HugeGraph-Loader Quick Start
1 HugeGraph-Loader 概述
HugeGraph-Loader 是 HugeGraph 的数据导入组件,能够将多种数据源的数据转化为图的顶点和边并批量导入到图数据库中。
目前支持的数据源包括:
- 本地磁盘文件或目录,支持 TEXT、CSV 和 JSON 格式的文件,支持压缩文件
- HDFS 文件或目录,支持压缩文件
- 主流关系型数据库,如 MySQL、PostgreSQL、Oracle、SQL Server
本地磁盘文件和 HDFS 文件支持断点续传。
后面会具体说明。
注意:使用 HugeGraph-Loader 需要依赖 HugeGraph Server 服务,下载和启动 Server 请参考 HugeGraph-Server Quick Start
2 获取 HugeGraph-Loader
有两种方式可以获取 HugeGraph-Loader:
- 使用 Docker 镜像 (便于测试)
- 下载已编译的压缩包
- 克隆源码编译安装
2.1 使用 Docker 镜像 (便于测试)
我们可以使用 docker run -itd --name loader hugegraph/loader:1.5.0 部署 loader 服务。对于需要加载的数据,则可以通过挂载 -v /path/to/data/file:/loader/file 或者 docker cp 的方式将文件复制到 loader 容器内部。
或者使用 docker-compose 启动 loader, 启动命令为 docker-compose up -d, 样例的 docker-compose.yml 如下所示:
version: '3'
services:
server:
image: hugegraph/hugegraph:1.5.0
container_name: server
ports:
- 8080:8080
hubble:
image: hugegraph/hubble:1.5.0
container_name: hubble
ports:
- 8088:8088
loader:
image: hugegraph/loader:1.5.0
container_name: loader
# mount your own data here
# volumes:
# - /path/to/data/file:/loader/file
具体的数据导入流程可以参考 4.5 使用 docker 导入
注意:
hugegraph-loader 的 docker 镜像是一个便捷版本,用于快速启动 loader,并不是官方发布物料包方式。你可以从 ASF Release Distribution Policy 中得到更多细节。
推荐使用
release tag(如1.5.0) 以获取稳定版。使用latesttag 可以使用开发中的最新功能。
2.2 下载已编译的压缩包
下载最新版本的 HugeGraph-Toolchain Release 包,里面包含了 loader + tool + hubble 全套工具,如果你已经下载,可跳过重复步骤
wget https://downloads.apache.org/incubator/hugegraph/{version}/apache-hugegraph-toolchain-incubating-{version}.tar.gz
tar zxf *hugegraph*.tar.gz
2.3 克隆源码编译安装
克隆最新版本的 HugeGraph-Loader 源码包:
# 1. get from github
git clone https://github.com/apache/hugegraph-toolchain.git
# 2. get from direct url (please choose the **latest release** version)
wget https://downloads.apache.org/incubator/hugegraph/{version}/apache-hugegraph-toolchain-incubating-{version}-src.tar.gz
点击展开/折叠 手动安装 ojdbc 方法
由于 Oracle ojdbc license 的限制,需要手动安装 ojdbc 到本地 maven 仓库。 访问 Oracle jdbc 下载 页面。选择 Oracle Database 12c Release 2 (12.2.0.1) drivers,如下图所示。
打开链接后,选择“ojdbc8.jar”
把 ojdbc8 安装到本地 maven 仓库,进入ojdbc8.jar所在目录,执行以下命令。
mvn install:install-file -Dfile=./ojdbc8.jar -DgroupId=com.oracle -DartifactId=ojdbc8 -Dversion=12.2.0.1 -Dpackaging=jar
编译生成 tar 包:
cd hugegraph-loader
mvn clean package -DskipTests
3 使用流程
使用 HugeGraph-Loader 的基本流程分为以下几步:
- 编写图模型
- 准备数据文件
- 编写输入源映射文件
- 执行命令导入
3.1 编写图模型
这一步是建模的过程,用户需要对自己已有的数据和想要创建的图模型有一个清晰的构想,然后编写 schema 建立图模型。
比如想创建一个拥有两类顶点及两类边的图,顶点是"人"和"软件",边是"人认识人"和"人创造软件",并且这些顶点和边都带有一些属性,比如顶点"人"有:“姓名”、“年龄"等属性, “软件"有:“名字”、“售卖价格"等属性;边"认识"有:“日期"属性等。
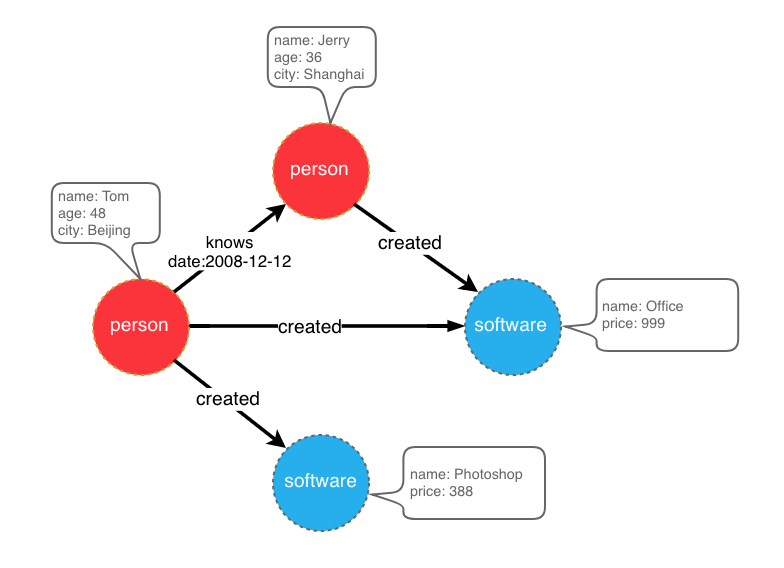
示例图模型
在设计好了图模型之后,我们可以用groovy编写出schema的定义,并保存至文件中,这里命名为schema.groovy。
// 创建一些属性
schema.propertyKey("name").asText().ifNotExist().create();
schema.propertyKey("age").asInt().ifNotExist().create();
schema.propertyKey("city").asText().ifNotExist().create();
schema.propertyKey("date").asText().ifNotExist().create();
schema.propertyKey("price").asDouble().ifNotExist().create();
// 创建 person 顶点类型,其拥有三个属性:name, age, city,主键是 name
schema.vertexLabel("person").properties("name", "age", "city").primaryKeys("name").ifNotExist().create();
// 创建 software 顶点类型,其拥有两个属性:name, price,主键是 name
schema.vertexLabel("software").properties("name", "price").primaryKeys("name").ifNotExist().create();
// 创建 knows 边类型,这类边是从 person 指向 person 的
schema.edgeLabel("knows").sourceLabel("person").targetLabel("person").ifNotExist().create();
// 创建 created 边类型,这类边是从 person 指向 software 的
schema.edgeLabel("created").sourceLabel("person").targetLabel("software").ifNotExist().create();
关于 schema 的详细说明请参考 hugegraph-client 中对应部分。
3.2 准备数据
目前 HugeGraph-Loader 支持的数据源包括:
- 本地磁盘文件或目录
- HDFS 文件或目录
- 部分关系型数据库
- Kafka topic
3.2.1 数据源结构
3.2.1.1 本地磁盘文件或目录
用户可以指定本地磁盘文件作为数据源,如果数据分散在多个文件中,也支持以某个目录作为数据源,但暂时不支持以多个目录作为数据源。
比如:我的数据分散在多个文件中,part-0、part-1 … part-n,要想执行导入,必须保证它们是放在一个目录下的。然后在 loader 的映射文件中,将path指定为该目录即可。
支持的文件格式包括:
- TEXT
- CSV
- JSON
TEXT 是自定义分隔符的文本文件,第一行通常是标题,记录了每一列的名称,也允许没有标题行(在映射文件中指定)。其余的每行代表一条记录,会被转化为一个顶点/边;行的每一列对应一个字段,会被转化为顶点/边的 id、label 或属性;
示例如下:
id|name|lang|price|ISBN
1|lop|java|328|ISBN978-7-107-18618-5
2|ripple|java|199|ISBN978-7-100-13678-5
CSV 是分隔符为逗号,的 TEXT 文件,当列值本身包含逗号时,该列值需要用双引号包起来,如:
marko,29,Beijing
"li,nary",26,"Wu,han"
JSON 文件要求每一行都是一个 JSON 串,且每行的格式需保持一致。
{"source_name": "marko", "target_name": "vadas", "date": "20160110", "weight": 0.5}
{"source_name": "marko", "target_name": "josh", "date": "20130220", "weight": 1.0}
3.2.1.2 HDFS 文件或目录
用户也可以指定 HDFS 文件或目录作为数据源,上面关于本地磁盘文件或目录的要求全部适用于这里。除此之外,鉴于 HDFS 上通常存储的都是压缩文件,loader 也提供了对压缩文件的支持,并且本地磁盘文件或目录同样支持压缩文件。
目前支持的压缩文件类型包括:GZIP、BZ2、XZ、LZMA、SNAPPY_RAW、SNAPPY_FRAMED、Z、DEFLATE、LZ4_BLOCK、LZ4_FRAMED、ORC 和 PARQUET。
3.2.1.3 主流关系型数据库
loader 还支持以部分关系型数据库作为数据源,目前支持 MySQL、PostgreSQL、Oracle 和 SQL Server。
但目前对表结构要求较为严格,如果导入过程中需要做关联查询,这样的表结构是不允许的。关联查询的意思是:在读到表的某行后,发现某列的值不能直接使用(比如外键),需要再去做一次查询才能确定该列的真实值。
举个例子:假设有三张表,person、software 和 created
// person 表结构
id | name | age | city
// software 表结构
id | name | lang | price
// created 表结构
id | p_id | s_id | date
如果在建模(schema)时指定 person 或 software 的 id 策略是 PRIMARY_KEY,选择以 name 作为 primary keys(注意:这是 hugegraph 中 vertexlabel 的概念),在导入边数据时,由于需要拼接出源顶点和目标顶点的 id,必须拿着 p_id/s_id 去 person/software 表中查到对应的 name,这种需要做额外查询的表结构的情况,loader 暂时是不支持的。这时可以采用以下两种方式替代:
- 仍然指定 person 和 software 的 id 策略为 PRIMARY_KEY,但是以 person 表和 software 表的 id 列作为顶点的主键属性,这样导入边时直接使用 p_id 和 s_id 和顶点的 label 拼接就能生成 id 了;
- 指定 person 和 software 的 id 策略为 CUSTOMIZE,然后直接以 person 表和 software 表的 id 列作为顶点 id,这样导入边时直接使用 p_id 和 s_id 即可;
关键点就是要让边能直接使用 p_id 和 s_id,不要再去查一次。
3.2.2 准备顶点和边数据
3.2.2.1 顶点数据
顶点数据文件由一行一行的数据组成,一般每一行作为一个顶点,每一列会作为顶点属性。下面以 CSV 格式作为示例进行说明。
- person 顶点数据(数据本身不包含 header)
Tom,48,Beijing
Jerry,36,Shanghai
- software 顶点数据(数据本身包含 header)
name,price
Photoshop,999
Office,388
3.2.2.2 边数据
边数据文件由一行一行的数据组成,一般每一行作为一条边,其中有部分列会作为源顶点和目标顶点的 id,其他列作为边属性。下面以 JSON 格式作为示例进行说明。
- knows 边数据
{"source_name": "Tom", "target_name": "Jerry", "date": "2008-12-12"}
- created 边数据
{"source_name": "Tom", "target_name": "Photoshop"}
{"source_name": "Tom", "target_name": "Office"}
{"source_name": "Jerry", "target_name": "Office"}
3.3 编写数据源映射文件
3.3.1 映射文件概述
输入源的映射文件用于描述如何将输入源数据与图的顶点类型/边类型建立映射关系,以JSON格式组织,由多个映射块组成,其中每一个映射块都负责将一个输入源映射为顶点和边。
具体而言,每个映射块包含一个输入源和多个顶点映射与边映射块,输入源块对应上面介绍的本地磁盘文件或目录、HDFS 文件或目录和关系型数据库,负责描述数据源的基本信息,比如数据在哪,是什么格式的,分隔符是什么等。顶点映射/边映射与该输入源绑定,可以选择输入源的哪些列,哪些列作为 id、哪些列作为属性,以及每一列映射成什么属性,列的值映射成属性的什么值等等。
以最通俗的话讲,每一个映射块描述了:要导入的文件在哪,文件的每一行要作为哪一类顶点/边,文件的哪些列是需要导入的,以及这些列对应顶点/边的什么属性等。
注意:0.11.0 版本以前的映射文件与 0.11.0 以后的格式变化较大,为表述方便,下面称 0.11.0 以前的映射文件(格式)为 1.0 版本,0.11.0 以后的为 2.0 版本。并且若无特殊说明,“映射文件”表示的是 2.0 版本的。
点击展开/折叠 2.0 版本的映射文件的框架
{
"version": "2.0",
"structs": [
{
"id": "1",
"input": {
},
"vertices": [
{},
{}
],
"edges": [
{},
{}
]
}
]
}
这里直接给出两个版本的映射文件(描述了上面图模型和数据文件)
点击展开/折叠 2.0 版本的映射文件
{
"version": "2.0",
"structs": [
{
"id": "1",
"skip": false,
"input": {
"type": "FILE",
"path": "vertex_person.csv",
"file_filter": {
"extensions": [
"*"
]
},
"format": "CSV",
"delimiter": ",",
"date_format": "yyyy-MM-dd HH:mm:ss",
"time_zone": "GMT+8",
"skipped_line": {
"regex": "(^#|^//).*|"
},
"compression": "NONE",
"header": [
"name",
"age",
"city"
],
"charset": "UTF-8",
"list_format": {
"start_symbol": "[",
"elem_delimiter": "|",
"end_symbol": "]"
}
},
"vertices": [
{
"label": "person",
"skip": false,
"id": null,
"unfold": false,
"field_mapping": {},
"value_mapping": {},
"selected": [],
"ignored": [],
"null_values": [
""
],
"update_strategies": {}
}
],
"edges": []
},
{
"id": "2",
"skip": false,
"input": {
"type": "FILE",
"path": "vertex_software.csv",
"file_filter": {
"extensions": [
"*"
]
},
"format": "CSV",
"delimiter": ",",
"date_format": "yyyy-MM-dd HH:mm:ss",
"time_zone": "GMT+8",
"skipped_line": {
"regex": "(^#|^//).*|"
},
"compression": "NONE",
"header": null,
"charset": "UTF-8",
"list_format": {
"start_symbol": "",
"elem_delimiter": ",",
"end_symbol": ""
}
},
"vertices": [
{
"label": "software",
"skip": false,
"id": null,
"unfold": false,
"field_mapping": {},
"value_mapping": {},
"selected": [],
"ignored": [],
"null_values": [
""
],
"update_strategies": {}
}
],
"edges": []
},
{
"id": "3",
"skip": false,
"input": {
"type": "FILE",
"path": "edge_knows.json",
"file_filter": {
"extensions": [
"*"
]
},
"format": "JSON",
"delimiter": null,
"date_format": "yyyy-MM-dd HH:mm:ss",
"time_zone": "GMT+8",
"skipped_line": {
"regex": "(^#|^//).*|"
},
"compression": "NONE",
"header": null,
"charset": "UTF-8",
"list_format": null
},
"vertices": [],
"edges": [
{
"label": "knows",
"skip": false,
"source": [
"source_name"
],
"unfold_source": false,
"target": [
"target_name"
],
"unfold_target": false,
"field_mapping": {
"source_name": "name",
"target_name": "name"
},
"value_mapping": {},
"selected": [],
"ignored": [],
"null_values": [
""
],
"update_strategies": {}
}
]
},
{
"id": "4",
"skip": false,
"input": {
"type": "FILE",
"path": "edge_created.json",
"file_filter": {
"extensions": [
"*"
]
},
"format": "JSON",
"delimiter": null,
"date_format": "yyyy-MM-dd HH:mm:ss",
"time_zone": "GMT+8",
"skipped_line": {
"regex": "(^#|^//).*|"
},
"compression": "NONE",
"header": null,
"charset": "UTF-8",
"list_format": null
},
"vertices": [],
"edges": [
{
"label": "created",
"skip": false,
"source": [
"source_name"
],
"unfold_source": false,
"target": [
"target_name"
],
"unfold_target": false,
"field_mapping": {
"source_name": "name",
"target_name": "name"
},
"value_mapping": {},
"selected": [],
"ignored": [],
"null_values": [
""
],
"update_strategies": {}
}
]
}
]
}
点击展开/折叠 1.0 版本的映射文件
{
"vertices": [
{
"label": "person",
"input": {
"type": "file",
"path": "vertex_person.csv",
"format": "CSV",
"header": ["name", "age", "city"],
"charset": "UTF-8"
}
},
{
"label": "software",
"input": {
"type": "file",
"path": "vertex_software.csv",
"format": "CSV"
}
}
],
"edges": [
{
"label": "knows",
"source": ["source_name"],
"target": ["target_name"],
"input": {
"type": "file",
"path": "edge_knows.json",
"format": "JSON"
},
"field_mapping": {
"source_name": "name",
"target_name": "name"
}
},
{
"label": "created",
"source": ["source_name"],
"target": ["target_name"],
"input": {
"type": "file",
"path": "edge_created.json",
"format": "JSON"
},
"field_mapping": {
"source_name": "name",
"target_name": "name"
}
}
]
}
映射文件 1.0 版本是以顶点和边为中心,设置输入源;而 2.0 版本是以输入源为中心,设置顶点和边映射。有些输入源(比如一个文件)既能生成顶点,也能生成边,如果用 1.0 版的格式写,就需要在 vertex 和 edge 映射块中各写一次 input 块,这两次的 input 块是完全一样的;而 2.0 版本只需要写一次 input。所以 2.0 版相比于 1.0 版,能省掉一些 input 的重复书写。
在 hugegraph-loader-{version} 的 bin 目录下,有一个脚本工具 mapping-convert.sh 能直接将 1.0 版本的映射文件转换为 2.0 版本的,使用方式如下:
bin/mapping-convert.sh struct.json
会在 struct.json 的同级目录下生成一个 struct-v2.json。
3.3.2 输入源
输入源目前分为四类:FILE、HDFS、JDBC、KAFKA,由type节点区分,我们称为本地文件输入源、HDFS 输入源、JDBC 输入源和 KAFKA 输入源,下面分别介绍。
3.3.2.1 本地文件输入源
- id: 输入源的 id,该字段用于支持一些内部功能,非必填(未填时会自动生成),强烈建议写上,对于调试大有裨益;
- skip: 是否跳过该输入源,由于 JSON 文件无法添加注释,如果某次导入时不想导入某个输入源,但又不想删除该输入源的配置,则可以设置为 true 将其跳过,默认为 false,非必填;
- input: 输入源映射块,复合结构
- type: 输入源类型,必须填 file 或 FILE;
- path: 本地文件或目录的路径,绝对路径或相对于映射文件的相对路径,建议使用绝对路径,必填;
- file_filter: 从
path中筛选复合条件的文件,复合结构,目前只支持配置扩展名,用子节点extensions表示,默认为”*",表示保留所有文件; - format: 本地文件的格式,可选值为 CSV、TEXT 及 JSON,必须大写,必填;
- header: 文件各列的列名,如不指定则会以数据文件第一行作为 header;当文件本身有标题且又指定了 header,文件的第一行会被当作普通的数据行;JSON 文件不需要指定 header,选填;
- delimiter: 文件行的列分隔符,默认以逗号
","作为分隔符,JSON文件不需要指定,选填; - charset: 文件的编码字符集,默认
UTF-8,选填; - date_format: 自定义的日期格式,默认值为 yyyy-MM-dd HH:mm:ss,选填;如果日期是以时间戳的形式呈现的,此项须写为
timestamp(固定写法); - time_zone: 设置日期数据是处于哪个时区的,默认值为
GMT+8,选填; - skipped_line: 想跳过的行,复合结构,目前只能配置要跳过的行的正则表达式,用子节点
regex描述,默认不跳过任何行,选填; - compression: 文件的压缩格式,可选值为 NONE、GZIP、BZ2、XZ、LZMA、SNAPPY_RAW、SNAPPY_FRAMED、Z、DEFLATE、LZ4_BLOCK、LZ4_FRAMED、ORC 和 PARQUET,默认为 NONE,表示非压缩文件,选填;
- list_format: 当文件 (非 JSON ) 的某列是集合结构时(对应图中的 PropertyKey 的 Cardinality 为 Set 或 List),可以用此项设置该列的起始符、分隔符、结束符,复合结构:
- start_symbol: 集合结构列的起始符 (默认值是
[, JSON 格式目前不支持指定) - elem_delimiter: 集合结构列的分隔符 (默认值是
|, JSON 格式目前只支持原生,分隔) - end_symbol: 集合结构列的结束符 (默认值是
], JSON 格式目前不支持指定)
- start_symbol: 集合结构列的起始符 (默认值是
3.3.2.2 HDFS 输入源
上述本地文件输入源的节点及含义这里基本都适用,下面仅列出 HDFS 输入源不一样的和特有的节点。
- type: 输入源类型,必须填 hdfs 或 HDFS,必填;
- path: HDFS 文件或目录的路径,必须是 HDFS 的绝对路径,必填;
- core_site_path: HDFS 集群的 core-site.xml 文件路径,重点要指明 NameNode 的地址(
fs.default.name),以及文件系统的实现(fs.hdfs.impl);
3.3.2.3 JDBC 输入源
前面说到过支持多种关系型数据库,但由于它们的映射结构非常相似,故统称为 JDBC 输入源,然后用vendor节点区分不同的数据库。
- type: 输入源类型,必须填 jdbc 或 JDBC,必填;
- vendor: 数据库类型,可选项为 [MySQL、PostgreSQL、Oracle、SQLServer],不区分大小写,必填;
- driver: jdbc 使用的 driver 类型,必填;
- url: jdbc 要连接的数据库的 url,必填;
- database: 要连接的数据库名,必填;
- schema: 要连接的 schema 名,不同的数据库要求不一样,下面详细说明;
- table: 要连接的表名,
custom_sql和table参数必须填其中一个; - custom_sql: 自定义 SQL 语句,
custom_sql和table参数必须填其中一个; - username: 连接数据库的用户名,必填;
- password: 连接数据库的密码,必填;
- batch_size: 按页获取表数据时的一页的大小,默认为 500,选填;
MYSQL
| 节点 | 固定值或常见值 |
|---|---|
| vendor | MYSQL |
| driver | com.mysql.cj.jdbc.Driver |
| url | jdbc:mysql://127.0.0.1:3306 |
schema: 可空,若填写必须与 database 的值一样
POSTGRESQL
| 节点 | 固定值或常见值 |
|---|---|
| vendor | POSTGRESQL |
| driver | org.postgresql.Driver |
| url | jdbc:postgresql://127.0.0.1:5432 |
schema: 可空,默认值为“public”
ORACLE
| 节点 | 固定值或常见值 |
|---|---|
| vendor | ORACLE |
| driver | oracle.jdbc.driver.OracleDriver |
| url | jdbc:oracle:thin:@127.0.0.1:1521 |
schema: 可空,默认值与用户名相同
SQLSERVER
| 节点 | 固定值或常见值 |
|---|---|
| vendor | SQLSERVER |
| driver | com.microsoft.sqlserver.jdbc.SQLServerDriver |
| url | jdbc:sqlserver://127.0.0.1:1433 |
schema: 必填
3.3.2.4 Kafka 输入源
- type:输入源类型,必须填
kafka或KAFKA,必填; - bootstrap_server:设置 kafka bootstrap server 列表;
- topic:订阅的 topic;
- group:Kafka 消费者组;
- from_beginning:设置是否从头开始读取;
- format:本地文件的格式,可选值为 CSV、TEXT 及 JSON,必须大写,必填;
- header:文件各列的列名,如不指定则会以数据文件第一行作为 header;当文件本身有标题且又指定了 header,文件的第一行会被当作普通的数据行;JSON 文件不需要指定 header,选填;
- delimiter:文件行的列分隔符,默认以逗号”,“作为分隔符,JSON 文件不需要指定,选填;
- charset:文件的编码字符集,默认 UTF-8,选填;
- date_format:自定义的日期格式,默认值为 yyyy-MM-dd HH:mm:ss,选填;如果日期是以时间戳的形式呈现的,此项须写为 timestamp(固定写法);
- extra_date_formats:自定义的其他日期格式列表,默认为空,选填;列表中每一项都是一个 date_format 指定日期格式的备用日期格式;
- time_zone:置日期数据是处于哪个时区的,默认值为 GMT+8,选填;
- skipped_line:想跳过的行,复合结构,目前只能配置要跳过的行的正则表达式,用子节点 regex 描述,默认不跳过任何行,选填;
- early_stop:某次从 Kafka broker 拉取的记录为空,停止任务,默认为 false,仅用于调试,选填;
3.3.3 顶点和边映射
顶点和边映射的节点(JSON 文件中的一个 key)有很多相同的部分,下面先介绍相同部分,再分别介绍顶点映射和边映射的特有节点。
相同部分的节点
- label: 待导入的顶点/边数据所属的
label,必填; - field_mapping: 将输入源列的列名映射为顶点/边的属性名,选填;
- value_mapping: 将输入源的数据值映射为顶点/边的属性值,选填;
- selected: 选择某些列插入,其他未选中的不插入,不能与
ignored同时存在,选填; - ignored: 忽略某些列,使其不参与插入,不能与
selected同时存在,选填; - null_values: 可以指定一些字符串代表空值,比如"NULL”,如果该列对应的顶点/边属性又是一个可空属性,那在构造顶点/边时不会设置该属性的值,选填;
- update_strategies: 如果数据需要按特定方式批量更新时可以对每个属性指定具体的更新策略 (具体见下),选填;
- unfold: 是否将列展开,展开的每一列都会与其他列一起组成一行,相当于是展开成了多行;比如文件的某一列(id 列)的值是
[1,2,3],其他列的值是18,Beijing,当设置了 unfold 之后,这一行就会变成 3 行,分别是:1,18,Beijing,2,18,Beijing和3,18,Beijing。需要注意的是此项只会展开被选作为 id 的列。默认 false,选填;
更新策略支持 8 种 : (需要全大写)
- 数值累加 :
SUM - 两个数字/日期取更大的:
BIGGER - 两个数字/日期取更小:
SMALLER - Set属性取并集:
UNION - Set属性取交集:
INTERSECTION - List属性追加元素:
APPEND - List/Set属性删除元素:
ELIMINATE - 覆盖已有属性:
OVERRIDE
注意: 如果新导入的属性值为空,会采用已有的旧数据而不会采用空值,效果可以参考如下示例
// JSON 文件中以如下方式指定更新策略
{
"vertices": [
{
"label": "person",
"update_strategies": {
"age": "SMALLER",
"set": "UNION"
},
"input": {
"type": "file",
"path": "vertex_person.txt",
"format": "TEXT",
"header": ["name", "age", "set"]
}
}
]
}
// 1.写入一行带 OVERRIDE 更新策略的数据 (这里 null 代表空)
'a b null null'
// 2.再写一行
'null null c d'
// 3.最后可以得到
'a b c d'
// 如果没有更新策略,则会得到
'null null c d'
注意 : 采用了批量更新的策略后, 磁盘读请求数会大幅上升, 导入速度相比纯写覆盖会慢数倍 (此时HDD磁盘IOPS会成为瓶颈, 建议采用SSD以保证速度)
顶点映射的特有节点
- id: 指定某一列作为顶点的 id 列,当顶点 id 策略为
CUSTOMIZE时,必填;当 id 策略为PRIMARY_KEY时,必须为空;
边映射的特有节点
- source: 选择输入源某几列作为源顶点的 id 列,当源顶点的 id 策略为
CUSTOMIZE时,必须指定某一列作为顶点的 id 列;当源顶点的 id 策略为PRIMARY_KEY时,必须指定一列或多列用于拼接生成顶点的 id,也就是说,不管是哪种 id 策略,此项必填; - target: 指定某几列作为目标顶点的 id 列,与 source 类似,不再赘述;
- unfold_source: 是否展开文件的 source 列,效果与顶点映射中的类似,不再赘述;
- unfold_target: 是否展开文件的 target 列,效果与顶点映射中的类似,不再赘述;
3.4 执行命令导入
准备好图模型、数据文件以及输入源映射关系文件后,接下来就可以将数据文件导入到图数据库中。
导入过程由用户提交的命令控制,用户可以通过不同的参数控制执行的具体流程。
3.4.1 参数说明
| 参数 | 默认值 | 是否必传 | 描述信息 |
|---|---|---|---|
-f 或 --file | Y | 配置脚本的路径 | |
-g 或 --graph | Y | 图数据库空间 | |
-s 或 --schema | Y | schema 文件路径 | |
-h 或 --host | localhost | HugeGraphServer 的地址 | |
-p 或 --port | 8080 | HugeGraphServer 的端口号 | |
--username | null | 当 HugeGraphServer 开启了权限认证时,当前图的 username | |
--token | null | 当 HugeGraphServer 开启了权限认证时,当前图的 token | |
--protocol | http | 向服务端发请求的协议,可选 http 或 https | |
--trust-store-file | 请求协议为 https 时,客户端的证书文件路径 | ||
--trust-store-password | 请求协议为 https 时,客户端证书密码 | ||
--clear-all-data | false | 导入数据前是否清除服务端的原有数据 | |
--clear-timeout | 240 | 导入数据前清除服务端的原有数据的超时时间 | |
--incremental-mode | false | 是否使用断点续导模式,仅输入源为 FILE 和 HDFS 支持该模式,启用该模式能从上一次导入停止的地方开始导 | |
--failure-mode | false | 失败模式为 true 时,会导入之前失败了的数据,一般来说失败数据文件需要在人工更正编辑好后,再次进行导入 | |
--batch-insert-threads | CPUs | 批量插入线程池大小 (CPUs 是当前 OS 可用可用逻辑核个数) | |
--single-insert-threads | 8 | 单条插入线程池的大小 | |
--max-conn | 4 * CPUs | HugeClient 与 HugeGraphServer 的最大 HTTP 连接数,调整线程的时候建议同时调整此项 | |
--max-conn-per-route | 2 * CPUs | HugeClient 与 HugeGraphServer 每个路由的最大 HTTP 连接数,调整线程的时候建议同时调整此项 | |
--batch-size | 500 | 导入数据时每个批次包含的数据条数 | |
--max-parse-errors | 1 | 最多允许多少行数据解析错误,达到该值则程序退出 | |
--max-insert-errors | 500 | 最多允许多少行数据插入错误,达到该值则程序退出 | |
--timeout | 60 | 插入结果返回的超时时间(秒) | |
--shutdown-timeout | 10 | 多线程停止的等待时间(秒) | |
--retry-times | 0 | 发生特定异常时的重试次数 | |
--retry-interval | 10 | 重试之前的间隔时间(秒) | |
--check-vertex | false | 插入边时是否检查边所连接的顶点是否存在 | |
--print-progress | true | 是否在控制台实时打印导入条数 | |
--dry-run | false | 打开该模式,只解析不导入,通常用于测试 | |
--help | false | 打印帮助信息 |
3.4.2 断点续导模式
通常情况下,Loader 任务都需要较长时间执行,如果因为某些原因导致导入中断进程退出,而下次希望能从中断的点继续导,这就是使用断点续导的场景。
用户设置命令行参数 –incremental-mode 为 true 即打开了断点续导模式。断点续导的关键在于进度文件,导入进程退出的时候,会把退出时刻的导入进度
记录到进度文件中,进度文件位于 ${struct} 目录下,文件名形如 load-progress ${date} ,${struct} 为映射文件的前缀,${date} 为导入开始
的时刻。比如:在 2019-10-10 12:30:30 开始的一次导入任务,使用的映射文件为 struct-example.json,则进度文件的路径为与 struct-example.json
同级的 struct-example/load-progress 2019-10-10 12:30:30。
注意:进度文件的生成与 –incremental-mode 是否打开无关,每次导入结束都会生成一个进度文件。
如果数据文件格式都是合法的,是用户自己停止(CTRL + C 或 kill,kill -9 不支持)的导入任务,也就是说没有错误记录的情况下,下一次导入只需要设置 为断点续导即可。
但如果是因为太多数据不合法或者网络异常,达到了 –max-parse-errors 或 –max-insert-errors 的限制,Loader 会把这些插入失败的原始行记录到 失败文件中,用户对失败文件中的数据行修改后,设置 –reload-failure 为 true 即可把这些"失败文件"也当作输入源进行导入(不影响正常的文件的导入), 当然如果修改后的数据行仍然有问题,则会被再次记录到失败文件中(不用担心会有重复行)。
每个顶点映射或边映射有数据插入失败时都会产生自己的失败文件,失败文件又分为解析失败文件(后缀 .parse-error)和插入失败文件(后缀 .insert-error),
它们被保存在 ${struct}/current 目录下。比如映射文件中有一个顶点映射 person 和边映射 knows,它们各有一些错误行,当 Loader 退出后,在
${struct}/current 目录下会看到如下文件:
- person-b4cd32ab.parse-error: 顶点映射 person 解析错误的数据
- person-b4cd32ab.insert-error: 顶点映射 person 插入错误的数据
- knows-eb6b2bac.parse-error: 边映射 knows 解析错误的数据
- knows-eb6b2bac.insert-error: 边映射 knows 插入错误的数据
.parse-error 和 .insert-error 并不总是一起存在的,只有存在解析出错的行才会有 .parse-error 文件,只有存在插入出错的行才会有 .insert-error 文件。
3.4.3 logs 目录文件说明
程序执行过程中各日志及错误数据会写入 hugegraph-loader.log 文件中。
3.4.4 执行命令
运行 bin/hugegraph-loader 并传入参数
bin/hugegraph-loader -g {GRAPH_NAME} -f ${INPUT_DESC_FILE} -s ${SCHEMA_FILE} -h {HOST} -p {PORT}
4 完整示例
下面给出的是 hugegraph-loader 包中 example 目录下的例子。(GitHub 地址)
4.1 准备数据
顶点文件:example/file/vertex_person.csv
marko,29,Beijing
vadas,27,Hongkong
josh,32,Beijing
peter,35,Shanghai
"li,nary",26,"Wu,han"
tom,null,NULL
顶点文件:example/file/vertex_software.txt
id|name|lang|price|ISBN
1|lop|java|328|ISBN978-7-107-18618-5
2|ripple|java|199|ISBN978-7-100-13678-5
边文件:example/file/edge_knows.json
{"source_name": "marko", "target_name": "vadas", "date": "20160110", "weight": 0.5}
{"source_name": "marko", "target_name": "josh", "date": "20130220", "weight": 1.0}
边文件:example/file/edge_created.json
{"aname": "marko", "bname": "lop", "date": "20171210", "weight": 0.4}
{"aname": "josh", "bname": "lop", "date": "20091111", "weight": 0.4}
{"aname": "josh", "bname": "ripple", "date": "20171210", "weight": 1.0}
{"aname": "peter", "bname": "lop", "date": "20170324", "weight": 0.2}
4.2 编写 schema
点击展开/折叠 schema 文件:example/file/schema.groovy
schema.propertyKey("name").asText().ifNotExist().create();
schema.propertyKey("age").asInt().ifNotExist().create();
schema.propertyKey("city").asText().ifNotExist().create();
schema.propertyKey("weight").asDouble().ifNotExist().create();
schema.propertyKey("lang").asText().ifNotExist().create();
schema.propertyKey("date").asText().ifNotExist().create();
schema.propertyKey("price").asDouble().ifNotExist().create();
schema.vertexLabel("person").properties("name", "age", "city").primaryKeys("name").ifNotExist().create();
schema.vertexLabel("software").properties("name", "lang", "price").primaryKeys("name").ifNotExist().create();
schema.indexLabel("personByAge").onV("person").by("age").range().ifNotExist().create();
schema.indexLabel("personByCity").onV("person").by("city").secondary().ifNotExist().create();
schema.indexLabel("personByAgeAndCity").onV("person").by("age", "city").secondary().ifNotExist().create();
schema.indexLabel("softwareByPrice").onV("software").by("price").range().ifNotExist().create();
schema.edgeLabel("knows").sourceLabel("person").targetLabel("person").properties("date", "weight").ifNotExist().create();
schema.edgeLabel("created").sourceLabel("person").targetLabel("software").properties("date", "weight").ifNotExist().create();
schema.indexLabel("createdByDate").onE("created").by("date").secondary().ifNotExist().create();
schema.indexLabel("createdByWeight").onE("created").by("weight").range().ifNotExist().create();
schema.indexLabel("knowsByWeight").onE("knows").by("weight").range().ifNotExist().create();
4.3 编写输入源映射文件example/file/struct.json
点击展开/折叠 源映射文件 example/file/struct.json
{
"vertices": [
{
"label": "person",
"input": {
"type": "file",
"path": "example/file/vertex_person.csv",
"format": "CSV",
"header": ["name", "age", "city"],
"charset": "UTF-8",
"skipped_line": {
"regex": "(^#|^//).*"
}
},
"null_values": ["NULL", "null", ""]
},
{
"label": "software",
"input": {
"type": "file",
"path": "example/file/vertex_software.txt",
"format": "TEXT",
"delimiter": "|",
"charset": "GBK"
},
"id": "id",
"ignored": ["ISBN"]
}
],
"edges": [
{
"label": "knows",
"source": ["source_name"],
"target": ["target_name"],
"input": {
"type": "file",
"path": "example/file/edge_knows.json",
"format": "JSON",
"date_format": "yyyyMMdd"
},
"field_mapping": {
"source_name": "name",
"target_name": "name"
}
},
{
"label": "created",
"source": ["source_name"],
"target": ["target_id"],
"input": {
"type": "file",
"path": "example/file/edge_created.json",
"format": "JSON",
"date_format": "yyyy-MM-dd"
},
"field_mapping": {
"source_name": "name"
}
}
]
}
4.4 执行命令导入
sh bin/hugegraph-loader.sh -g hugegraph -f example/file/struct.json -s example/file/schema.groovy
导入结束后,会出现类似如下统计信息:
vertices/edges has been loaded this time : 8/6
--------------------------------------------------
count metrics
input read success : 14
input read failure : 0
vertex parse success : 8
vertex parse failure : 0
vertex insert success : 8
vertex insert failure : 0
edge parse success : 6
edge parse failure : 0
edge insert success : 6
edge insert failure : 0
4.5 使用 docker 导入
4.5.1 使用 docker exec 直接导入数据
4.5.1.1 数据准备
如果仅仅尝试使用 loader, 我们可以使用内置的 example 数据集进行导入,无需自己额外准备数据
如果使用自定义的数据,则在使用 loader 导入数据之前,我们需要将数据复制到容器内部。
首先我们可以根据 4.1-4.3 的步骤准备数据,将准备好的数据通过 docker cp 复制到 loader 容器内部。
假设我们已经按照上述的步骤准备好了对应的数据集,存放在 hugegraph-dataset 文件夹下,文件结构如下:
tree -f hugegraph-dataset/
hugegraph-dataset
├── hugegraph-dataset/edge_created.json
├── hugegraph-dataset/edge_knows.json
├── hugegraph-dataset/schema.groovy
├── hugegraph-dataset/struct.json
├── hugegraph-dataset/vertex_person.csv
└── hugegraph-dataset/vertex_software.txt
将文件复制到容器内部
docker cp hugegraph-dataset loader:/loader/dataset
docker exec -it loader ls /loader/dataset
edge_created.json edge_knows.json schema.groovy struct.json vertex_person.csv vertex_software.txt
4.5.1.2 数据导入
以内置的 example 数据集为例,我们可以使用以下的命令对数据进行导入。
如果需要导入自己准备的数据集,则只需要修改 -f 配置脚本的路径 以及 -s schema 文件路径即可。
其他的参数可以参照 3.4.1 参数说明
docker exec -it loader bin/hugegraph-loader.sh -g hugegraph -f example/file/struct.json -s example/file/schema.groovy -h server -p 8080
如果导入用户自定义的数据集,按照刚才的例子,则使用:
docker exec -it loader bin/hugegraph-loader.sh -g hugegraph -f /loader/dataset/struct.json -s /loader/dataset/schema.groovy -h server -p 8080
如果
loader和server位于同一 docker 网络,则可以指定-h {server_container_name}, 否则需要指定server的宿主机的 ip (在我们的例子中,server_container_name为server).
然后我们可以观察到结果:
HugeGraphLoader worked in NORMAL MODE
vertices/edges loaded this time : 8/6
--------------------------------------------------
count metrics
input read success : 14
input read failure : 0
vertex parse success : 8
vertex parse failure : 0
vertex insert success : 8
vertex insert failure : 0
edge parse success : 6
edge parse failure : 0
edge insert success : 6
edge insert failure : 0
--------------------------------------------------
meter metrics
total time : 0.199s
read time : 0.046s
load time : 0.153s
vertex load time : 0.077s
vertex load rate(vertices/s) : 103
edge load time : 0.112s
edge load rate(edges/s) : 53
也可以使用 curl 或者 hubble观察导入结果,此处以 curl 为例:
> curl "http://localhost:8080/graphs/hugegraph/graph/vertices" | gunzip
{"vertices":[{"id":1,"label":"software","type":"vertex","properties":{"name":"lop","lang":"java","price":328.0}},{"id":2,"label":"software","type":"vertex","properties":{"name":"ripple","lang":"java","price":199.0}},{"id":"1:tom","label":"person","type":"vertex","properties":{"name":"tom"}},{"id":"1:josh","label":"person","type":"vertex","properties":{"name":"josh","age":32,"city":"Beijing"}},{"id":"1:marko","label":"person","type":"vertex","properties":{"name":"marko","age":29,"city":"Beijing"}},{"id":"1:peter","label":"person","type":"vertex","properties":{"name":"peter","age":35,"city":"Shanghai"}},{"id":"1:vadas","label":"person","type":"vertex","properties":{"name":"vadas","age":27,"city":"Hongkong"}},{"id":"1:li,nary","label":"person","type":"vertex","properties":{"name":"li,nary","age":26,"city":"Wu,han"}}]}
如果想检查边的导入结果,可以使用 curl "http://localhost:8080/graphs/hugegraph/graph/edges" | gunzip
4.5.2 进入 docker 容器进行导入
除了直接使用 docker exec 导入数据,我们也可以进入容器进行数据导入,基本流程与 4.5.1 相同
使用 docker exec -it loader bash进入容器内部,并执行命令
sh bin/hugegraph-loader.sh -g hugegraph -f example/file/struct.json -s example/file/schema.groovy -h server -p 8080
执行的结果如 4.5.1 所示
4.6 使用 spark-loader 导入
Spark 版本:Spark 3+,其他版本未测试。 HugeGraph Toolchain 版本:toolchain-1.0.0
spark-loader 的参数分为两部分,注意:因二者参数名缩写存在重合部分,请使用参数全称。两种参数之间无需保证先后顺序。
- hugegraph 参数(参考:hugegraph-loader 参数说明 )
- Spark 任务提交参数(参考:Submitting Applications)
示例:
sh bin/hugegraph-spark-loader.sh --master yarn \
--deploy-mode cluster --name spark-hugegraph-loader --file ./hugegraph.json \
--username admin --token admin --host xx.xx.xx.xx --port 8093 \
--graph graph-test --num-executors 6 --executor-cores 16 --executor-memory 15g