HugeGraph-Hubble Quick Start
1 HugeGraph-Hubble 概述
特别注意: 当前版本的 Hubble 还没有添加 Auth/Login 相关界面和接口和单独防护, 在下一个 Release 版 (> 1.5) 会加入, 请留意避免把它暴露在公网环境或不受信任的网络中,以免引起相关 SEC 问题 (另外也可以使用 IP & 端口白名单 + HTTPS)
HugeGraph-Hubble 是 HugeGraph 的一站式可视化分析平台,平台涵盖了从数据建模,到数据快速导入, 再到数据的在线、离线分析、以及图的统一管理的全过程,实现了图应用的全流程向导式操作,旨在提升用户的使用流畅度, 降低用户的使用门槛,提供更为高效易用的使用体验。
平台主要包括以下模块:
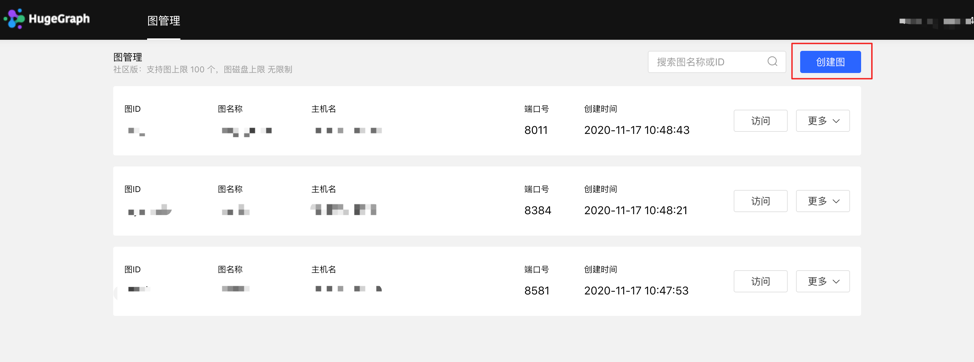
图管理
图管理模块通过图的创建,连接平台与图数据,实现多图的统一管理,并实现图的访问、编辑、删除、查询操作。
元数据建模
元数据建模模块通过创建属性库,顶点类型,边类型,索引类型,实现图模型的构建与管理,平台提供两种模式,列表模式和图模式,可实时展示元数据模型,更加直观。同时还提供了跨图的元数据复用功能,省去相同元数据繁琐的重复创建过程,极大地提升建模效率,增强易用性。
图分析
通过输入图遍历语言 Gremlin 可实现图数据的高性能通用分析,并提供顶点的定制化多维路径查询等功能,提供 3 种图结果展示方式,包括:图形式、表格形式、Json 形式,多维度展示数据形态,满足用户使用的多种场景需求。提供运行记录及常用语句收藏等功能,实现图操作的可追溯,以及查询输入的复用共享,快捷高效。支持图数据的导出,导出格式为 Json 格式。
任务管理
对于需要遍历全图的 Gremlin 任务,索引的创建与重建等耗时较长的异步任务,平台提供相应的任务管理功能,实现异步任务的统一的管理与结果查看。
数据导入 (BETA)
注: 数据导入功能目前适合初步试用,正式数据导入请使用 hugegraph-loader, 性能/稳定性/功能全面许多
数据导入是将用户的业务数据转化为图的顶点和边并插入图数据库中,平台提供了向导式的可视化导入模块,通过创建导入任务, 实现导入任务的管理及多个导入任务的并行运行,提高导入效能。进入导入任务后,只需跟随平台步骤提示,按需上传文件,填写内容, 就可轻松实现图数据的导入过程,同时支持断点续传,错误重试机制等,降低导入成本,提升效率。
2 部署
有三种方式可以部署hugegraph-hubble
- 使用 docker (便于测试)
- 下载 toolchain 二进制包
- 源码编译
2.1 使用 Docker (便于测试)
特别注意: docker 模式下,若 hubble 和 server 在同一宿主机,hubble 页面中设置 server 的
hostname不能设置为localhost/127.0.0.1,因这会指向 hubble 容器内部而非宿主机,导致无法连接到 server.若 hubble 和 server 在同一 docker 网络下,推荐直接使用
container_name(如下例的server) 作为主机名。或者也可以使用 宿主机 IP 作为主机名,此时端口号为宿主机给 server 配置的端口
我们可以使用 docker run -itd --name=hubble -p 8088:8088 hugegraph/hubble:1.5.0 快速启动 hubble.
或者使用 docker-compose 启动 hubble,另外如果 hubble 和 server 在同一个 docker 网络下,可以使用 server 的 contain_name 进行访问,而不需要宿主机的 ip
使用docker-compose up -d,docker-compose.yml如下:
version: '3'
services:
server:
image: hugegraph/hugegraph:1.5.0
container_name: server
ports:
- 8080:8080
hubble:
image: hugegraph/hubble:1.5.0
container_name: hubble
ports:
- 8088:8088
注意:
hugegraph-hubble的 docker 镜像是一个便捷发布版本,用于快速测试试用 hubble,并非ASF 官方发布物料包的方式。你可以从 ASF Release Distribution Policy 中得到更多细节。生产环境推荐使用
release tag(如1.5.0) 稳定版。使用latesttag 默认对应 master 最新代码。
2.2 下载 toolchain 二进制包
hubble项目在toolchain项目中,首先下载toolchain的 tar 包
wget https://downloads.apache.org/incubator/hugegraph/{version}/apache-hugegraph-toolchain-incubating-{version}.tar.gz
tar -xvf apache-hugegraph-toolchain-incubating-{version}.tar.gz
cd apache-hugegraph-toolchain-incubating-{version}.tar.gz/apache-hugegraph-hubble-incubating-{version}
运行hubble
bin/start-hubble.sh
随后我们可以看到
starting HugeGraphHubble ..............timed out with http status 502
2023-08-30 20:38:34 [main] [INFO ] o.a.h.HugeGraphHubble [] - Starting HugeGraphHubble v1.0.0 on cpu05 with PID xxx (~/apache-hugegraph-toolchain-incubating-1.0.0/apache-hugegraph-hubble-incubating-1.0.0/lib/hubble-be-1.0.0.jar started by $USER in ~/apache-hugegraph-toolchain-incubating-1.0.0/apache-hugegraph-hubble-incubating-1.0.0)
...
2023-08-30 20:38:38 [main] [INFO ] c.z.h.HikariDataSource [] - hugegraph-hubble-HikariCP - Start completed.
2023-08-30 20:38:41 [main] [INFO ] o.a.c.h.Http11NioProtocol [] - Starting ProtocolHandler ["http-nio-0.0.0.0-8088"]
2023-08-30 20:38:41 [main] [INFO ] o.a.h.HugeGraphHubble [] - Started HugeGraphHubble in 7.379 seconds (JVM running for 8.499)
然后使用浏览器访问 ip:8088 可看到hubble页面,通过bin/stop-hubble.sh则可以停止服务
2.3 源码编译
注意: 目前已在 hugegraph-hubble/hubble-be/pom.xml 中引入插件 frontend-maven-plugin,编译 hubble 时不需要用户本地环境提前安装 Nodejs V16.x 与 yarn 环境,可直接按下述步骤执行
下载 toolchain 源码包
git clone https://github.com/apache/hugegraph-toolchain.git
编译hubble, 它依赖 loader 和 client, 编译时需提前构建这些依赖 (后续可跳)
cd hugegraph-toolchain
sudo pip install -r hugegraph-hubble/hubble-dist/assembly/travis/requirements.txt
mvn install -pl hugegraph-client,hugegraph-loader -am -Dmaven.javadoc.skip=true -DskipTests -ntp
cd hugegraph-hubble
mvn -e package -Dmaven.javadoc.skip=true -Dmaven.test.skip=true -ntp
cd apache-hugegraph-hubble-incubating*
启动hubble
bin/start-hubble.sh -d
3 平台使用流程
平台的模块使用流程如下:

4 平台使用说明
4.1 图管理
4.1.1 图创建
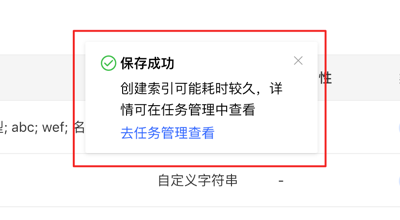
图管理模块下,点击【创建图】,通过填写图 ID、图名称、主机名、端口号、用户名、密码的信息,实现多图的连接。
创建图填写内容如下:
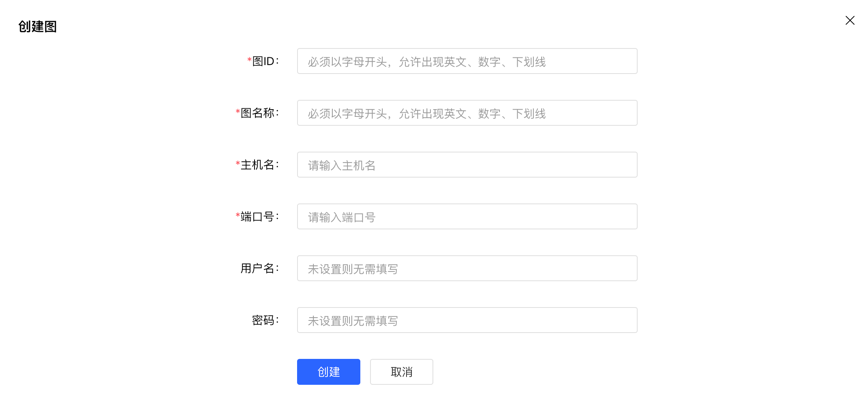
注意:如果使用 docker 启动
hubble,且server和hubble位于同一宿主机,不能直接使用localhost/127.0.0.1作为主机名。如果hubble和server在同一 docker 网络下,则可以直接使用 container_name 作为主机名,端口则为 8080。或者也可以使用宿主机 ip 作为主机名,此时端口为宿主机为 server 配置的端口
4.1.2 图访问
实现图空间的信息访问,进入后,可进行图的多维查询分析、元数据管理、数据导入、算法分析等操作。

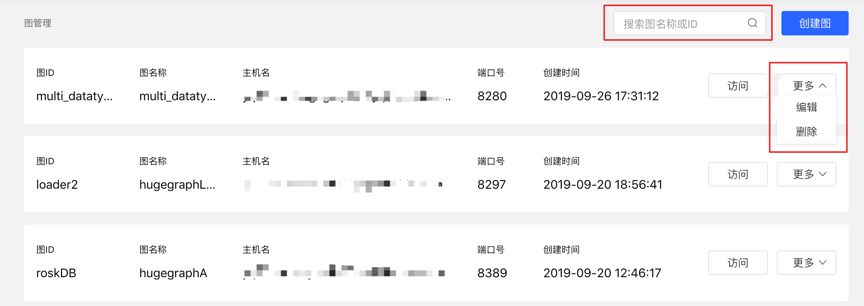
4.1.3 图管理
- 用户通过对图的概览、搜索以及单图的信息编辑与删除,实现图的统一管理。
- 搜索范围:可对图名称和 ID 进行搜索。
4.2 元数据建模(列表 + 图模式)
4.2.1 模块入口
左侧导航处:
4.2.2 属性类型
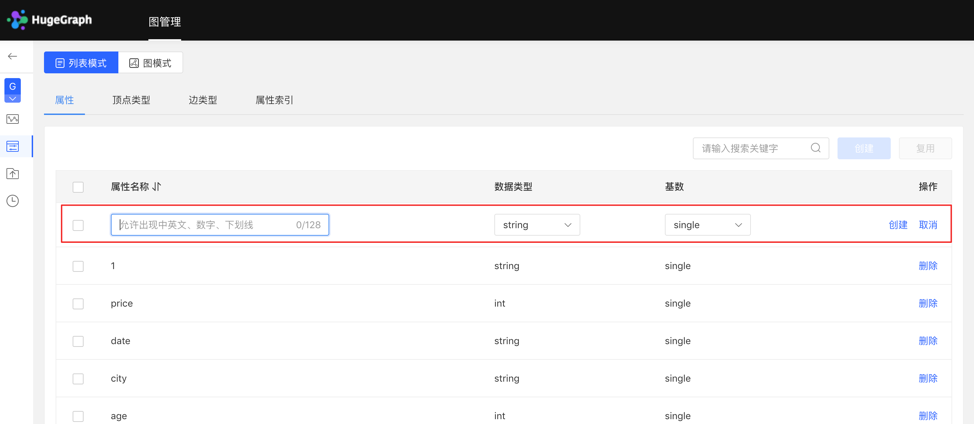
4.2.2.1 创建
- 填写或选择属性名称、数据类型、基数,完成属性的创建。
- 创建的属性可作为顶点类型和边类型的属性。
列表模式:
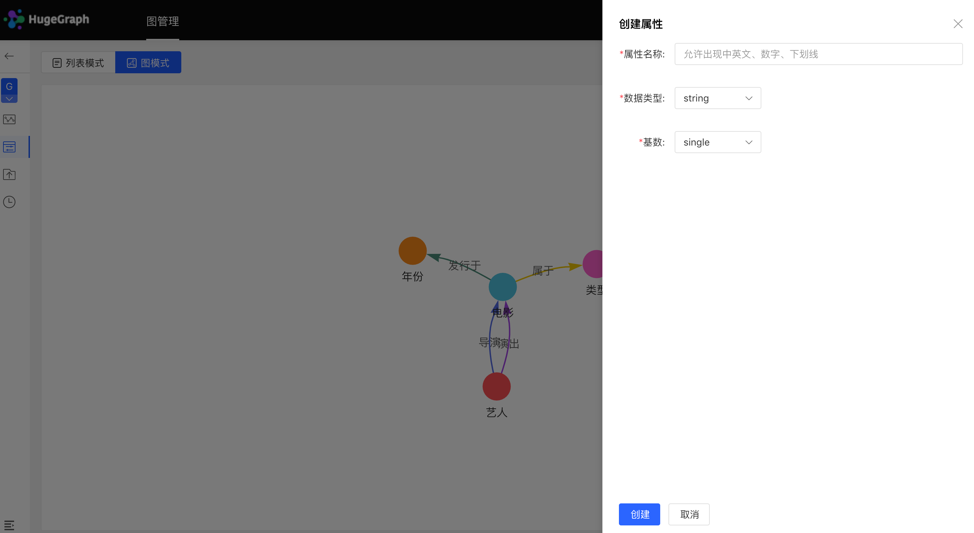
图模式:
4.2.2.2 复用
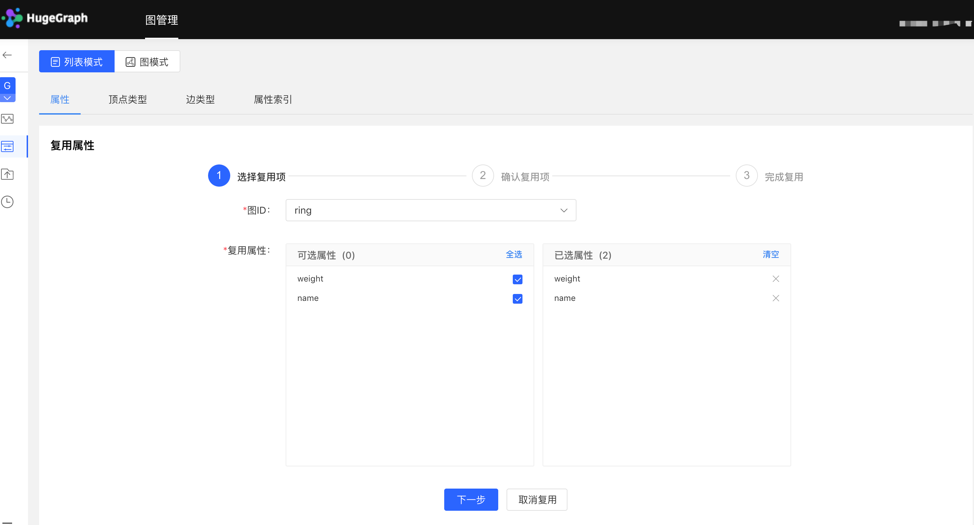
- 平台提供【复用】功能,可直接复用其他图的元数据。
- 选择需要复用的图 ID,继续选择需要复用的属性,之后平台会进行是否冲突的校验,通过后,可实现元数据的复用。
选择复用项:
校验复用项:
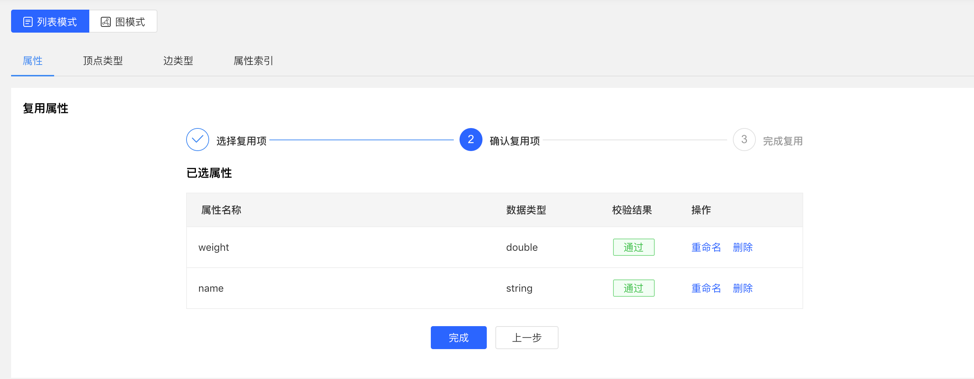
4.2.2.3 管理
- 在属性列表中可进行单条删除或批量删除操作。
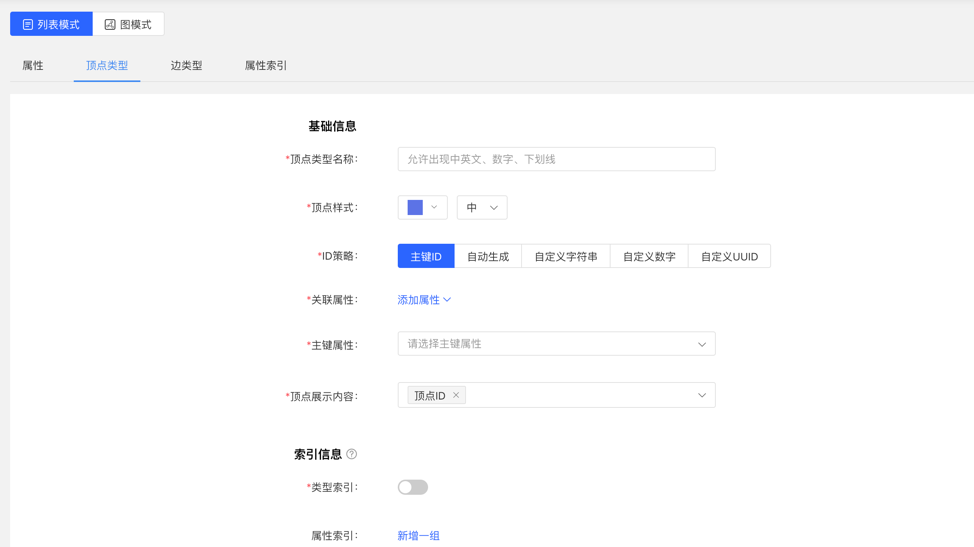
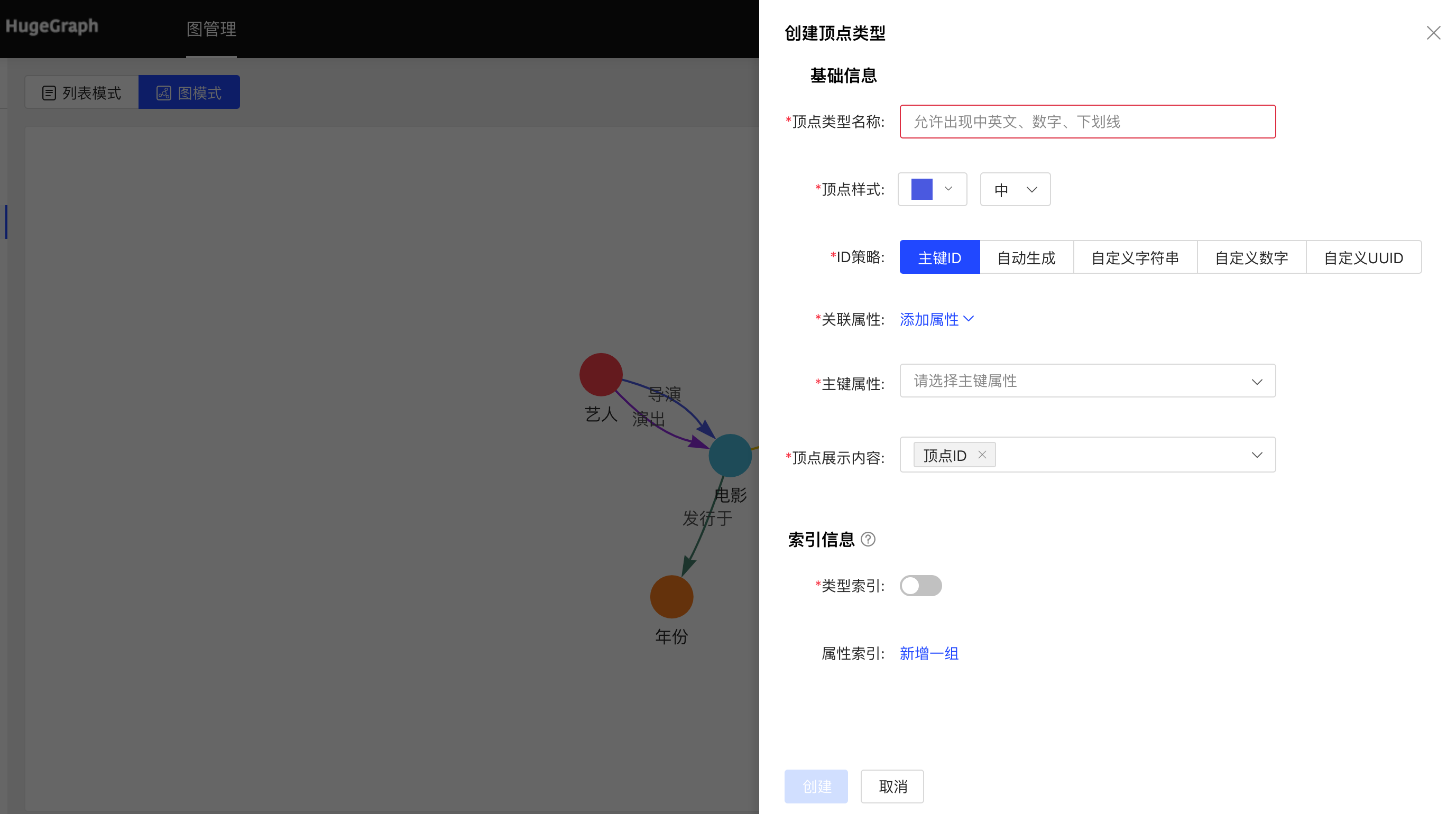
4.2.3 顶点类型
4.2.3.1 创建
- 填写或选择顶点类型名称、ID 策略、关联属性、主键属性,顶点样式、查询结果中顶点下方展示的内容,以及索引的信息:包括是否创建类型索引,及属性索引的具体内容,完成顶点类型的创建。
列表模式:
图模式:
4.2.3.2 复用
- 顶点类型的复用,会将此类型关联的属性和属性索引一并复用。
- 复用功能使用方法类似属性的复用,见 3.2.2.2。
4.2.3.3 管理
可进行编辑操作,顶点样式、关联类型、顶点展示内容、属性索引可编辑,其余不可编辑。
可进行单条删除或批量删除操作。
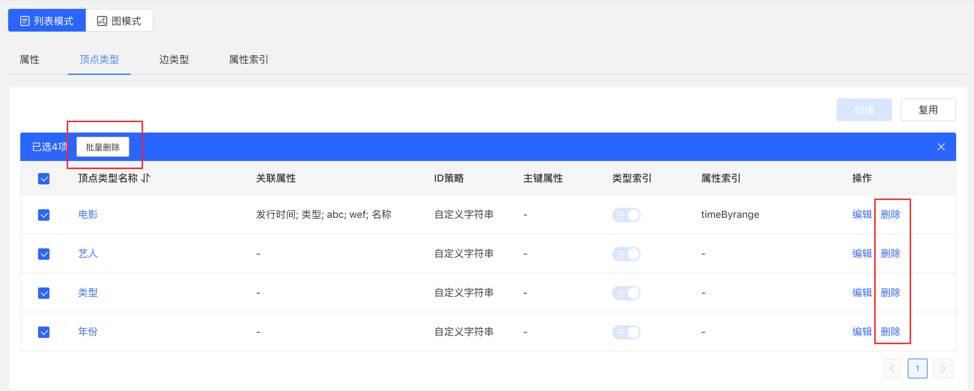
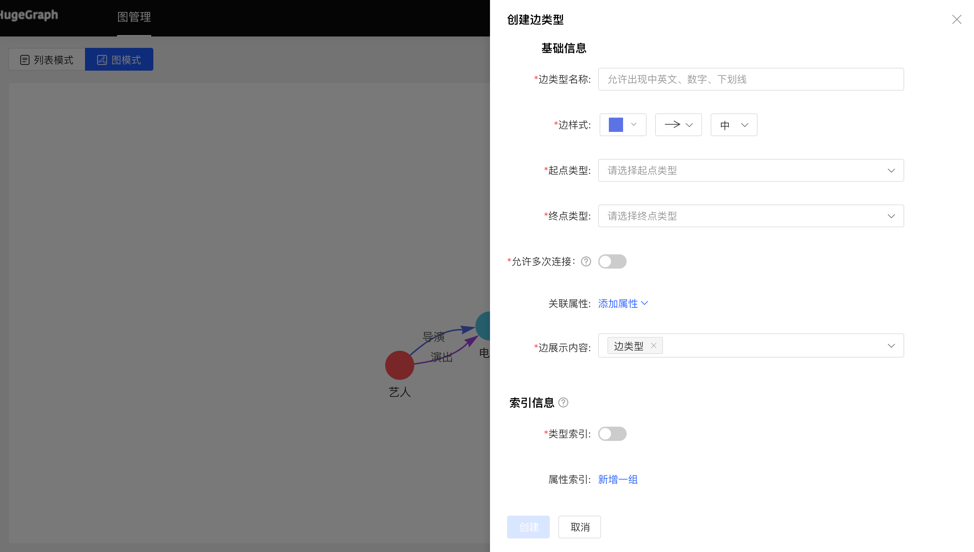
4.2.4 边类型
4.2.4.1 创建
- 填写或选择边类型名称、起点类型、终点类型、关联属性、是否允许多次连接、边样式、查询结果中边下方展示的内容,以及索引的信息:包括是否创建类型索引,及属性索引的具体内容,完成边类型的创建。
列表模式:
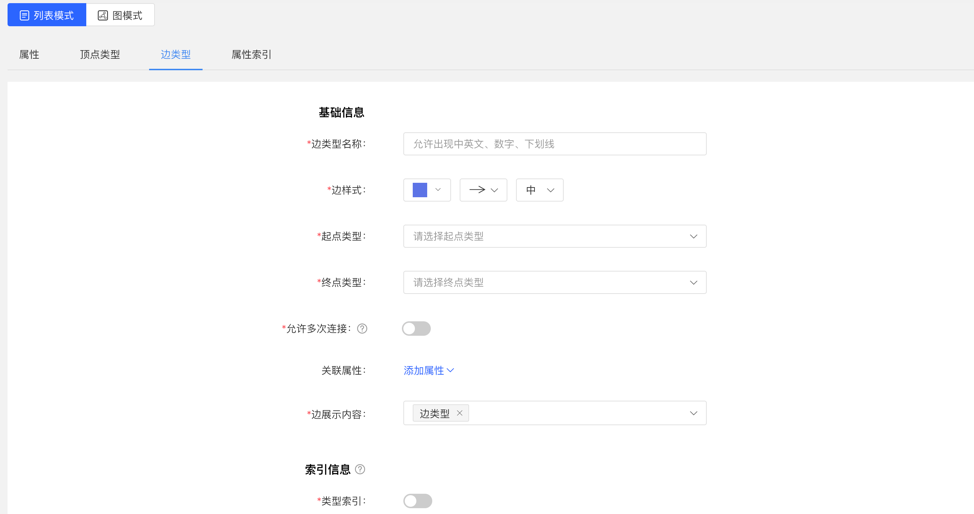
图模式:
4.2.4.2 复用
- 边类型的复用,会将此类型的起点类型、终点类型、关联的属性和属性索引一并复用。
- 复用功能使用方法类似属性的复用,见 3.2.2.2。
4.2.4.3 管理
- 可进行编辑操作,边样式、关联属性、边展示内容、属性索引可编辑,其余不可编辑,同顶点类型。
- 可进行单条删除或批量删除操作。
4.2.5 索引类型
展示顶点类型和边类型的顶点索引和边索引。
4.3 数据导入
注意:目前推荐使用 hugegraph-loader 进行正式数据导入,hubble 内置的导入用来做测试和简单上手
数据导入的使用流程如下:

4.3.1 模块入口
左侧导航处:
4.3.2 创建任务
- 填写任务名称和备注(非必填),可以创建导入任务。
- 可创建多个导入任务,并行导入。
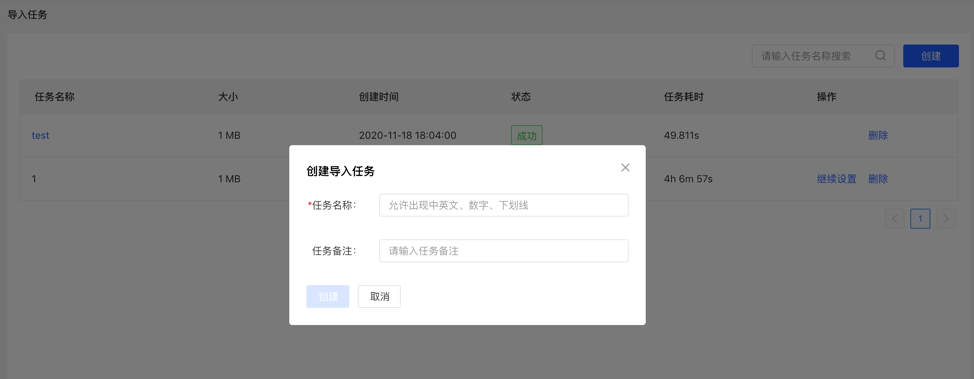
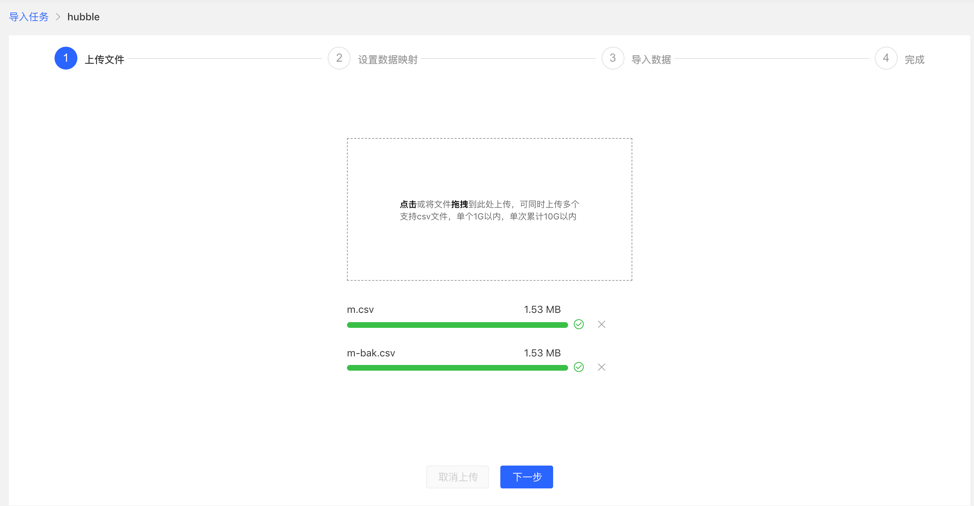
4.3.3 上传文件
- 上传需要构图的文件,目前支持的格式为 CSV,后续会不断更新。
- 可同时上传多个文件。
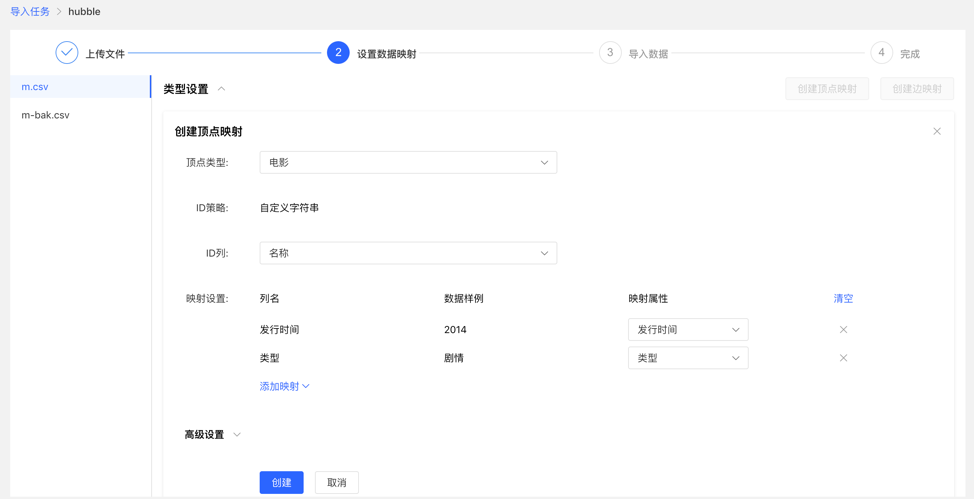
4.3.4 设置数据映射
对上传的文件分别设置数据映射,包括文件设置和类型设置
文件设置:勾选或填写是否包含表头、分隔符、编码格式等文件本身的设置内容,均设置默认值,无需手动填写
类型设置:
顶点映射和边映射:
【顶点类型】 :选择顶点类型,并为其 ID 映射上传文件中列数据;
【边类型】:选择边类型,为其起点类型和终点类型的 ID 列映射上传文件的列数据;
映射设置:为选定的顶点类型的属性映射上传文件中的列数据,此处,若属性名称与文件的表头名称一致,可自动匹配映射属性,无需手动填选
完成设置后,显示设置列表,方可进行下一步操作,支持映射的新增、编辑、删除操作
设置映射的填写内容:
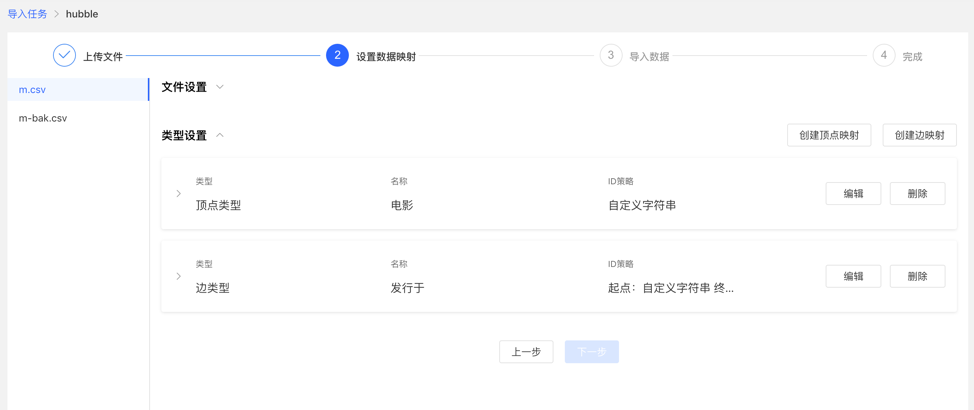
映射列表:
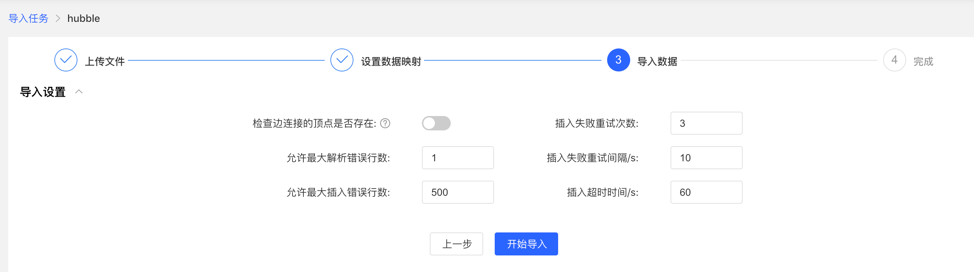
4.3.5 导入数据
导入前需要填写导入设置参数,填写完成后,可开始向图库中导入数据
- 导入设置
- 导入设置参数项如下图所示,均设置默认值,无需手动填写
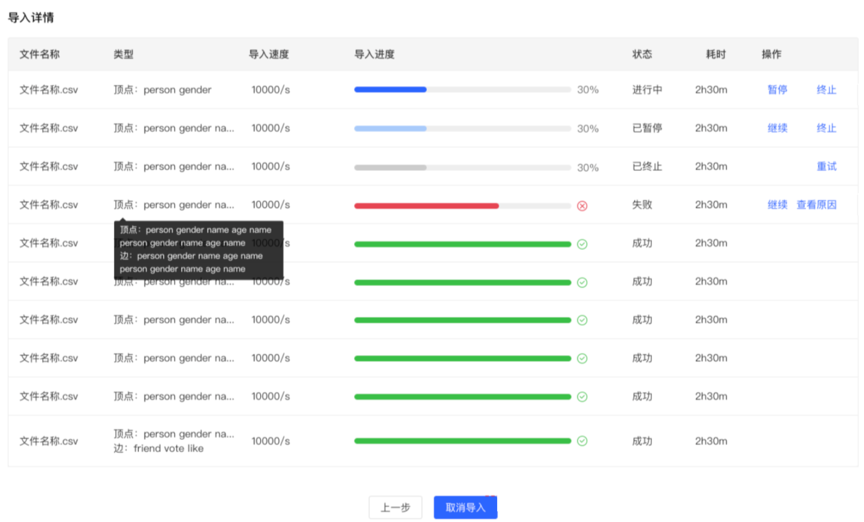
- 导入详情
- 点击开始导入,开始文件的导入任务
- 导入详情中提供每个上传文件设置的映射类型、导入速度、导入的进度、耗时以及当前任务的具体状态,并可对每个任务进行暂停、继续、停止等操作
- 若导入失败,可查看具体原因
4.4 数据分析
4.4.1 模块入口
左侧导航处:
4.4.2 多图切换
通过左侧切换入口,灵活切换多图的操作空间
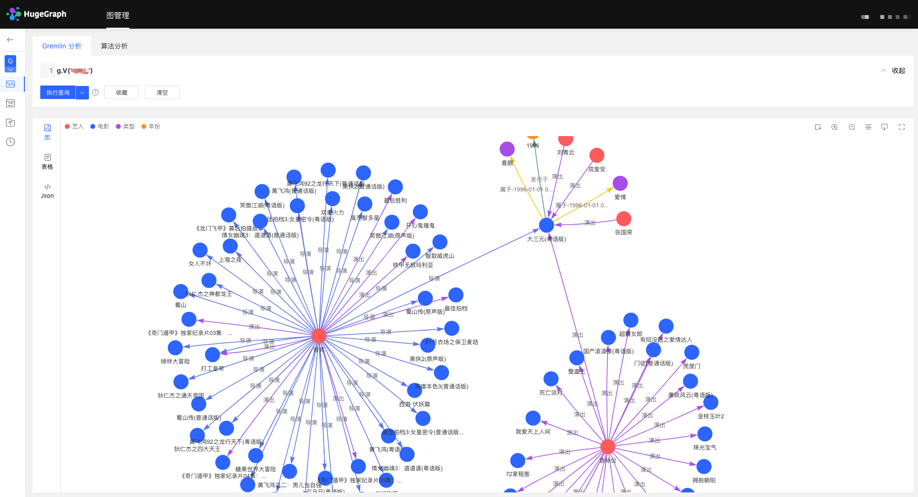
4.4.3 图分析与处理
HugeGraph 支持 Apache TinkerPop3 的图遍历查询语言 Gremlin,Gremlin 是一种通用的图数据库查询语言,通过输入 Gremlin 语句,点击执行,即可执行图数据的查询分析操作,并可实现顶点/边的创建及删除、顶点/边的属性修改等。
Gremlin 查询后,下方为图结果展示区域,提供 3 种图结果展示方式,分别为:【图模式】、【表格模式】、【Json 模式】。
支持缩放、居中、全屏、导出等操作。
【图模式】
【表格模式】
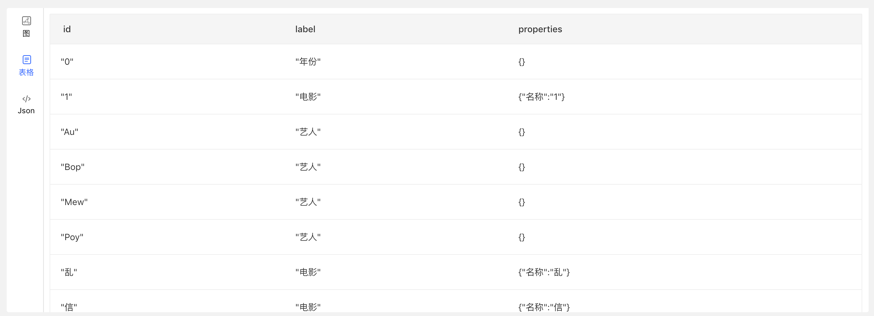
【Json 模式】

4.4.4 数据详情
点击顶点/边实体,可查看顶点/边的数据详情,包括:顶点/边类型,顶点 ID,属性及对应值,拓展图的信息展示维度,提高易用性。
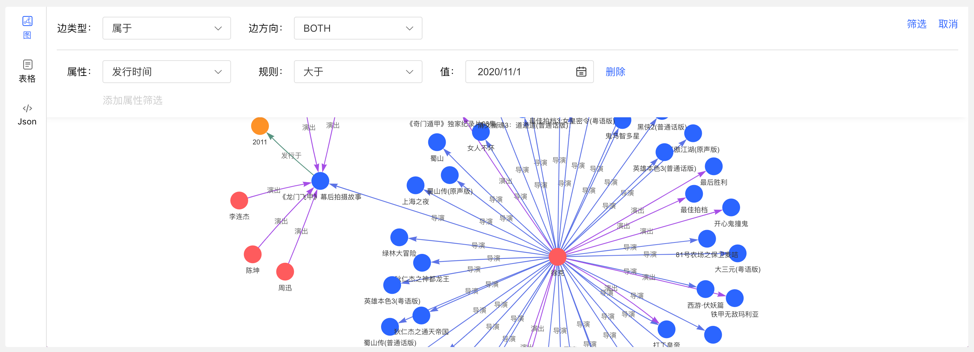
4.4.5 图结果的多维路径查询
除了全局的查询外,可针对查询结果中的顶点进行深度定制化查询以及隐藏操作,实现图结果的定制化挖掘。
右击顶点,出现顶点的菜单入口,可进行展示、查询、隐藏等操作。
- 展开:点击后,展示与选中点关联的顶点。
- 查询:通过选择与选中点关联的边类型及边方向,在此条件下,再选择其属性及相应筛选规则,可实现定制化的路径展示。
- 隐藏:点击后,隐藏选中点及与之关联的边。
双击顶点,也可展示与选中点关联的顶点。
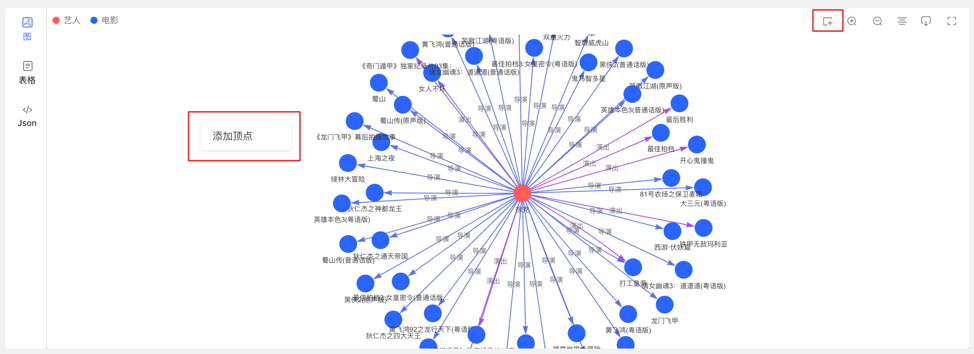
4.4.6 新增顶点/边
4.4.6.1 新增顶点
在图区可通过两个入口,动态新增顶点,如下:
- 点击图区面板,出现添加顶点入口
- 点击右上角的操作栏中的首个图标
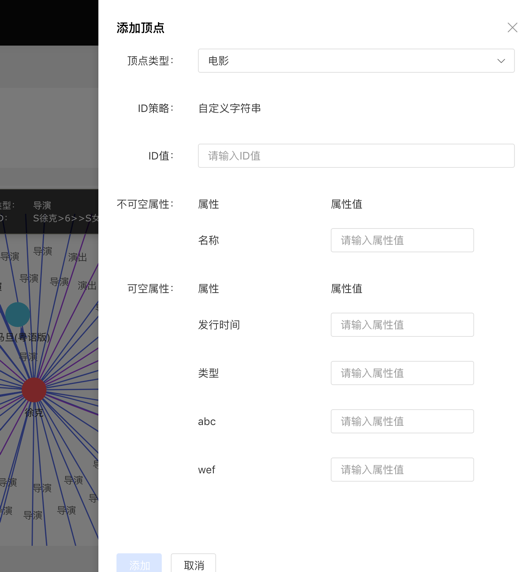
通过选择或填写顶点类型、ID 值、属性信息,完成顶点的增加。
入口如下:
添加顶点内容如下:
4.4.6.2 新增边
右击图结果中的顶点,可增加该点的出边或者入边。
4.4.7 执行记录与收藏的查询
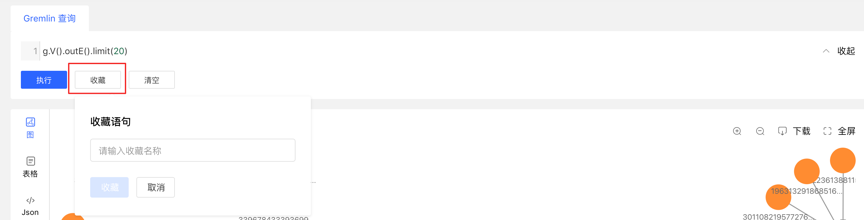
- 图区下方记载每次查询记录,包括:查询时间、执行类型、内容、状态、耗时、以及【收藏】和【加载】操作,实现图执行的全方位记录,有迹可循,并可对执行内容快速加载复用
- 提供语句的收藏功能,可对常用语句进行收藏操作,方便高频语句快速调用
4.5 任务管理
4.5.1 模块入口
左侧导航处:
4.5.2 任务管理
- 提供异步任务的统一的管理与结果查看,异步任务包括 4 类,分别为:
- gremlin:Gremlin 任务务
- algorithm:OLAP 算法任务务
- remove_schema:删除元数据
- rebuild_index:重建索引
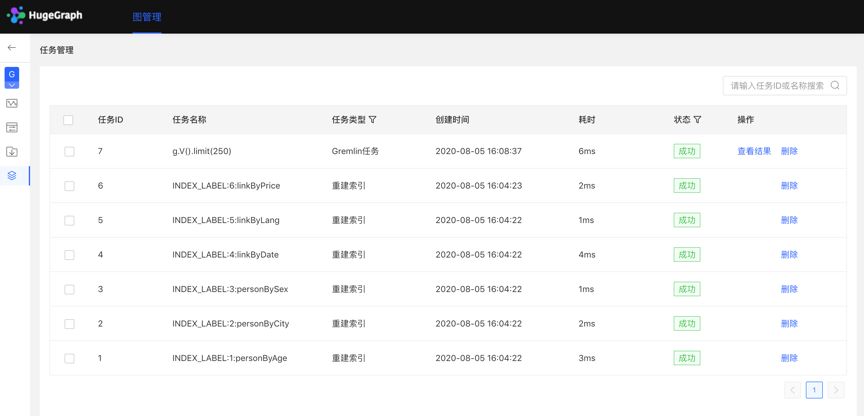
- 列表显示当前图的异步任务信息,包括:任务 ID,任务名称,任务类型,创建时间,耗时,状态,操作,实现对异步任务的管理。
- 支持对任务类型和状态进行筛选
- 支持搜索任务 ID 和任务名称
- 可对异步任务进行删除或批量删除操作
4.5.3 Gremlin 异步任务
1.创建任务
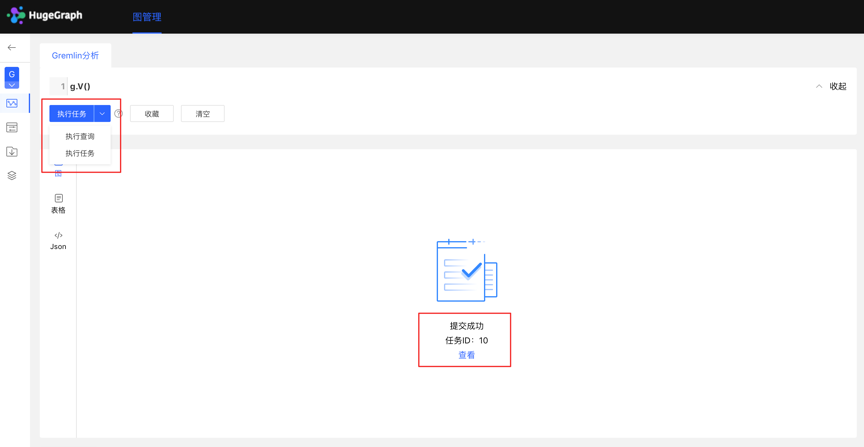
- 数据分析模块,目前支持两种 Gremlin 操作,Gremlin 查询和 Gremlin 任务;若用户切换到 Gremlin 任务,点击执行后,在异步任务中心会建立一条异步任务; 2.任务提交
- 任务提交成功后,图区部分返回提交结果和任务 ID 3.任务详情
- 提供【查看】入口,可跳转到任务详情查看当前任务具体执行情况跳转到任务中心后,直接显示当前执行的任务行
点击查看入口,跳转到任务管理列表,如下:
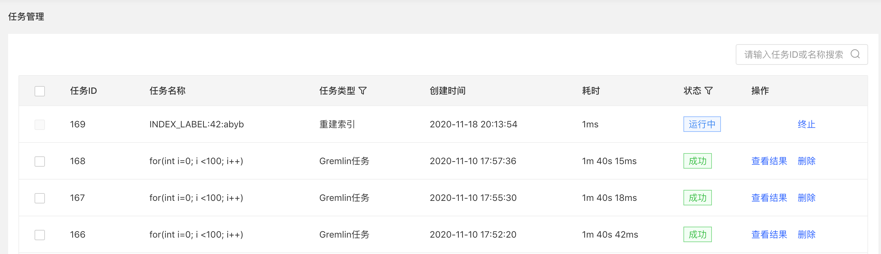
4.查看结果
- 结果通过 json 形式展示
4.5.4 OLAP 算法任务
Hubble 上暂未提供可视化的 OLAP 算法执行,可调用 RESTful API 进行 OLAP 类算法任务,在任务管理中通过 ID 找到相应任务,查看进度与结果等。
4.5.5 删除元数据、重建索引
1.创建任务
- 在元数据建模模块中,删除元数据时,可建立删除元数据的异步任务
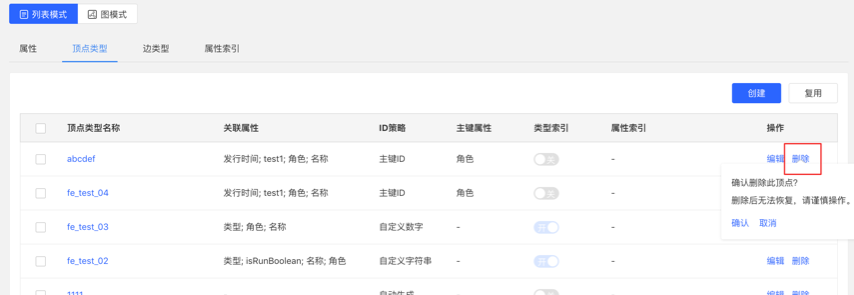
- 在编辑已有的顶点/边类型操作中,新增索引时,可建立创建索引的异步任务
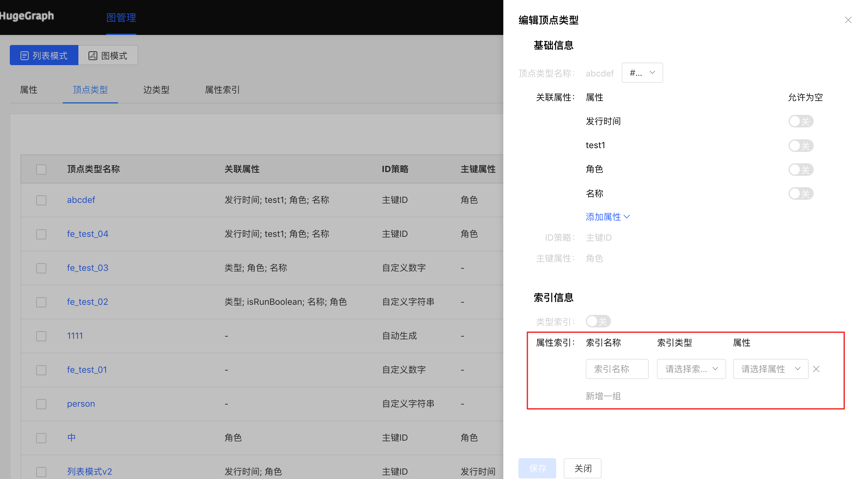
2.任务详情
- 确认/保存后,可跳转到任务中心查看当前任务的详情