
B --> C[提取信息]
C --> D[提交到 HugeGraph]
D --> E[执行工作流]
style A fill:#fff2cc
style B fill:#d5e8d4
style C fill:#dae8fc
style D fill:#f8cecc
style E fill:#e1d5e7
图增强 RAG
利用 HugeGraph 进行检索增强生成:
from hugegraph_llm.operators.graph_rag_task import RAGPipeline
# 初始化 RAG 工作流
graph_rag = RAGPipeline()
# 执行 RAG 工作流
(
graph_rag
.extract_keywords(text="给我讲讲 Al Pacino 的故事。")
.keywords_to_vid()
.query_graphdb(max_deep=2, max_graph_items=30)
.merge_dedup_rerank()
.synthesize_answer(vector_only_answer=False, graph_only_answer=True)
.run(verbose=True)
)
RAG 工作流:
graph TD
A[用户查询] --> B[提取关键词]
B --> C[匹配图节点]
C --> D[检索图上下文]
D --> E[重排序结果]
E --> F[生成答案]
style A fill:#e3f2fd
style B fill:#f3e5f5
style C fill:#e8f5e8
style D fill:#fff3e0
style E fill:#fce4ec
style F fill:#e0f2f1
🔧 配置
运行演示后,将自动生成配置文件:
- 环境:
hugegraph-llm/.env - 提示:
hugegraph-llm/src/hugegraph_llm/resources/demo/config_prompt.yaml
[!NOTE]
使用 Web 界面时,配置更改会自动保存。对于手动更改,刷新页面即可加载更新。
LLM 提供商配置
本项目使用 LiteLLM 实现多提供商 LLM 支持,可统一访问 OpenAI、Anthropic、Google、Cohere 以及 100 多个其他提供商。
方案一:直接 LLM 连接(OpenAI、Ollama)
# .env 配置
chat_llm_type=openai # 或 ollama/local
openai_api_key=sk-xxx
openai_api_base=https://api.openai.com/v1
openai_language_model=gpt-4o-mini
openai_max_tokens=4096
方案二:LiteLLM 多提供商支持
LiteLLM 作为多个 LLM 提供商的统一代理:
# .env 配置
chat_llm_type=litellm
extract_llm_type=litellm
text2gql_llm_type=litellm
# LiteLLM 设置
litellm_api_base=http://localhost:4000 # LiteLLM 代理服务器
litellm_api_key=sk-1234 # LiteLLM API 密钥
# 模型选择(提供商/模型格式)
litellm_language_model=anthropic/claude-3-5-sonnet-20241022
litellm_max_tokens=4096
支持的提供商:OpenAI、Anthropic、Google(Gemini)、Azure、Cohere、Bedrock、Vertex AI、Hugging Face 等。
完整提供商列表和配置详情,请访问 LiteLLM Providers。
Reranker 配置
Reranker 通过重新排序检索结果来提高 RAG 准确性。支持的提供商:
# Cohere Reranker
reranker_type=cohere
cohere_api_key=your-cohere-key
cohere_rerank_model=rerank-english-v3.0
# SiliconFlow Reranker
reranker_type=siliconflow
siliconflow_api_key=your-siliconflow-key
siliconflow_rerank_model=BAAI/bge-reranker-v2-m3
Text2Gremlin 配置
将自然语言转换为 Gremlin 查询:
from hugegraph_llm.operators.graph_rag_task import Text2GremlinPipeline
# 初始化工作流
text2gremlin = Text2GremlinPipeline()
# 生成 Gremlin 查询
result = (
text2gremlin
.query_to_gremlin(query="查找所有由 Francis Ford Coppola 执导的电影")
.execute_gremlin_query()
.run()
)
REST API 端点:有关 HTTP 端点详情,请参阅 REST API 文档。
📚 其他资源
- 图可视化:使用 HugeGraph Hubble 进行数据分析和 Schema 管理
- API 文档:浏览我们的 REST API 端点以进行集成
- 社区:加入我们的讨论并为项目做出贡献
许可证:Apache License 2.0 | 社区:Apache HugeGraph
2 - HugeGraph-ML
HugeGraph-ML 将 HugeGraph 与流行的图学习库集成,支持直接在图数据上进行端到端的机器学习工作流。
概述
hugegraph-ml 提供了统一接口,用于将图神经网络和机器学习算法应用于存储在 HugeGraph 中的数据。它通过无缝转换 HugeGraph 数据到主流 ML 框架兼容格式,消除了复杂的数据导出/导入流程。
核心功能
- 直接 HugeGraph 集成:无需手动导出即可直接从 HugeGraph 查询图数据
- 21 种算法实现:全面覆盖节点分类、图分类、嵌入和链接预测
- DGL 后端:利用深度图库(DGL)进行高效训练
- 端到端工作流:从数据加载到模型训练和评估
- 模块化任务:可复用的常见 ML 场景任务抽象
环境要求
- Python:3.9+(独立模块)
- HugeGraph Server:1.0+(推荐:1.5+)
- UV 包管理器:0.7+(用于依赖管理)
安装
1. 启动 HugeGraph Server
# 方案一:Docker(推荐)
docker run -itd --name=hugegraph -p 8080:8080 hugegraph/hugegraph
# 方案二:二进制包
# 参见 https://hugegraph.apache.org/docs/download/download/
2. 克隆并设置
git clone https://github.com/apache/hugegraph-ai.git
cd hugegraph-ai/hugegraph-ml
3. 安装依赖
# uv sync 自动创建 .venv 并安装所有依赖
uv sync
# 激活虚拟环境
source .venv/bin/activate
4. 导航到源代码目录
[!NOTE]
所有示例均假定您在已激活的虚拟环境中。
已实现算法
HugeGraph-ML 目前实现了跨多个类别的 21 种图机器学习算法:
节点分类(11 种算法)
基于网络结构和特征预测图节点的标签。
| 算法 | 论文 | 描述 |
|---|
| GCN | Kipf & Welling, 2017 | 图卷积网络 |
| GAT | Veličković et al., 2018 | 图注意力网络 |
| GraphSAGE | Hamilton et al., 2017 | 归纳式表示学习 |
| APPNP | Klicpera et al., 2019 | 个性化 PageRank 传播 |
| AGNN | Thekumparampil et al., 2018 | 基于注意力的 GNN |
| ARMA | Bianchi et al., 2019 | 自回归移动平均滤波器 |
| DAGNN | Liu et al., 2020 | 深度自适应图神经网络 |
| DeeperGCN | Li et al., 2020 | 非常深的 GCN 架构 |
| GRAND | Feng et al., 2020 | 图随机神经网络 |
| JKNet | Xu et al., 2018 | 跳跃知识网络 |
| Cluster-GCN | Chiang et al., 2019 | 通过聚类实现可扩展 GCN 训练 |
图分类(2 种算法)
基于结构和节点特征对整个图进行分类。
图嵌入(3 种算法)
学习用于下游任务的无监督节点表示。
链接预测(3 种算法)
预测图中缺失或未来的连接。
欺诈检测(2 种算法)
检测图中的异常节点(例如欺诈账户)。
后处理(1 种算法)
通过标签传播改进预测。
使用示例
示例 1:使用 DGI 进行节点嵌入
使用深度图信息最大化(DGI)在 Cora 数据集上进行无监督节点嵌入。
步骤 1:导入数据集(如需)
from hugegraph_ml.utils.dgl2hugegraph_utils import import_graph_from_dgl
# 从 DGL 导入 Cora 数据集到 HugeGraph
import_graph_from_dgl("cora")
步骤 2:转换图数据
from hugegraph_ml.data.hugegraph2dgl import HugeGraph2DGL
# 将 HugeGraph 数据转换为 DGL 格式
hg2d = HugeGraph2DGL()
graph = hg2d.convert_graph(vertex_label="CORA_vertex", edge_label="CORA_edge")
步骤 3:初始化模型
from hugegraph_ml.models.dgi import DGI
# 创建 DGI 模型
model = DGI(n_in_feats=graph.ndata["feat"].shape[1])
步骤 4:训练并生成嵌入
from hugegraph_ml.tasks.node_embed import NodeEmbed
# 训练模型并生成节点嵌入
node_embed_task = NodeEmbed(graph=graph, model=model)
embedded_graph = node_embed_task.train_and_embed(
add_self_loop=True,
n_epochs=300,
patience=30
)
步骤 5:下游任务(节点分类)
from hugegraph_ml.models.mlp import MLPClassifier
from hugegraph_ml.tasks.node_classify import NodeClassify
# 使用嵌入进行节点分类
model = MLPClassifier(
n_in_feat=embedded_graph.ndata["feat"].shape[1],
n_out_feat=embedded_graph.ndata["label"].unique().shape[0]
)
node_clf_task = NodeClassify(graph=embedded_graph, model=model)
node_clf_task.train(lr=1e-3, n_epochs=400, patience=40)
print(node_clf_task.evaluate())
预期输出:
{'accuracy': 0.82, 'loss': 0.5714246034622192}
完整示例:参见 dgi_example.py
示例 2:使用 GRAND 进行节点分类
使用 GRAND 模型直接对节点进行分类(无需单独的嵌入步骤)。
from hugegraph_ml.data.hugegraph2dgl import HugeGraph2DGL
from hugegraph_ml.models.grand import GRAND
from hugegraph_ml.tasks.node_classify import NodeClassify
# 加载图
hg2d = HugeGraph2DGL()
graph = hg2d.convert_graph(vertex_label="CORA_vertex", edge_label="CORA_edge")
# 初始化 GRAND 模型
model = GRAND(
n_in_feats=graph.ndata["feat"].shape[1],
n_out_feats=graph.ndata["label"].unique().shape[0]
)
# 训练和评估
node_clf_task = NodeClassify(graph=graph, model=model)
node_clf_task.train(lr=1e-2, n_epochs=1500, patience=100)
print(node_clf_task.evaluate())
完整示例:参见 grand_example.py
核心组件
HugeGraph2DGL 转换器
无缝将 HugeGraph 数据转换为 DGL 图格式:
from hugegraph_ml.data.hugegraph2dgl import HugeGraph2DGL
hg2d = HugeGraph2DGL()
graph = hg2d.convert_graph(
vertex_label="person", # 要提取的顶点标签
edge_label="knows", # 要提取的边标签
directed=False # 图的方向性
)
任务抽象
用于常见 ML 工作流的可复用任务对象:
| 任务 | 类 | 用途 |
|---|
| 节点嵌入 | NodeEmbed | 生成无监督节点嵌入 |
| 节点分类 | NodeClassify | 预测节点标签 |
| 图分类 | GraphClassify | 预测图级标签 |
| 链接预测 | LinkPredict | 预测缺失边 |
最佳实践
- 从小数据集开始:在扩展之前先在小图(例如 Cora、Citeseer)上测试您的流程
- 使用早停:设置
patience 参数以避免过拟合 - 调整超参数:根据数据集大小调整学习率、隐藏维度和周期数
- 监控 GPU 内存:大图可能需要批量训练(例如 Cluster-GCN)
- 验证 Schema:确保顶点/边标签与您的 HugeGraph schema 匹配
故障排除
| 问题 | 解决方案 |
|---|
| 连接 HugeGraph “Connection refused” | 验证服务器是否在 8080 端口运行 |
| CUDA 内存不足 | 减少批大小或使用仅 CPU 模式 |
| 模型收敛问题 | 尝试不同的学习率(1e-2、1e-3、1e-4) |
| DGL 的 ImportError | 运行 uv sync 重新安装依赖 |
贡献
添加新算法:
- 在
src/hugegraph_ml/models/your_model.py 创建模型文件 - 继承基础模型类并实现
forward() 方法 - 在
src/hugegraph_ml/examples/ 添加示例脚本 - 更新此文档并添加算法详情
另见
3 - GraphRAG UI Details
接续主文档介绍基础 UI 功能及详情,欢迎随时更新和改进,谢谢
1. 项目核心逻辑
构建 RAG 索引职责:
- 文本分割和向量化
- 从文本中提取图(构建知识图谱)并对顶点进行向量化
(Graph)RAG 和用户功能职责:
- 根据查询从构建的知识图谱和向量数据库中检索相关内容,用于补充提示词。
2. (处理流程)构建 RAG 索引
从文本构建知识图谱、分块向量和图顶点向量。

graph TD;
A[原始文本] --> B[文本分割]
B --> C[向量化]
C --> D[存储到向量数据库]
A --> F[文本分割]
F --> G[LLM 基于 schema 和分割后的文本提取图]
G --> H[将图存储到图数据库,\n自动对顶点进行向量化\n并存储到向量数据库]
I[从图数据库检索顶点] --> J[对顶点进行向量化并存储到向量数据库\n注意:增量更新]
四个输入字段:
- 文档: 输入文本
- Schema: 图的 schema,可以以 JSON 格式的 schema 提供,或提供图名称(如果数据库中已存在)。
- 图提取提示词头部: 提示词的头部
- 输出: 显示结果
按钮:
获取 RAG 信息
- 获取向量索引信息: 检索向量索引信息
- 获取图索引信息: 检索图索引信息
清除 RAG 数据
- 清除分块向量索引: 清除分块向量
- 清除图顶点向量索引: 清除图顶点向量
- 清除图数据: 清除图数据
导入到向量: 将文档中的文本转换为向量(需要先对文本进行分块,然后将分块转换为向量)
提取图数据 (1): 基于 Schema,使用图提取提示词头部和分块内容作为提示词,从文档中提取图数据
加载到图数据库 (2): 将提取的图数据存储到数据库(自动调用更新顶点嵌入以将向量存储到向量数据库)
更新顶点嵌入: 将图顶点转换为向量
执行流程:
- 在文档字段中输入文本。
- 点击导入到向量按钮,对文本进行分割和向量化,存储到向量数据库。
- 在 Schema 字段中输入图的 Schema。
- 点击提取图数据 (1) 按钮,将文本提取为图。
- 点击加载到图数据库 (2) 按钮,将提取的图存储到图数据库(这会自动调用更新顶点嵌入以将向量存储到向量数据库)。
- 点击更新顶点嵌入按钮,将图顶点向量化并存储到向量数据库。
3. (处理流程)(Graph)RAG 和用户功能
前一个模块中的导入到向量按钮将文本(分块)转换为向量,更新顶点嵌入按钮将图顶点转换为向量。这些向量分别存储,用于在本模块中补充查询(答案生成)的上下文。换句话说,前一个模块为 RAG 准备数据(向量化),而本模块执行 RAG。
本模块包含两个部分:
第一部分处理单个查询,第二部分同时处理多个查询。以下是第一部分的说明。

graph TD;
A[问题] --> B[将问题向量化并在向量数据库中搜索最相似的分块]
A --> F[使用 LLM 提取关键词]
F --> G[在图数据库中使用关键词精确匹配顶点;\n在向量数据库中执行模糊匹配(图顶点)]
G --> H[使用匹配的顶点和查询通过 LLM 生成 Gremlin 查询]
H --> I[执行 Gremlin 查询;如果成功则完成;如果失败则回退到 BFS]
B --> J[对结果排序]
I --> J
J --> K[生成答案]
输入字段:
- 问题: 输入查询
- 查询提示词: 用于向 LLM 提出最终问题的提示词模板
- 关键词提取提示词: 用于从问题中提取关键词的提示词模板
- 模板数量: < 0 表示禁用 text2gql;= 0 表示不使用模板(零样本);> 0 表示使用指定数量的模板
查询范围选择:
- 基础 LLM 答案: 不使用 RAG 功能
- 仅向量答案: 仅使用基于向量的检索(在向量数据库中查询分块向量)
- 仅图答案: 仅使用基于图的检索(在向量数据库中查询图顶点向量和图数据库)
- 图-向量答案: 同时使用基于图和基于向量的检索

执行流程:
仅图答案:

仅向量答案:
- 将查询转换为向量。
- 在向量数据库的分块向量数据集中搜索最相似的内容。
排序和答案生成:
- 执行检索后,对搜索结果进行排序以构建最终的提示词。
- 基于不同的提示词配置生成答案,并在不同的输出字段中显示:

4. (处理流程)Text2Gremlin
将自然语言查询转换为 Gremlin 查询。
本模块包含两个部分:
- 构建向量模板索引(可选): 将示例文件中的查询/gremlin 对进行向量化并存储到向量数据库中,用于生成 Gremlin 查询时参考。
- 自然语言转 Gremlin: 将自然语言查询转换为 Gremlin 查询。
第一部分较为简单,因此重点介绍第二部分。

graph TD;
A[Gremlin 对文件] --> C[向量化查询]
C --> D[存储到向量数据库]
F[自然语言查询] --> G[在向量数据库中搜索最相似的查询\n(如果向量数据库中不存在 Gremlin 对,\n将自动使用默认文件进行向量化)\n并检索对应的 Gremlin]
G --> H[将匹配的对添加到提示词中\n并使用 LLM 生成与自然语言查询\n对应的 Gremlin]
第二部分的输入字段:
- 自然语言查询: 输入要转换为 Gremlin 的自然语言文本。

执行流程:
- 在自然语言查询字段中输入查询(自然语言)。
- 在Schema字段中输入图 schema。
- 点击Text2Gremlin按钮,执行以下逻辑:
- 将查询转换为向量。
- 构建提示词:
- 检索图 schema。
- 在向量数据库中查询示例向量,检索与输入查询相似的查询-gremlin 对(如果向量数据库中缺少示例,将自动使用resources文件夹中的示例进行初始化)。

- 使用构建的提示词生成 Gremlin 查询。
5. 图工具
输入 Gremlin 查询以执行相应操作。
6. 语言切换 (v1.5.0+)
HugeGraph-LLM 支持双语提示词,以提高跨语言的准确性。
在英文和中文之间切换
系统语言影响:
- 系统提示词:LLM 使用的内部提示词
- 关键词提取:特定语言的提取逻辑
- 答案生成:响应格式和风格
配置方法一:环境变量
编辑您的 .env 文件:
# 英文提示词(默认)
LANGUAGE=EN
# 中文提示词
LANGUAGE=CN
更改语言设置后重启服务。
配置方法二:Web UI(动态)
如果您的部署中可用,使用 Web UI 中的设置面板切换语言,无需重启:
- 导航到设置或配置选项卡
- 选择语言:
EN 或 CN - 点击保存 - 更改立即生效
特定语言的行为
| 语言 | 关键词提取 | 答案风格 | 使用场景 |
|---|
EN | 英文 NLP 模型 | 专业、简洁 | 国际用户、英文文档 |
CN | 中文 NLP 模型 | 自然的中文表达 | 中文用户、中文文档 |
[!TIP]
将 LANGUAGE 设置与您的主要文档语言匹配,以获得最佳 RAG 准确性。
REST API 语言覆盖
使用 REST API 时,您可以为每个请求指定自定义提示词,以覆盖默认语言设置:
curl -X POST http://localhost:8001/rag \
-H "Content-Type: application/json" \
-d '{
"query": "告诉我关于阿尔·帕西诺的信息",
"graph_only": true,
"keywords_extract_prompt": "请从以下文本中提取关键实体...",
"answer_prompt": "请根据以下上下文回答问题..."
}'
完整参数详情请参阅 REST API 参考。
4 - 配置参考
本文档提供 HugeGraph-LLM 所有配置选项的完整参考。
配置文件
- 环境文件:
.env(从模板创建或自动生成) - 提示词配置:
src/hugegraph_llm/resources/demo/config_prompt.yaml
[!TIP]
运行 python -m hugegraph_llm.config.generate --update 可自动生成或更新带有默认值的配置文件。
环境变量概览
1. 语言和模型类型选择
# 提示词语言(影响系统提示词和生成文本)
LANGUAGE=EN # 选项: EN | CN
# 不同任务的 LLM 类型
CHAT_LLM_TYPE=openai # 对话/RAG: openai | litellm | ollama/local
EXTRACT_LLM_TYPE=openai # 实体抽取: openai | litellm | ollama/local
TEXT2GQL_LLM_TYPE=openai # 文本转 Gremlin: openai | litellm | ollama/local
# 嵌入模型类型
EMBEDDING_TYPE=openai # 选项: openai | litellm | ollama/local
# Reranker 类型(可选)
RERANKER_TYPE= # 选项: cohere | siliconflow | (留空表示无)
2. OpenAI 配置
每个 LLM 任务(chat、extract、text2gql)都有独立配置:
2.1 Chat LLM(RAG 答案生成)
OPENAI_CHAT_API_BASE=https://api.openai.com/v1
OPENAI_CHAT_API_KEY=sk-your-api-key-here
OPENAI_CHAT_LANGUAGE_MODEL=gpt-4o-mini
OPENAI_CHAT_TOKENS=8192 # 对话响应的最大 tokens
OPENAI_EXTRACT_API_BASE=https://api.openai.com/v1
OPENAI_EXTRACT_API_KEY=sk-your-api-key-here
OPENAI_EXTRACT_LANGUAGE_MODEL=gpt-4o-mini
OPENAI_EXTRACT_TOKENS=1024 # 抽取任务的最大 tokens
2.3 Text2GQL LLM(自然语言转 Gremlin)
OPENAI_TEXT2GQL_API_BASE=https://api.openai.com/v1
OPENAI_TEXT2GQL_API_KEY=sk-your-api-key-here
OPENAI_TEXT2GQL_LANGUAGE_MODEL=gpt-4o-mini
OPENAI_TEXT2GQL_TOKENS=4096 # 查询生成的最大 tokens
2.4 嵌入模型
OPENAI_EMBEDDING_API_BASE=https://api.openai.com/v1
OPENAI_EMBEDDING_API_KEY=sk-your-api-key-here
OPENAI_EMBEDDING_MODEL=text-embedding-3-small
[!NOTE]
您可以为每个任务使用不同的 API 密钥/端点,以优化成本或使用专用模型。
3. LiteLLM 配置(多供应商支持)
LiteLLM 支持统一访问 100 多个 LLM 供应商(OpenAI、Anthropic、Google、Azure 等)。
3.1 Chat LLM
LITELLM_CHAT_API_BASE=http://localhost:4000 # LiteLLM 代理 URL
LITELLM_CHAT_API_KEY=sk-litellm-key # LiteLLM API 密钥
LITELLM_CHAT_LANGUAGE_MODEL=anthropic/claude-3-5-sonnet-20241022
LITELLM_CHAT_TOKENS=8192
LITELLM_EXTRACT_API_BASE=http://localhost:4000
LITELLM_EXTRACT_API_KEY=sk-litellm-key
LITELLM_EXTRACT_LANGUAGE_MODEL=openai/gpt-4o-mini
LITELLM_EXTRACT_TOKENS=256
3.3 Text2GQL LLM
LITELLM_TEXT2GQL_API_BASE=http://localhost:4000
LITELLM_TEXT2GQL_API_KEY=sk-litellm-key
LITELLM_TEXT2GQL_LANGUAGE_MODEL=openai/gpt-4o-mini
LITELLM_TEXT2GQL_TOKENS=4096
3.4 嵌入模型
LITELLM_EMBEDDING_API_BASE=http://localhost:4000
LITELLM_EMBEDDING_API_KEY=sk-litellm-key
LITELLM_EMBEDDING_MODEL=openai/text-embedding-3-small
模型格式: 供应商/模型名称
示例:
openai/gpt-4o-minianthropic/claude-3-5-sonnet-20241022google/gemini-2.0-flash-expazure/gpt-4
完整列表请参阅 LiteLLM Providers。
4. Ollama 配置(本地部署)
使用 Ollama 运行本地 LLM,确保隐私和成本控制。
4.1 Chat LLM
OLLAMA_CHAT_HOST=127.0.0.1
OLLAMA_CHAT_PORT=11434
OLLAMA_CHAT_LANGUAGE_MODEL=llama3.1:8b
OLLAMA_EXTRACT_HOST=127.0.0.1
OLLAMA_EXTRACT_PORT=11434
OLLAMA_EXTRACT_LANGUAGE_MODEL=llama3.1:8b
4.3 Text2GQL LLM
OLLAMA_TEXT2GQL_HOST=127.0.0.1
OLLAMA_TEXT2GQL_PORT=11434
OLLAMA_TEXT2GQL_LANGUAGE_MODEL=qwen2.5-coder:7b
4.4 嵌入模型
OLLAMA_EMBEDDING_HOST=127.0.0.1
OLLAMA_EMBEDDING_PORT=11434
OLLAMA_EMBEDDING_MODEL=nomic-embed-text
[!TIP]
下载模型:ollama pull llama3.1:8b 或 ollama pull qwen2.5-coder:7b
5. Reranker 配置
Reranker 通过根据相关性重新排序检索结果来提高 RAG 准确性。
5.1 Cohere Reranker
RERANKER_TYPE=cohere
COHERE_BASE_URL=https://api.cohere.com/v1/rerank
RERANKER_API_KEY=your-cohere-api-key
RERANKER_MODEL=rerank-english-v3.0
可用模型:
rerank-english-v3.0(英文)rerank-multilingual-v3.0(100+ 种语言)
5.2 SiliconFlow Reranker
RERANKER_TYPE=siliconflow
RERANKER_API_KEY=your-siliconflow-api-key
RERANKER_MODEL=BAAI/bge-reranker-v2-m3
6. HugeGraph 连接
配置与 HugeGraph 服务器实例的连接。
# 服务器连接
GRAPH_IP=127.0.0.1
GRAPH_PORT=8080
GRAPH_NAME=hugegraph # 图实例名称
GRAPH_USER=admin # 用户名
GRAPH_PWD=admin-password # 密码
GRAPH_SPACE= # 图空间(可选,用于多租户)
7. 查询参数
控制图遍历行为和结果限制。
# 图遍历限制
MAX_GRAPH_PATH=10 # 图查询的最大路径深度
MAX_GRAPH_ITEMS=30 # 从图中检索的最大项数
EDGE_LIMIT_PRE_LABEL=8 # 每个标签类型的最大边数
# 属性过滤
LIMIT_PROPERTY=False # 限制结果中的属性(True/False)
8. 向量搜索配置
配置向量相似性搜索参数。
# 向量搜索阈值
VECTOR_DIS_THRESHOLD=0.9 # 最小余弦相似度(0-1,越高越严格)
TOPK_PER_KEYWORD=1 # 每个提取关键词的 Top-K 结果
9. Rerank 配置
# Rerank 结果限制
TOPK_RETURN_RESULTS=20 # 重排序后的 top 结果数
配置优先级
系统按以下顺序加载配置(后面的来源覆盖前面的):
- 默认值(在
*_config.py 文件中) - 环境变量(来自
.env 文件) - 运行时更新(通过 Web UI 或 API 调用)
配置示例
最小配置(OpenAI)
# 语言
LANGUAGE=EN
# LLM 类型
CHAT_LLM_TYPE=openai
EXTRACT_LLM_TYPE=openai
TEXT2GQL_LLM_TYPE=openai
EMBEDDING_TYPE=openai
# OpenAI 凭据(所有任务共用一个密钥)
OPENAI_API_BASE=https://api.openai.com/v1
OPENAI_API_KEY=sk-your-api-key-here
OPENAI_LANGUAGE_MODEL=gpt-4o-mini
OPENAI_EMBEDDING_MODEL=text-embedding-3-small
# HugeGraph 连接
GRAPH_IP=127.0.0.1
GRAPH_PORT=8080
GRAPH_NAME=hugegraph
GRAPH_USER=admin
GRAPH_PWD=admin
生产环境配置(LiteLLM + Reranker)
# 双语支持
LANGUAGE=EN
# 灵活使用 LiteLLM
CHAT_LLM_TYPE=litellm
EXTRACT_LLM_TYPE=litellm
TEXT2GQL_LLM_TYPE=litellm
EMBEDDING_TYPE=litellm
# LiteLLM 代理
LITELLM_CHAT_API_BASE=http://localhost:4000
LITELLM_CHAT_API_KEY=sk-litellm-master-key
LITELLM_CHAT_LANGUAGE_MODEL=anthropic/claude-3-5-sonnet-20241022
LITELLM_CHAT_TOKENS=8192
LITELLM_EXTRACT_API_BASE=http://localhost:4000
LITELLM_EXTRACT_API_KEY=sk-litellm-master-key
LITELLM_EXTRACT_LANGUAGE_MODEL=openai/gpt-4o-mini
LITELLM_EXTRACT_TOKENS=256
LITELLM_TEXT2GQL_API_BASE=http://localhost:4000
LITELLM_TEXT2GQL_API_KEY=sk-litellm-master-key
LITELLM_TEXT2GQL_LANGUAGE_MODEL=openai/gpt-4o-mini
LITELLM_TEXT2GQL_TOKENS=4096
LITELLM_EMBEDDING_API_BASE=http://localhost:4000
LITELLM_EMBEDDING_API_KEY=sk-litellm-master-key
LITELLM_EMBEDDING_MODEL=openai/text-embedding-3-small
# Cohere Reranker 提高准确性
RERANKER_TYPE=cohere
COHERE_BASE_URL=https://api.cohere.com/v1/rerank
RERANKER_API_KEY=your-cohere-key
RERANKER_MODEL=rerank-multilingual-v3.0
# 带认证的 HugeGraph
GRAPH_IP=prod-hugegraph.example.com
GRAPH_PORT=8080
GRAPH_NAME=production_graph
GRAPH_USER=rag_user
GRAPH_PWD=secure-password
GRAPH_SPACE=prod_space
# 优化的查询参数
MAX_GRAPH_PATH=15
MAX_GRAPH_ITEMS=50
VECTOR_DIS_THRESHOLD=0.85
TOPK_RETURN_RESULTS=30
本地/离线配置(Ollama)
# 语言
LANGUAGE=EN
# 全部通过 Ollama 使用本地模型
CHAT_LLM_TYPE=ollama/local
EXTRACT_LLM_TYPE=ollama/local
TEXT2GQL_LLM_TYPE=ollama/local
EMBEDDING_TYPE=ollama/local
# Ollama 端点
OLLAMA_CHAT_HOST=127.0.0.1
OLLAMA_CHAT_PORT=11434
OLLAMA_CHAT_LANGUAGE_MODEL=llama3.1:8b
OLLAMA_EXTRACT_HOST=127.0.0.1
OLLAMA_EXTRACT_PORT=11434
OLLAMA_EXTRACT_LANGUAGE_MODEL=llama3.1:8b
OLLAMA_TEXT2GQL_HOST=127.0.0.1
OLLAMA_TEXT2GQL_PORT=11434
OLLAMA_TEXT2GQL_LANGUAGE_MODEL=qwen2.5-coder:7b
OLLAMA_EMBEDDING_HOST=127.0.0.1
OLLAMA_EMBEDDING_PORT=11434
OLLAMA_EMBEDDING_MODEL=nomic-embed-text
# 离线环境不使用 reranker
RERANKER_TYPE=
# 本地 HugeGraph
GRAPH_IP=127.0.0.1
GRAPH_PORT=8080
GRAPH_NAME=hugegraph
GRAPH_USER=admin
GRAPH_PWD=admin
配置验证
修改 .env 后,验证配置:
- 通过 Web UI:访问
http://localhost:8001 并检查设置面板 - 通过 Python:
from hugegraph_llm.config import settings
print(settings.llm_config)
print(settings.hugegraph_config)
- 通过 REST API:
curl http://localhost:8001/config
故障排除
| 问题 | 解决方案 |
|---|
| “API key not found” | 检查 .env 中的 *_API_KEY 是否正确设置 |
| “Connection refused” | 验证 GRAPH_IP 和 GRAPH_PORT 是否正确 |
| “Model not found” | 对于 Ollama:运行 ollama pull <模型名称> |
| “Rate limit exceeded” | 减少 MAX_GRAPH_ITEMS 或使用不同的 API 密钥 |
| “Embedding dimension mismatch” | 删除现有向量并使用正确模型重建 |
另见
5 - REST API 参考
HugeGraph-LLM 提供 REST API 端点,用于将 RAG 和 Text2Gremlin 功能集成到您的应用程序中。
基础 URL
启动服务时更改主机/端口:
python -m hugegraph_llm.demo.rag_demo.app --host 127.0.0.1 --port 8001
认证
目前 API 支持可选的基于令牌的认证:
# 在 .env 中启用认证
ENABLE_LOGIN=true
USER_TOKEN=your-user-token
ADMIN_TOKEN=your-admin-token
在请求头中传递令牌:
Authorization: Bearer <token>
RAG 端点
1. 完整 RAG 查询
POST /rag
执行完整的 RAG 工作流,包括关键词提取、图检索、向量搜索、重排序和答案生成。
请求体
{
"query": "给我讲讲阿尔·帕西诺的电影",
"raw_answer": false,
"vector_only": false,
"graph_only": true,
"graph_vector_answer": false,
"graph_ratio": 0.5,
"rerank_method": "cohere",
"near_neighbor_first": false,
"gremlin_tmpl_num": 5,
"max_graph_items": 30,
"topk_return_results": 20,
"vector_dis_threshold": 0.9,
"topk_per_keyword": 1,
"custom_priority_info": "",
"answer_prompt": "",
"keywords_extract_prompt": "",
"gremlin_prompt": "",
"client_config": {
"url": "127.0.0.1:8080",
"graph": "hugegraph",
"user": "admin",
"pwd": "admin",
"gs": ""
}
}
参数说明:
| 字段 | 类型 | 必需 | 默认值 | 描述 |
|---|
query | string | 是 | - | 用户的自然语言问题 |
raw_answer | boolean | 否 | false | 返回 LLM 答案而不检索 |
vector_only | boolean | 否 | false | 仅使用向量搜索(无图) |
graph_only | boolean | 否 | false | 仅使用图检索(无向量) |
graph_vector_answer | boolean | 否 | false | 结合图和向量结果 |
graph_ratio | float | 否 | 0.5 | 图与向量结果的比例(0-1) |
rerank_method | string | 否 | "" | 重排序器:“cohere”、“siliconflow”、"" |
near_neighbor_first | boolean | 否 | false | 优先选择直接邻居 |
gremlin_tmpl_num | integer | 否 | 5 | 尝试的 Gremlin 模板数量 |
max_graph_items | integer | 否 | 30 | 图检索的最大项数 |
topk_return_results | integer | 否 | 20 | 重排序后的 Top-K |
vector_dis_threshold | float | 否 | 0.9 | 向量相似度阈值(0-1) |
topk_per_keyword | integer | 否 | 1 | 每个关键词的 Top-K 向量 |
custom_priority_info | string | 否 | "" | 要优先考虑的自定义上下文 |
answer_prompt | string | 否 | "" | 自定义答案生成提示词 |
keywords_extract_prompt | string | 否 | "" | 自定义关键词提取提示词 |
gremlin_prompt | string | 否 | "" | 自定义 Gremlin 生成提示词 |
client_config | object | 否 | null | 覆盖图连接设置 |
响应
{
"query": "给我讲讲阿尔·帕西诺的电影",
"graph_only": {
"answer": "阿尔·帕西诺主演了《教父》(1972 年),由弗朗西斯·福特·科波拉执导...",
"context": ["《教父》是 1972 年的犯罪电影...", "..."],
"graph_paths": ["..."],
"keywords": ["阿尔·帕西诺", "电影"]
}
}
示例(curl)
curl -X POST http://localhost:8001/rag \
-H "Content-Type: application/json" \
-d '{
"query": "给我讲讲阿尔·帕西诺",
"graph_only": true,
"max_graph_items": 30
}'
2. 仅图检索
POST /rag/graph
检索图上下文而不生成答案。用于调试或自定义处理。
请求体
{
"query": "阿尔·帕西诺的电影",
"max_graph_items": 30,
"topk_return_results": 20,
"vector_dis_threshold": 0.9,
"topk_per_keyword": 1,
"gremlin_tmpl_num": 5,
"rerank_method": "cohere",
"near_neighbor_first": false,
"custom_priority_info": "",
"gremlin_prompt": "",
"get_vertex_only": false,
"client_config": {
"url": "127.0.0.1:8080",
"graph": "hugegraph",
"user": "admin",
"pwd": "admin",
"gs": ""
}
}
额外参数:
| 字段 | 类型 | 默认值 | 描述 |
|---|
get_vertex_only | boolean | false | 仅返回顶点 ID,不返回完整详情 |
响应
{
"graph_recall": {
"query": "阿尔·帕西诺的电影",
"keywords": ["阿尔·帕西诺", "电影"],
"match_vids": ["1:阿尔·帕西诺", "2:教父"],
"graph_result_flag": true,
"gremlin": "g.V('1:阿尔·帕西诺').outE().inV().limit(30)",
"graph_result": [
{"id": "1:阿尔·帕西诺", "label": "person", "properties": {"name": "阿尔·帕西诺"}},
{"id": "2:教父", "label": "movie", "properties": {"title": "教父"}}
],
"vertex_degree_list": [5, 12]
}
}
示例(curl)
curl -X POST http://localhost:8001/rag/graph \
-H "Content-Type: application/json" \
-d '{
"query": "阿尔·帕西诺",
"max_graph_items": 30,
"get_vertex_only": false
}'
Text2Gremlin 端点
3. 自然语言转 Gremlin
POST /text2gremlin
将自然语言查询转换为可执行的 Gremlin 命令。
请求体
{
"query": "查找所有由弗朗西斯·福特·科波拉执导的电影",
"example_num": 5,
"gremlin_prompt": "",
"output_types": ["GREMLIN", "RESULT"],
"client_config": {
"url": "127.0.0.1:8080",
"graph": "hugegraph",
"user": "admin",
"pwd": "admin",
"gs": ""
}
}
参数说明:
| 字段 | 类型 | 必需 | 默认值 | 描述 |
|---|
query | string | 是 | - | 自然语言查询 |
example_num | integer | 否 | 5 | 使用的示例模板数量 |
gremlin_prompt | string | 否 | "" | Gremlin 生成的自定义提示词 |
output_types | array | 否 | null | 输出类型:[“GREMLIN”, “RESULT”, “CYPHER”] |
client_config | object | 否 | null | 图连接覆盖 |
输出类型:
GREMLIN:生成的 Gremlin 查询RESULT:图的执行结果CYPHER:Cypher 查询(如果请求)
响应
{
"gremlin": "g.V().has('person','name','弗朗西斯·福特·科波拉').out('directed').hasLabel('movie').values('title')",
"result": [
"教父",
"教父 2",
"现代启示录"
]
}
示例(curl)
curl -X POST http://localhost:8001/text2gremlin \
-H "Content-Type: application/json" \
-d '{
"query": "查找所有由弗朗西斯·福特·科波拉执导的电影",
"output_types": ["GREMLIN", "RESULT"]
}'
配置端点
4. 更新图连接
POST /config/graph
动态更新 HugeGraph 连接设置。
请求体
{
"url": "127.0.0.1:8080",
"name": "hugegraph",
"user": "admin",
"pwd": "admin",
"gs": ""
}
响应
{
"status_code": 201,
"message": "图配置更新成功"
}
5. 更新 LLM 配置
POST /config/llm
运行时更新聊天/提取 LLM 设置。
请求体(OpenAI)
{
"llm_type": "openai",
"api_key": "sk-your-api-key",
"api_base": "https://api.openai.com/v1",
"language_model": "gpt-4o-mini",
"max_tokens": 4096
}
请求体(Ollama)
{
"llm_type": "ollama/local",
"host": "127.0.0.1",
"port": 11434,
"language_model": "llama3.1:8b"
}
6. 更新嵌入配置
POST /config/embedding
更新嵌入模型设置。
请求体
{
"llm_type": "openai",
"api_key": "sk-your-api-key",
"api_base": "https://api.openai.com/v1",
"language_model": "text-embedding-3-small"
}
7. 更新 Reranker 配置
POST /config/rerank
配置重排序器设置。
请求体(Cohere)
{
"reranker_type": "cohere",
"api_key": "your-cohere-key",
"reranker_model": "rerank-multilingual-v3.0",
"cohere_base_url": "https://api.cohere.com/v1/rerank"
}
请求体(SiliconFlow)
{
"reranker_type": "siliconflow",
"api_key": "your-siliconflow-key",
"reranker_model": "BAAI/bge-reranker-v2-m3"
}
错误响应
所有端点返回标准 HTTP 状态码:
| 代码 | 含义 |
|---|
| 200 | 成功 |
| 201 | 已创建(配置已更新) |
| 400 | 错误请求(无效参数) |
| 500 | 内部服务器错误 |
| 501 | 未实现 |
错误响应格式:
Python 客户端示例
import requests
BASE_URL = "http://localhost:8001"
# 1. 配置图连接
graph_config = {
"url": "127.0.0.1:8080",
"name": "hugegraph",
"user": "admin",
"pwd": "admin"
}
requests.post(f"{BASE_URL}/config/graph", json=graph_config)
# 2. 执行 RAG 查询
rag_request = {
"query": "给我讲讲阿尔·帕西诺",
"graph_only": True,
"max_graph_items": 30
}
response = requests.post(f"{BASE_URL}/rag", json=rag_request)
print(response.json())
# 3. 从自然语言生成 Gremlin
text2gql_request = {
"query": "查找所有与阿尔·帕西诺合作的导演",
"output_types": ["GREMLIN", "RESULT"]
}
response = requests.post(f"{BASE_URL}/text2gremlin", json=text2gql_request)
print(response.json())
另见