测试指南:如需在本地运行工具链测试,请参考 HugeGraph 工具链本地测试指南
DeepWiki 提供实时更新的项目文档,内容更全面准确,适合快速了解项目最新情况。
This is the multi-page printable view of this section. Click here to print.
测试指南:如需在本地运行工具链测试,请参考 HugeGraph 工具链本地测试指南
DeepWiki 提供实时更新的项目文档,内容更全面准确,适合快速了解项目最新情况。
特别注意: 当前版本的 Hubble 还没有添加 Auth/Login 相关界面和接口和单独防护, 在下一个 Release 版 (> 1.5) 会加入, 请留意避免把它暴露在公网环境或不受信任的网络中,以免引起相关 SEC 问题 (另外也可以使用 IP & 端口白名单 + HTTPS)
测试指南:如需在本地运行 Hubble 测试,请参考 工具链本地测试指南
HugeGraph-Hubble 是 HugeGraph 的一站式可视化分析平台,平台涵盖了从数据建模,到数据快速导入, 再到数据的在线、离线分析、以及图的统一管理的全过程,实现了图应用的全流程向导式操作,旨在提升用户的使用流畅度, 降低用户的使用门槛,提供更为高效易用的使用体验。
平台主要包括以下模块:
图管理模块通过图的创建,连接平台与图数据,实现多图的统一管理,并实现图的访问、编辑、删除、查询操作。
元数据建模模块通过创建属性库,顶点类型,边类型,索引类型,实现图模型的构建与管理,平台提供两种模式,列表模式和图模式,可实时展示元数据模型,更加直观。同时还提供了跨图的元数据复用功能,省去相同元数据繁琐的重复创建过程,极大地提升建模效率,增强易用性。
通过输入图遍历语言 Gremlin 可实现图数据的高性能通用分析,并提供顶点的定制化多维路径查询等功能,提供 3 种图结果展示方式,包括:图形式、表格形式、Json 形式,多维度展示数据形态,满足用户使用的多种场景需求。提供运行记录及常用语句收藏等功能,实现图操作的可追溯,以及查询输入的复用共享,快捷高效。支持图数据的导出,导出格式为 Json 格式。
对于需要遍历全图的 Gremlin 任务,索引的创建与重建等耗时较长的异步任务,平台提供相应的任务管理功能,实现异步任务的统一的管理与结果查看。
注: 数据导入功能目前适合初步试用,正式数据导入请使用 hugegraph-loader, 性能/稳定性/功能全面许多
数据导入是将用户的业务数据转化为图的顶点和边并插入图数据库中,平台提供了向导式的可视化导入模块,通过创建导入任务, 实现导入任务的管理及多个导入任务的并行运行,提高导入效能。进入导入任务后,只需跟随平台步骤提示,按需上传文件,填写内容, 就可轻松实现图数据的导入过程,同时支持断点续传,错误重试机制等,降低导入成本,提升效率。
有三种方式可以部署hugegraph-hubble
特别注意: docker 模式下,若 hubble 和 server 在同一宿主机,hubble 页面中设置 server 的
hostname不能设置为localhost/127.0.0.1,因这会指向 hubble 容器内部而非宿主机,导致无法连接到 server.若 hubble 和 server 在同一 docker 网络下,推荐直接使用
container_name(如下例的server) 作为主机名。或者也可以使用 宿主机 IP 作为主机名,此时端口号为宿主机给 server 配置的端口
我们可以使用 docker run -itd --name=hubble -p 8088:8088 hugegraph/hubble:1.5.0 快速启动 hubble.
或者使用 docker-compose 启动 hubble,另外如果 hubble 和 server 在同一个 docker 网络下,可以使用 server 的 contain_name 进行访问,而不需要宿主机的 ip
使用docker-compose up -d,docker-compose.yml如下:
version: '3'
services:
server:
image: hugegraph/hugegraph:1.5.0
container_name: server
environment:
- PASSWORD=xxx
ports:
- 8080:8080
hubble:
image: hugegraph/hubble:1.5.0
container_name: hubble
ports:
- 8088:8088
注意:
hugegraph-hubble的 docker 镜像是一个便捷发布版本,用于快速测试试用 hubble,并非ASF 官方发布物料包的方式。你可以从 ASF Release Distribution Policy 中得到更多细节。生产环境推荐使用
release tag(如1.5.0) 稳定版。使用latesttag 默认对应 master 最新代码。
hubble项目在toolchain项目中,首先下载toolchain的 tar 包
wget https://downloads.apache.org/hugegraph/{version}/apache-hugegraph-toolchain-incubating-{version}.tar.gz
tar -xvf apache-hugegraph-toolchain-incubating-{version}.tar.gz
cd apache-hugegraph-toolchain-incubating-{version}.tar.gz/apache-hugegraph-hubble-incubating-{version}
运行hubble
bin/start-hubble.sh
随后我们可以看到
starting HugeGraphHubble ..............timed out with http status 502
2023-08-30 20:38:34 [main] [INFO ] o.a.h.HugeGraphHubble [] - Starting HugeGraphHubble v1.0.0 on cpu05 with PID xxx (~/apache-hugegraph-toolchain-incubating-1.0.0/apache-hugegraph-hubble-incubating-1.0.0/lib/hubble-be-1.0.0.jar started by $USER in ~/apache-hugegraph-toolchain-incubating-1.0.0/apache-hugegraph-hubble-incubating-1.0.0)
...
2023-08-30 20:38:38 [main] [INFO ] c.z.h.HikariDataSource [] - hugegraph-hubble-HikariCP - Start completed.
2023-08-30 20:38:41 [main] [INFO ] o.a.c.h.Http11NioProtocol [] - Starting ProtocolHandler ["http-nio-0.0.0.0-8088"]
2023-08-30 20:38:41 [main] [INFO ] o.a.h.HugeGraphHubble [] - Started HugeGraphHubble in 7.379 seconds (JVM running for 8.499)
然后使用浏览器访问 ip:8088 可看到hubble页面,通过bin/stop-hubble.sh则可以停止服务
注意: 目前已在 hugegraph-hubble/hubble-be/pom.xml 中引入插件 frontend-maven-plugin,编译 hubble 时不需要用户本地环境提前安装 Nodejs V16.x 与 yarn 环境,可直接按下述步骤执行
下载 toolchain 源码包
git clone https://github.com/apache/hugegraph-toolchain.git
编译hubble, 它依赖 loader 和 client, 编译时需提前构建这些依赖 (后续可跳)
cd hugegraph-toolchain
sudo pip install -r hugegraph-hubble/hubble-dist/assembly/travis/requirements.txt
mvn install -pl hugegraph-client,hugegraph-loader -am -Dmaven.javadoc.skip=true -DskipTests -ntp
cd hugegraph-hubble
mvn -e package -Dmaven.javadoc.skip=true -Dmaven.test.skip=true -ntp
cd apache-hugegraph-hubble-incubating*
启动hubble
bin/start-hubble.sh -d
平台的模块使用流程如下:

图管理模块下,点击【创建图】,通过填写图 ID、图名称、主机名、端口号、用户名、密码的信息,实现多图的连接。
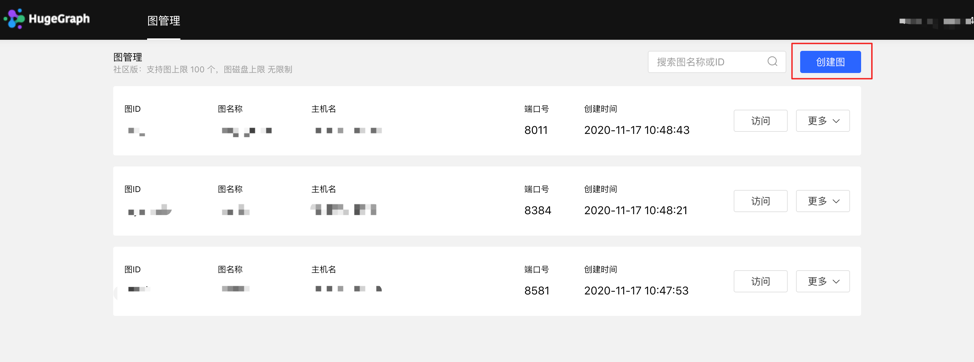
创建图填写内容如下:
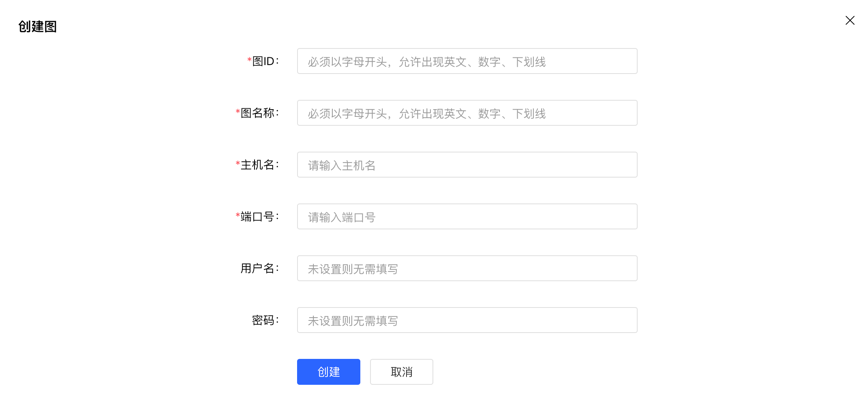
注意:如果使用 docker 启动
hubble,且server和hubble位于同一宿主机,不能直接使用localhost/127.0.0.1作为主机名。如果hubble和server在同一 docker 网络下,则可以直接使用 container_name 作为主机名,端口则为 8080。或者也可以使用宿主机 ip 作为主机名,此时端口为宿主机为 server 配置的端口
实现图空间的信息访问,进入后,可进行图的多维查询分析、元数据管理、数据导入、算法分析等操作。

左侧导航处:
列表模式:
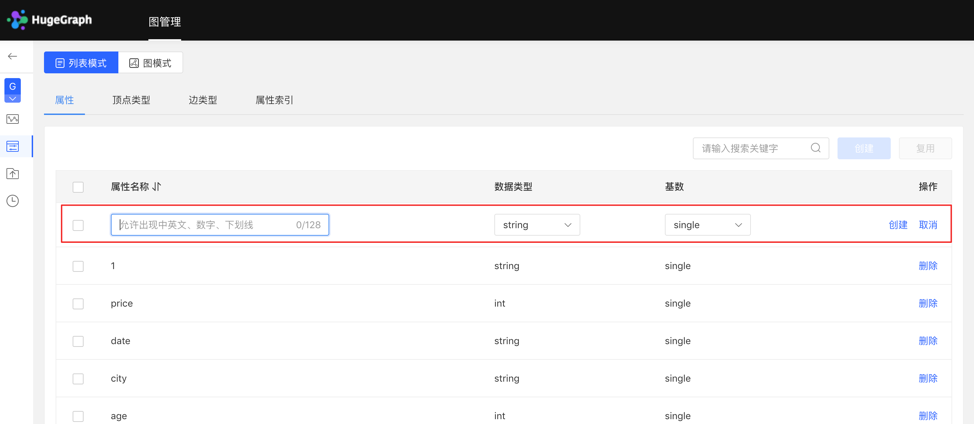
图模式:
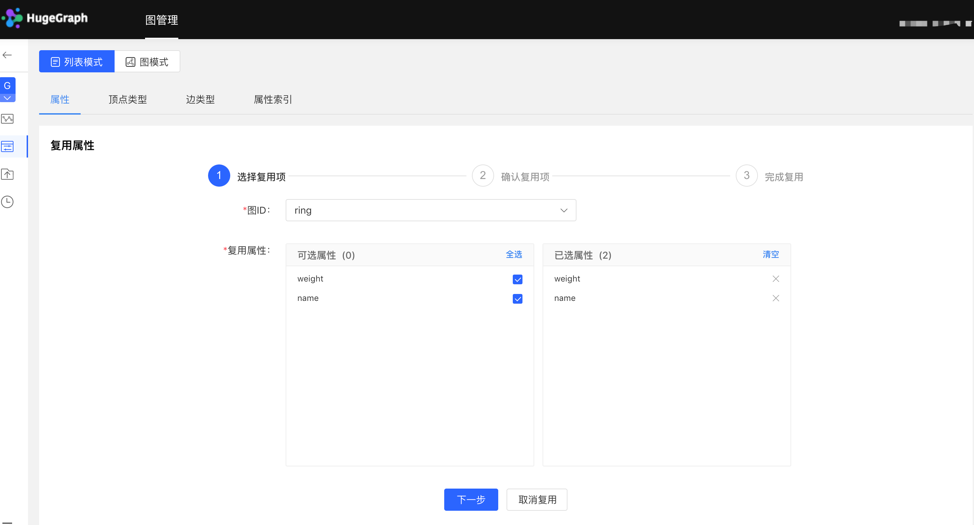
选择复用项:
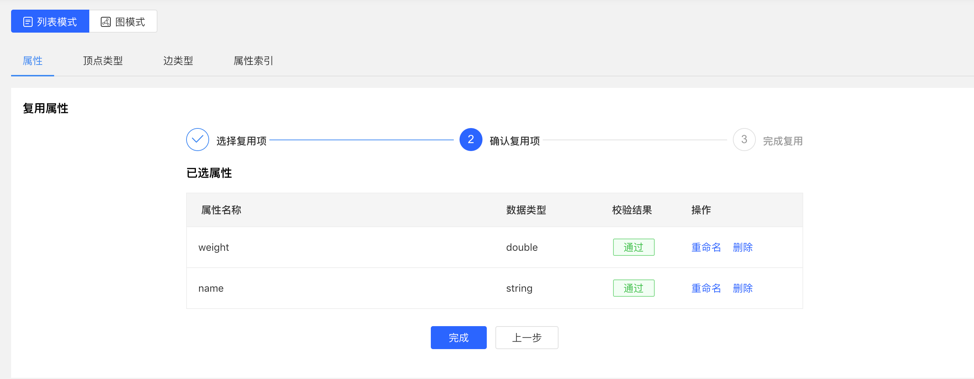
校验复用项:
列表模式:
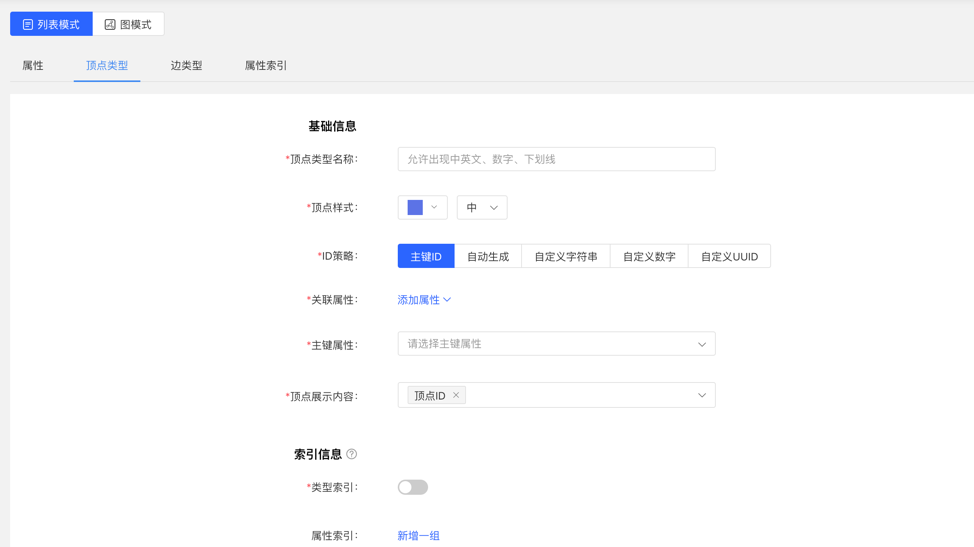
图模式:
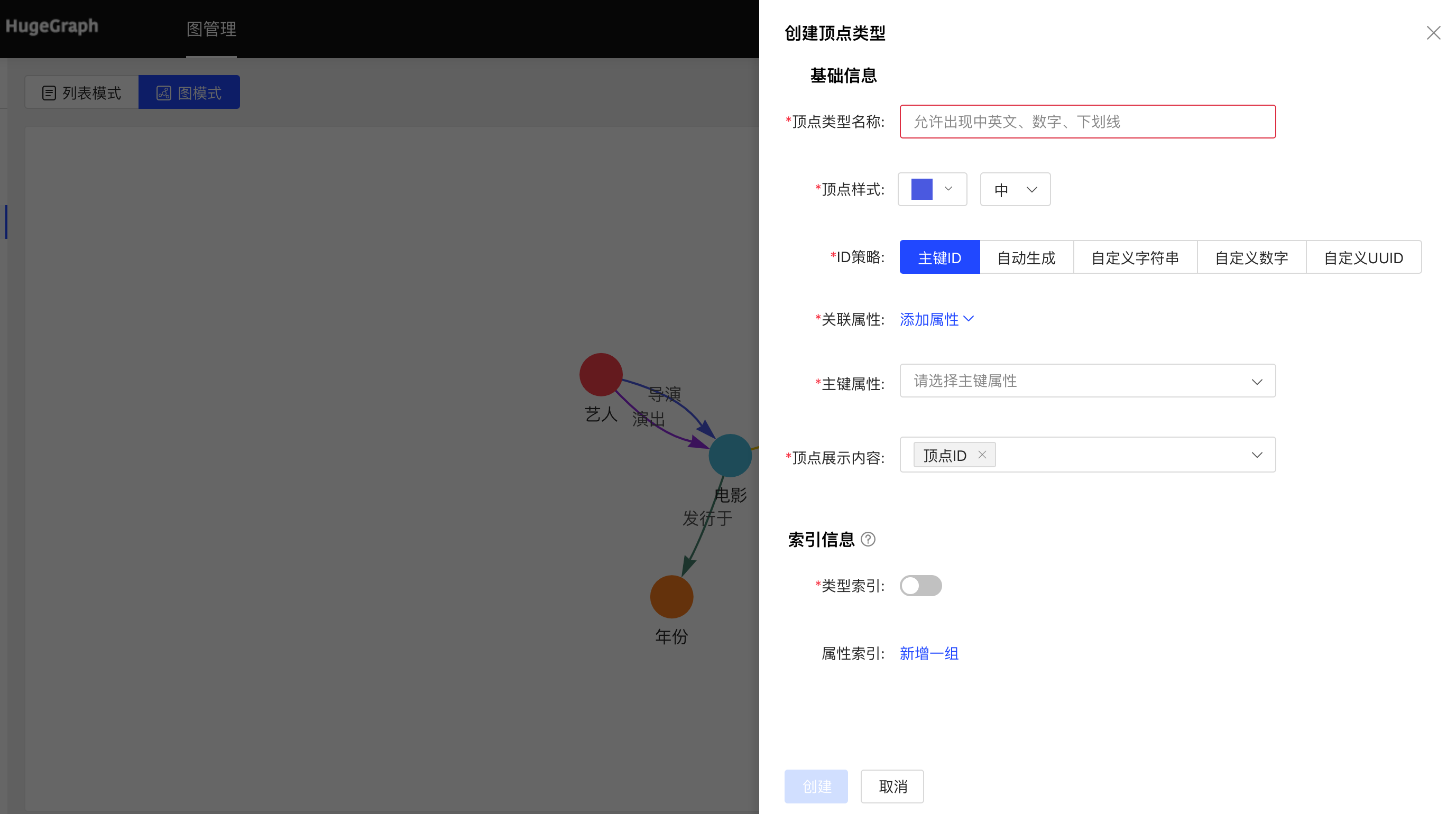
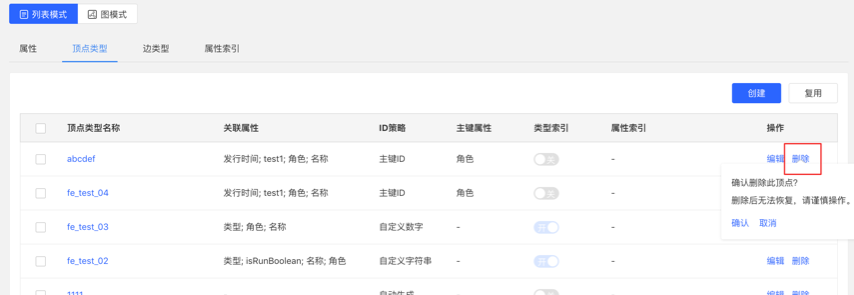
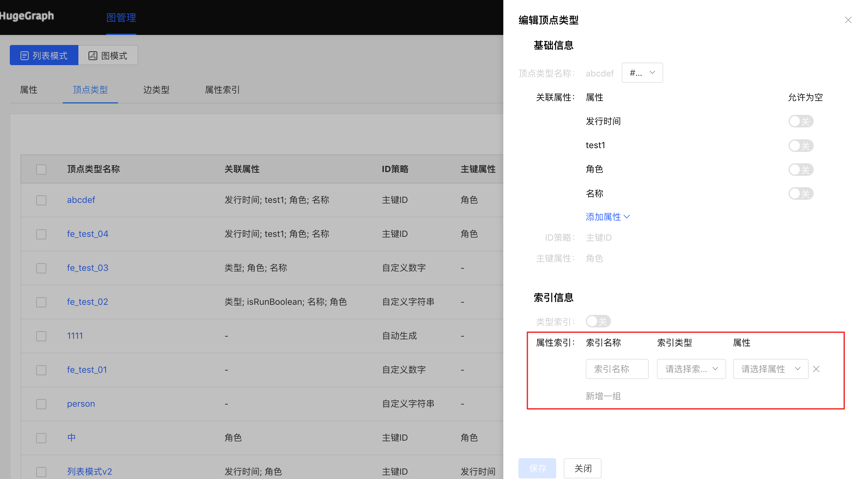
可进行编辑操作,顶点样式、关联类型、顶点展示内容、属性索引可编辑,其余不可编辑。
可进行单条删除或批量删除操作。
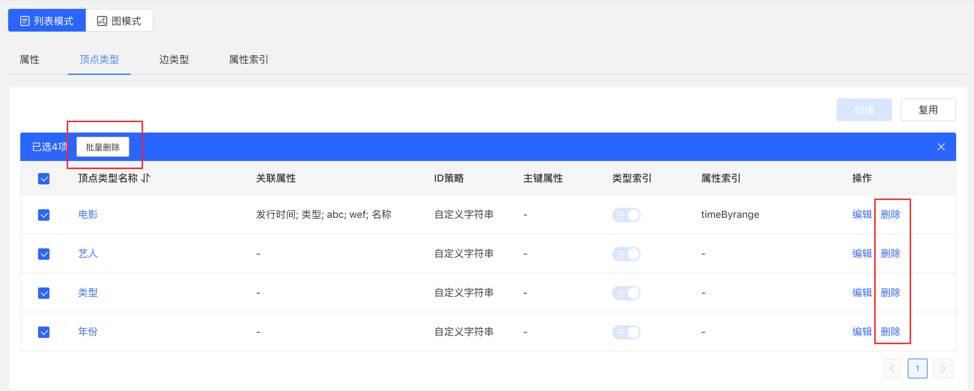
列表模式:
图模式:
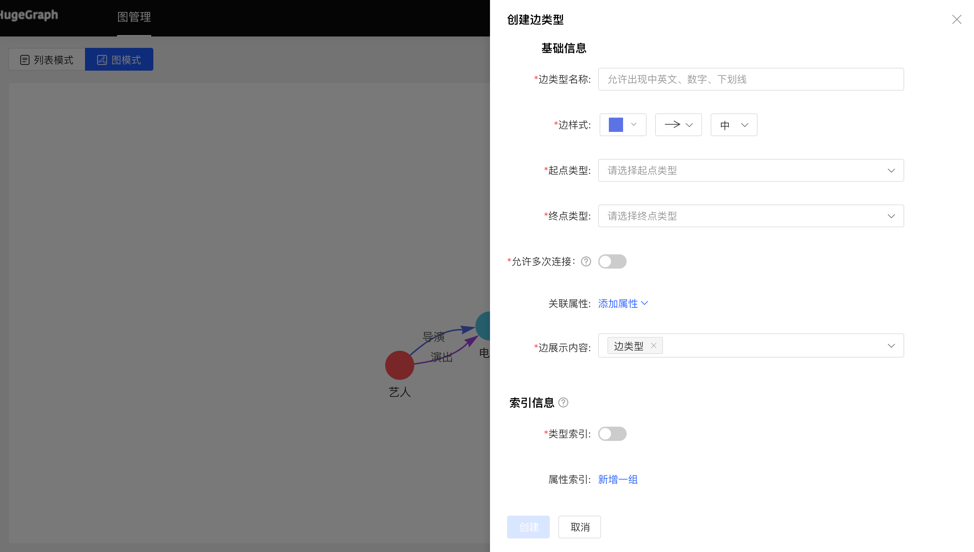
展示顶点类型和边类型的顶点索引和边索引。
注意:目前推荐使用 hugegraph-loader 进行正式数据导入,hubble 内置的导入用来做测试和简单上手
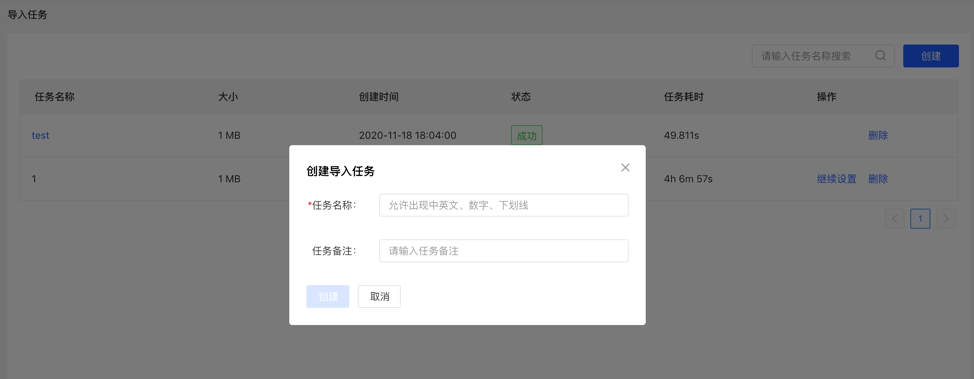
数据导入的使用流程如下:

左侧导航处:
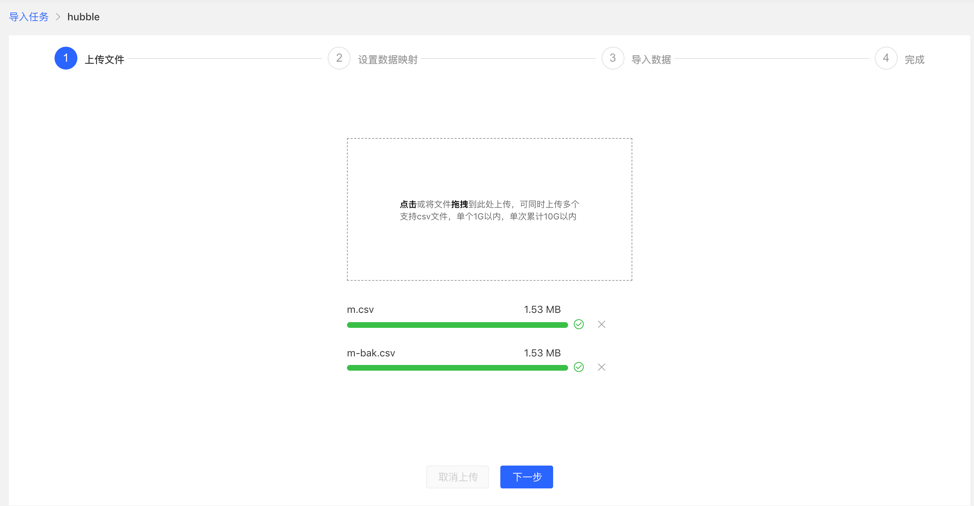
对上传的文件分别设置数据映射,包括文件设置和类型设置
文件设置:勾选或填写是否包含表头、分隔符、编码格式等文件本身的设置内容,均设置默认值,无需手动填写
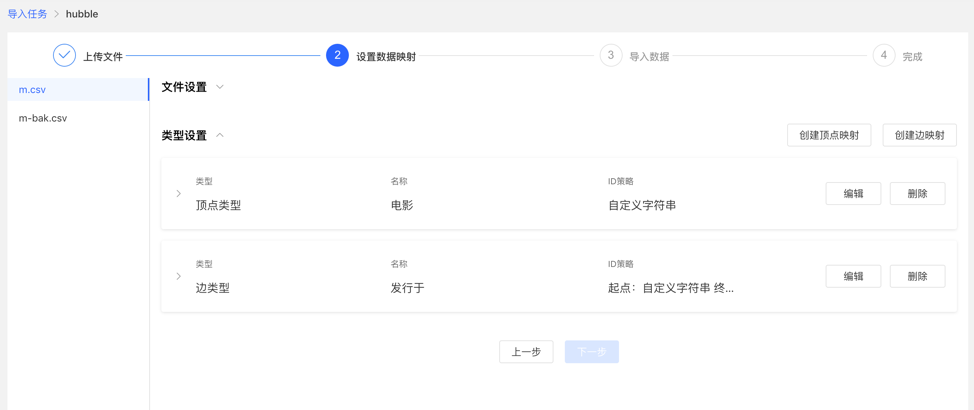
类型设置:
顶点映射和边映射:
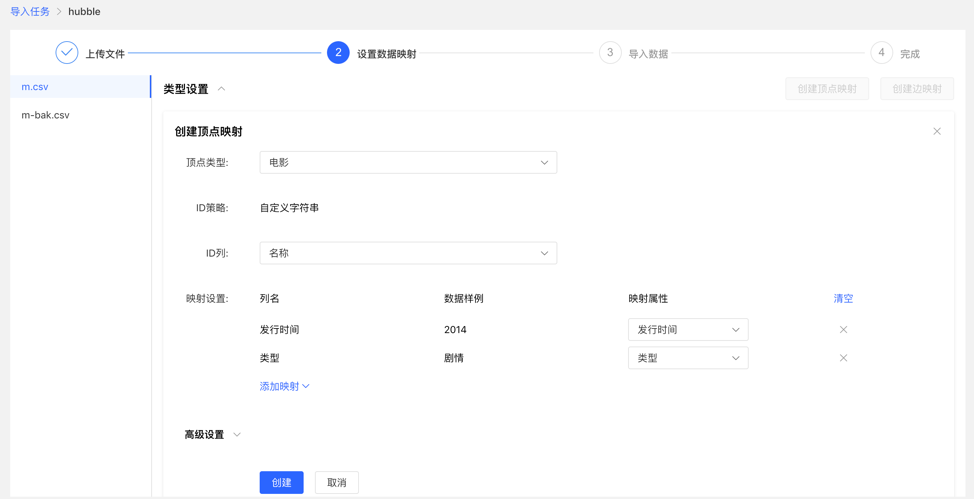
【顶点类型】 :选择顶点类型,并为其 ID 映射上传文件中列数据;
【边类型】:选择边类型,为其起点类型和终点类型的 ID 列映射上传文件的列数据;
映射设置:为选定的顶点类型的属性映射上传文件中的列数据,此处,若属性名称与文件的表头名称一致,可自动匹配映射属性,无需手动填选
完成设置后,显示设置列表,方可进行下一步操作,支持映射的新增、编辑、删除操作
设置映射的填写内容:
映射列表:
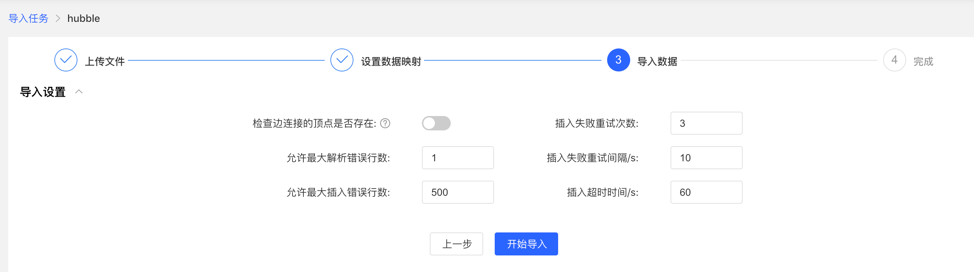
导入前需要填写导入设置参数,填写完成后,可开始向图库中导入数据
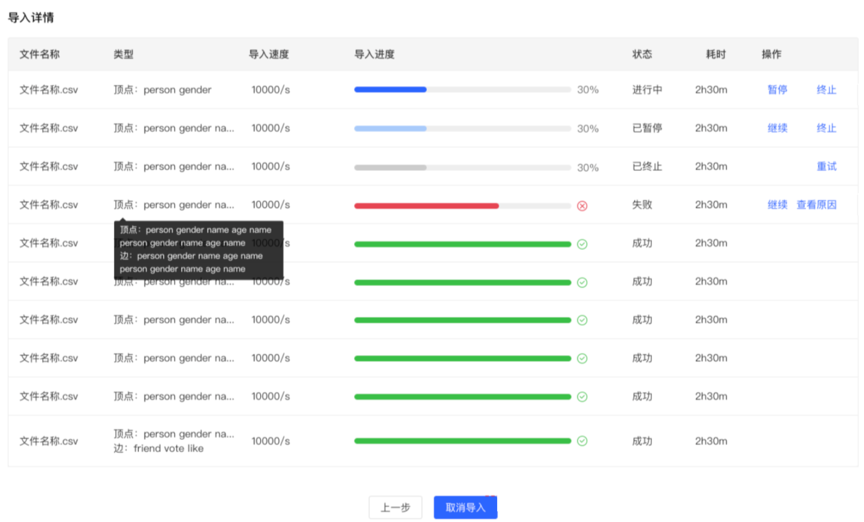
左侧导航处:
通过左侧切换入口,灵活切换多图的操作空间
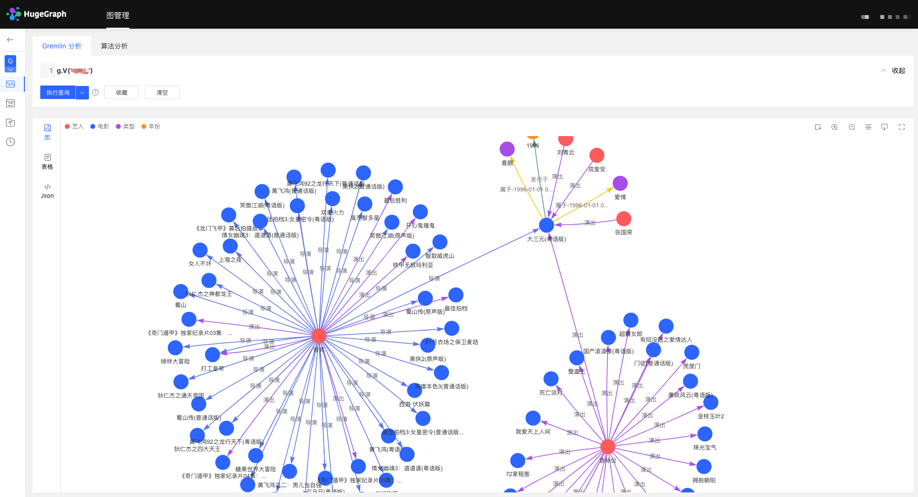
HugeGraph 支持 Apache TinkerPop3 的图遍历查询语言 Gremlin,Gremlin 是一种通用的图数据库查询语言,通过输入 Gremlin 语句,点击执行,即可执行图数据的查询分析操作,并可实现顶点/边的创建及删除、顶点/边的属性修改等。
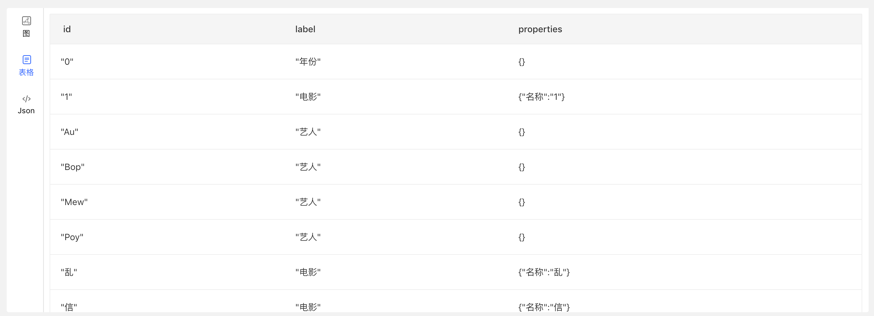
Gremlin 查询后,下方为图结果展示区域,提供 3 种图结果展示方式,分别为:【图模式】、【表格模式】、【Json 模式】。
支持缩放、居中、全屏、导出等操作。
【图模式】
【表格模式】
【Json 模式】

点击顶点/边实体,可查看顶点/边的数据详情,包括:顶点/边类型,顶点 ID,属性及对应值,拓展图的信息展示维度,提高易用性。
除了全局的查询外,可针对查询结果中的顶点进行深度定制化查询以及隐藏操作,实现图结果的定制化挖掘。
右击顶点,出现顶点的菜单入口,可进行展示、查询、隐藏等操作。
双击顶点,也可展示与选中点关联的顶点。
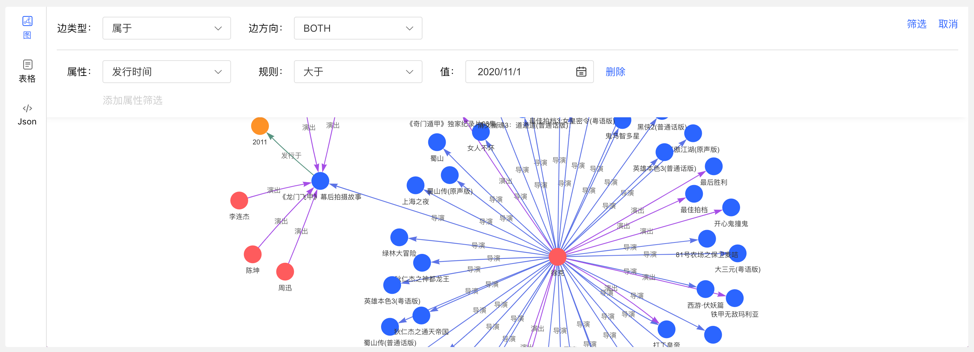
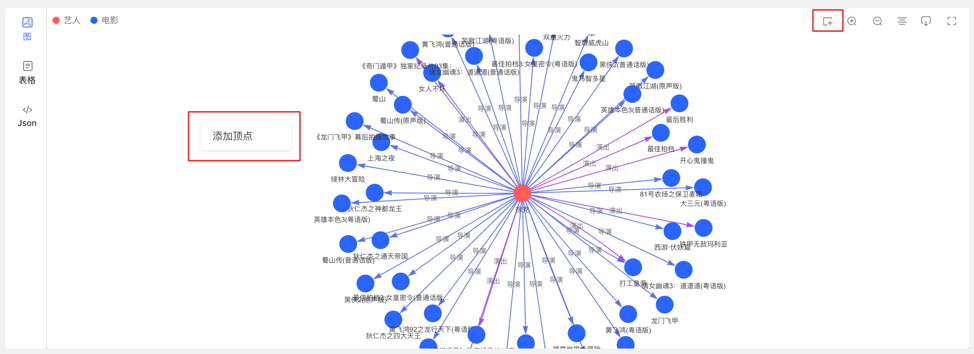
在图区可通过两个入口,动态新增顶点,如下:
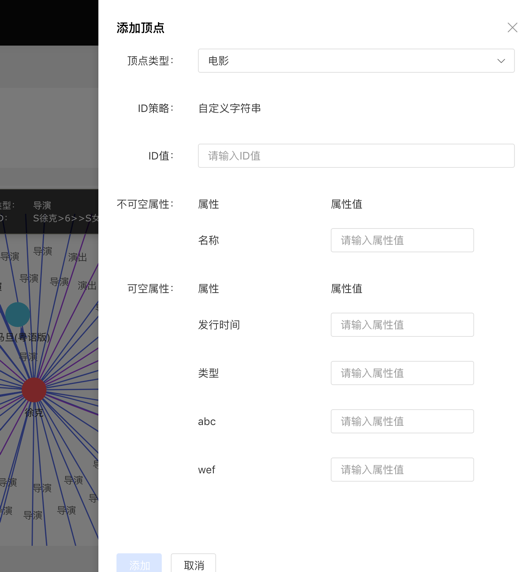
通过选择或填写顶点类型、ID 值、属性信息,完成顶点的增加。
入口如下:
添加顶点内容如下:
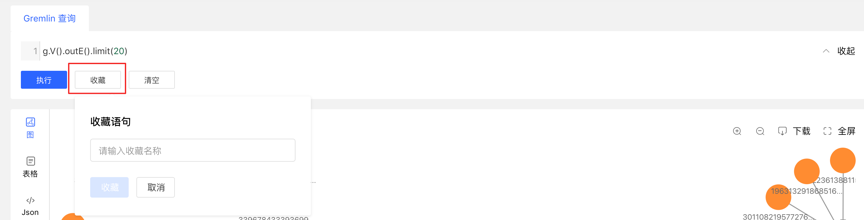
右击图结果中的顶点,可增加该点的出边或者入边。
左侧导航处:
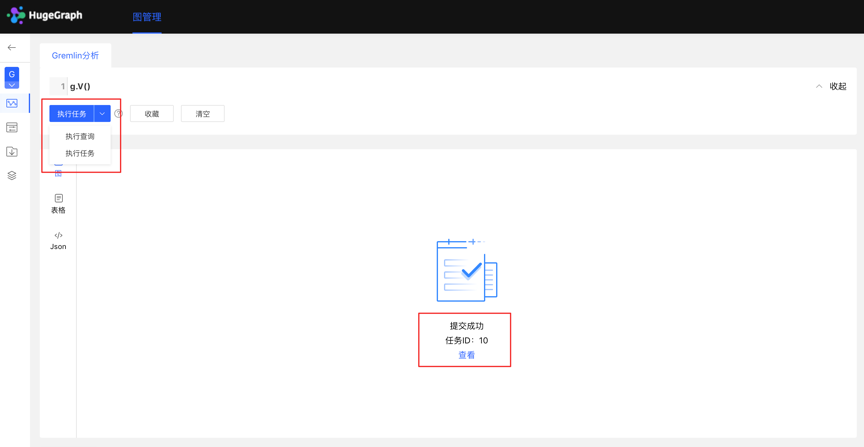
1.创建任务
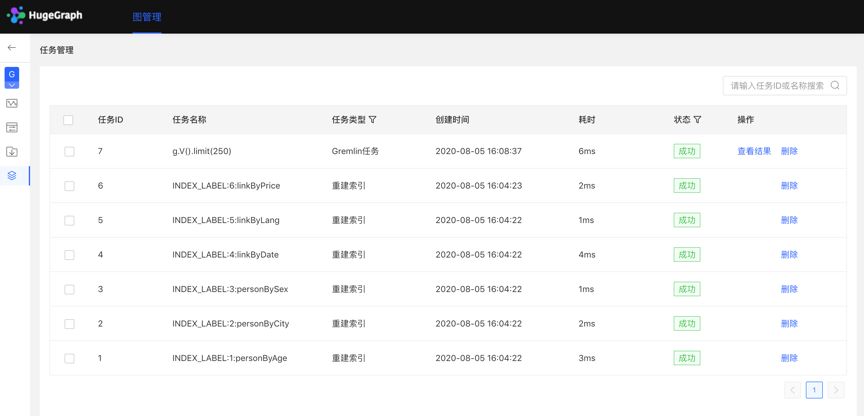
点击查看入口,跳转到任务管理列表,如下:
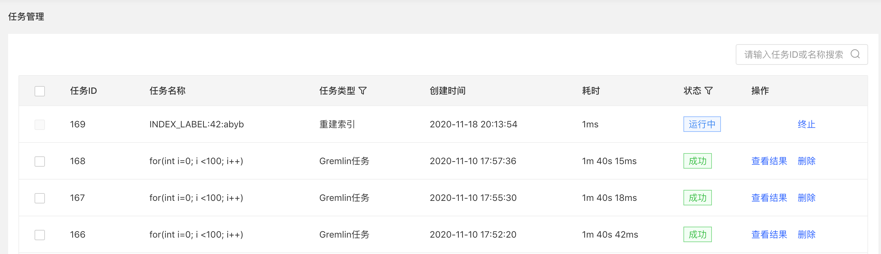
4.查看结果
Hubble 上暂未提供可视化的 OLAP 算法执行,可调用 RESTful API 进行 OLAP 类算法任务,在任务管理中通过 ID 找到相应任务,查看进度与结果等。
1.创建任务
2.任务详情
HugeGraph-Hubble 可以通过 conf/hugegraph-hubble.properties 文件进行配置。
| 配置项 | 默认值 | 说明 |
|---|---|---|
hubble.host | 0.0.0.0 | Hubble 服务绑定的地址 |
hubble.port | 8088 | Hubble 服务监听的端口 |
这些设置控制查询结果限制,防止内存问题:
| 配置项 | 默认值 | 说明 |
|---|---|---|
gremlin.suffix_limit | 250 | 查询后缀最大长度 |
gremlin.vertex_degree_limit | 100 | 显示的最大顶点度数 |
gremlin.edges_total_limit | 500 | 返回的最大边数 |
gremlin.batch_query_ids | 100 | ID 批量查询大小 |
HugeGraph-Loader 是 HugeGraph 的数据导入组件,能够将多种数据源的数据转化为图的顶点和边并批量导入到图数据库中。
目前支持的数据源包括:
本地磁盘文件和 HDFS 文件支持断点续传。
后面会具体说明。
注意:使用 HugeGraph-Loader 需要依赖 HugeGraph Server 服务,下载和启动 Server 请参考 HugeGraph-Server Quick Start
测试指南:如需在本地运行 Loader 测试,请参考 工具链本地测试指南
有两种方式可以获取 HugeGraph-Loader:
我们可以使用 docker run -itd --name loader hugegraph/loader:1.5.0 部署 loader 服务。对于需要加载的数据,则可以通过挂载 -v /path/to/data/file:/loader/file 或者 docker cp 的方式将文件复制到 loader 容器内部。
或者使用 docker-compose 启动 loader, 启动命令为 docker-compose up -d, 样例的 docker-compose.yml 如下所示:
version: '3'
services:
server:
image: hugegraph/hugegraph:1.5.0
container_name: server
environment:
- PASSWORD=xxx
ports:
- 8080:8080
hubble:
image: hugegraph/hubble:1.5.0
container_name: hubble
ports:
- 8088:8088
loader:
image: hugegraph/loader:1.5.0
container_name: loader
# mount your own data here
# volumes:
# - /path/to/data/file:/loader/file
具体的数据导入流程可以参考 4.5 使用 docker 导入
注意:
hugegraph-loader 的 docker 镜像是一个便捷版本,用于快速启动 loader,并不是官方发布物料包方式。你可以从 ASF Release Distribution Policy 中得到更多细节。
推荐使用
release tag(如1.5.0) 以获取稳定版。使用latesttag 可以使用开发中的最新功能。
下载最新版本的 HugeGraph-Toolchain Release 包,里面包含了 loader + tool + hubble 全套工具,如果你已经下载,可跳过重复步骤
wget https://downloads.apache.org/hugegraph/{version}/apache-hugegraph-toolchain-incubating-{version}.tar.gz
tar zxf *hugegraph*.tar.gz
克隆最新版本的 HugeGraph-Loader 源码包:
# 1. get from github
git clone https://github.com/apache/hugegraph-toolchain.git
# 2. get from direct url (please choose the **latest release** version)
wget https://downloads.apache.org/hugegraph/{version}/apache-hugegraph-toolchain-incubating-{version}-src.tar.gz
由于 Oracle ojdbc license 的限制,需要手动安装 ojdbc 到本地 maven 仓库。 访问 Oracle jdbc 下载 页面。选择 Oracle Database 12c Release 2 (12.2.0.1) drivers,如下图所示。
打开链接后,选择“ojdbc8.jar”
把 ojdbc8 安装到本地 maven 仓库,进入ojdbc8.jar所在目录,执行以下命令。
mvn install:install-file -Dfile=./ojdbc8.jar -DgroupId=com.oracle -DartifactId=ojdbc8 -Dversion=12.2.0.1 -Dpackaging=jar
编译生成 tar 包:
cd hugegraph-loader
mvn clean package -DskipTests
使用 HugeGraph-Loader 的基本流程分为以下几步:
这一步是建模的过程,用户需要对自己已有的数据和想要创建的图模型有一个清晰的构想,然后编写 schema 建立图模型。
比如想创建一个拥有两类顶点及两类边的图,顶点是"人"和"软件",边是"人认识人"和"人创造软件",并且这些顶点和边都带有一些属性,比如顶点"人"有:“姓名”、“年龄"等属性, “软件"有:“名字”、“售卖价格"等属性;边"认识"有:“日期"属性等。
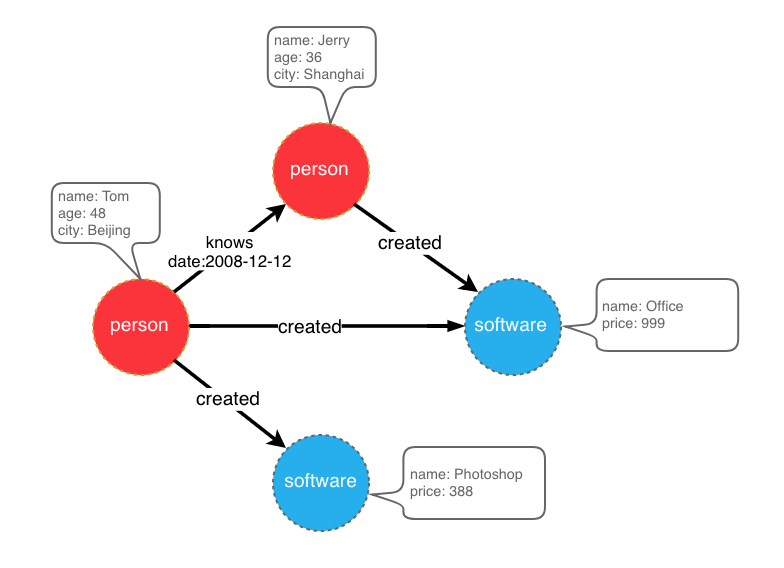
示例图模型
在设计好了图模型之后,我们可以用groovy编写出schema的定义,并保存至文件中,这里命名为schema.groovy。
// 创建一些属性
schema.propertyKey("name").asText().ifNotExist().create();
schema.propertyKey("age").asInt().ifNotExist().create();
schema.propertyKey("city").asText().ifNotExist().create();
schema.propertyKey("date").asText().ifNotExist().create();
schema.propertyKey("price").asDouble().ifNotExist().create();
// 创建 person 顶点类型,其拥有三个属性:name, age, city,主键是 name
schema.vertexLabel("person").properties("name", "age", "city").primaryKeys("name").ifNotExist().create();
// 创建 software 顶点类型,其拥有两个属性:name, price,主键是 name
schema.vertexLabel("software").properties("name", "price").primaryKeys("name").ifNotExist().create();
// 创建 knows 边类型,这类边是从 person 指向 person 的
schema.edgeLabel("knows").sourceLabel("person").targetLabel("person").ifNotExist().create();
// 创建 created 边类型,这类边是从 person 指向 software 的
schema.edgeLabel("created").sourceLabel("person").targetLabel("software").ifNotExist().create();
关于 schema 的详细说明请参考 hugegraph-client 中对应部分。
目前 HugeGraph-Loader 支持的数据源包括:
用户可以指定本地磁盘文件作为数据源,如果数据分散在多个文件中,也支持以某个目录作为数据源,但暂时不支持以多个目录作为数据源。
比如:我的数据分散在多个文件中,part-0、part-1 … part-n,要想执行导入,必须保证它们是放在一个目录下的。然后在 loader 的映射文件中,将path指定为该目录即可。
支持的文件格式包括:
TEXT 是自定义分隔符的文本文件,第一行通常是标题,记录了每一列的名称,也允许没有标题行(在映射文件中指定)。其余的每行代表一条记录,会被转化为一个顶点/边;行的每一列对应一个字段,会被转化为顶点/边的 id、label 或属性;
示例如下:
id|name|lang|price|ISBN
1|lop|java|328|ISBN978-7-107-18618-5
2|ripple|java|199|ISBN978-7-100-13678-5
CSV 是分隔符为逗号,的 TEXT 文件,当列值本身包含逗号时,该列值需要用双引号包起来,如:
marko,29,Beijing
"li,nary",26,"Wu,han"
JSON 文件要求每一行都是一个 JSON 串,且每行的格式需保持一致。
{"source_name": "marko", "target_name": "vadas", "date": "20160110", "weight": 0.5}
{"source_name": "marko", "target_name": "josh", "date": "20130220", "weight": 1.0}
用户也可以指定 HDFS 文件或目录作为数据源,上面关于本地磁盘文件或目录的要求全部适用于这里。除此之外,鉴于 HDFS 上通常存储的都是压缩文件,loader 也提供了对压缩文件的支持,并且本地磁盘文件或目录同样支持压缩文件。
目前支持的压缩文件类型包括:GZIP、BZ2、XZ、LZMA、SNAPPY_RAW、SNAPPY_FRAMED、Z、DEFLATE、LZ4_BLOCK、LZ4_FRAMED、ORC 和 PARQUET。
loader 还支持以部分关系型数据库作为数据源,目前支持 MySQL、PostgreSQL、Oracle 和 SQL Server。
但目前对表结构要求较为严格,如果导入过程中需要做关联查询,这样的表结构是不允许的。关联查询的意思是:在读到表的某行后,发现某列的值不能直接使用(比如外键),需要再去做一次查询才能确定该列的真实值。
举个例子:假设有三张表,person、software 和 created
// person 表结构
id | name | age | city
// software 表结构
id | name | lang | price
// created 表结构
id | p_id | s_id | date
如果在建模(schema)时指定 person 或 software 的 id 策略是 PRIMARY_KEY,选择以 name 作为 primary keys(注意:这是 hugegraph 中 vertexlabel 的概念),在导入边数据时,由于需要拼接出源顶点和目标顶点的 id,必须拿着 p_id/s_id 去 person/software 表中查到对应的 name,这种需要做额外查询的表结构的情况,loader 暂时是不支持的。这时可以采用以下两种方式替代:
关键点就是要让边能直接使用 p_id 和 s_id,不要再去查一次。
顶点数据文件由一行一行的数据组成,一般每一行作为一个顶点,每一列会作为顶点属性。下面以 CSV 格式作为示例进行说明。
Tom,48,Beijing
Jerry,36,Shanghai
name,price
Photoshop,999
Office,388
边数据文件由一行一行的数据组成,一般每一行作为一条边,其中有部分列会作为源顶点和目标顶点的 id,其他列作为边属性。下面以 JSON 格式作为示例进行说明。
{"source_name": "Tom", "target_name": "Jerry", "date": "2008-12-12"}
{"source_name": "Tom", "target_name": "Photoshop"}
{"source_name": "Tom", "target_name": "Office"}
{"source_name": "Jerry", "target_name": "Office"}
输入源的映射文件用于描述如何将输入源数据与图的顶点类型/边类型建立映射关系,以JSON格式组织,由多个映射块组成,其中每一个映射块都负责将一个输入源映射为顶点和边。
具体而言,每个映射块包含一个输入源和多个顶点映射与边映射块,输入源块对应上面介绍的本地磁盘文件或目录、HDFS 文件或目录和关系型数据库,负责描述数据源的基本信息,比如数据在哪,是什么格式的,分隔符是什么等。顶点映射/边映射与该输入源绑定,可以选择输入源的哪些列,哪些列作为 id、哪些列作为属性,以及每一列映射成什么属性,列的值映射成属性的什么值等等。
以最通俗的话讲,每一个映射块描述了:要导入的文件在哪,文件的每一行要作为哪一类顶点/边,文件的哪些列是需要导入的,以及这些列对应顶点/边的什么属性等。
注意:0.11.0 版本以前的映射文件与 0.11.0 以后的格式变化较大,为表述方便,下面称 0.11.0 以前的映射文件(格式)为 1.0 版本,0.11.0 以后的为 2.0 版本。并且若无特殊说明,“映射文件”表示的是 2.0 版本的。
{
"version": "2.0",
"structs": [
{
"id": "1",
"input": {
},
"vertices": [
{},
{}
],
"edges": [
{},
{}
]
}
]
}
这里直接给出两个版本的映射文件(描述了上面图模型和数据文件)
{
"version": "2.0",
"structs": [
{
"id": "1",
"skip": false,
"input": {
"type": "FILE",
"path": "vertex_person.csv",
"file_filter": {
"extensions": [
"*"
]
},
"format": "CSV",
"delimiter": ",",
"date_format": "yyyy-MM-dd HH:mm:ss",
"time_zone": "GMT+8",
"skipped_line": {
"regex": "(^#|^//).*|"
},
"compression": "NONE",
"header": [
"name",
"age",
"city"
],
"charset": "UTF-8",
"list_format": {
"start_symbol": "[",
"elem_delimiter": "|",
"end_symbol": "]"
}
},
"vertices": [
{
"label": "person",
"skip": false,
"id": null,
"unfold": false,
"field_mapping": {},
"value_mapping": {},
"selected": [],
"ignored": [],
"null_values": [
""
],
"update_strategies": {}
}
],
"edges": []
},
{
"id": "2",
"skip": false,
"input": {
"type": "FILE",
"path": "vertex_software.csv",
"file_filter": {
"extensions": [
"*"
]
},
"format": "CSV",
"delimiter": ",",
"date_format": "yyyy-MM-dd HH:mm:ss",
"time_zone": "GMT+8",
"skipped_line": {
"regex": "(^#|^//).*|"
},
"compression": "NONE",
"header": null,
"charset": "UTF-8",
"list_format": {
"start_symbol": "",
"elem_delimiter": ",",
"end_symbol": ""
}
},
"vertices": [
{
"label": "software",
"skip": false,
"id": null,
"unfold": false,
"field_mapping": {},
"value_mapping": {},
"selected": [],
"ignored": [],
"null_values": [
""
],
"update_strategies": {}
}
],
"edges": []
},
{
"id": "3",
"skip": false,
"input": {
"type": "FILE",
"path": "edge_knows.json",
"file_filter": {
"extensions": [
"*"
]
},
"format": "JSON",
"delimiter": null,
"date_format": "yyyy-MM-dd HH:mm:ss",
"time_zone": "GMT+8",
"skipped_line": {
"regex": "(^#|^//).*|"
},
"compression": "NONE",
"header": null,
"charset": "UTF-8",
"list_format": null
},
"vertices": [],
"edges": [
{
"label": "knows",
"skip": false,
"source": [
"source_name"
],
"unfold_source": false,
"target": [
"target_name"
],
"unfold_target": false,
"field_mapping": {
"source_name": "name",
"target_name": "name"
},
"value_mapping": {},
"selected": [],
"ignored": [],
"null_values": [
""
],
"update_strategies": {}
}
]
},
{
"id": "4",
"skip": false,
"input": {
"type": "FILE",
"path": "edge_created.json",
"file_filter": {
"extensions": [
"*"
]
},
"format": "JSON",
"delimiter": null,
"date_format": "yyyy-MM-dd HH:mm:ss",
"time_zone": "GMT+8",
"skipped_line": {
"regex": "(^#|^//).*|"
},
"compression": "NONE",
"header": null,
"charset": "UTF-8",
"list_format": null
},
"vertices": [],
"edges": [
{
"label": "created",
"skip": false,
"source": [
"source_name"
],
"unfold_source": false,
"target": [
"target_name"
],
"unfold_target": false,
"field_mapping": {
"source_name": "name",
"target_name": "name"
},
"value_mapping": {},
"selected": [],
"ignored": [],
"null_values": [
""
],
"update_strategies": {}
}
]
}
]
}
{
"vertices": [
{
"label": "person",
"input": {
"type": "file",
"path": "vertex_person.csv",
"format": "CSV",
"header": ["name", "age", "city"],
"charset": "UTF-8"
}
},
{
"label": "software",
"input": {
"type": "file",
"path": "vertex_software.csv",
"format": "CSV"
}
}
],
"edges": [
{
"label": "knows",
"source": ["source_name"],
"target": ["target_name"],
"input": {
"type": "file",
"path": "edge_knows.json",
"format": "JSON"
},
"field_mapping": {
"source_name": "name",
"target_name": "name"
}
},
{
"label": "created",
"source": ["source_name"],
"target": ["target_name"],
"input": {
"type": "file",
"path": "edge_created.json",
"format": "JSON"
},
"field_mapping": {
"source_name": "name",
"target_name": "name"
}
}
]
}
映射文件 1.0 版本是以顶点和边为中心,设置输入源;而 2.0 版本是以输入源为中心,设置顶点和边映射。有些输入源(比如一个文件)既能生成顶点,也能生成边,如果用 1.0 版的格式写,就需要在 vertex 和 edge 映射块中各写一次 input 块,这两次的 input 块是完全一样的;而 2.0 版本只需要写一次 input。所以 2.0 版相比于 1.0 版,能省掉一些 input 的重复书写。
在 hugegraph-loader-{version} 的 bin 目录下,有一个脚本工具 mapping-convert.sh 能直接将 1.0 版本的映射文件转换为 2.0 版本的,使用方式如下:
bin/mapping-convert.sh struct.json
会在 struct.json 的同级目录下生成一个 struct-v2.json。
输入源目前分为五类:FILE、HDFS、JDBC、KAFKA 和 GRAPH,由type节点区分,我们称为本地文件输入源、HDFS 输入源、JDBC 输入源和 KAFKA 输入源,图数据源,下面分别介绍。
path中筛选复合条件的文件,复合结构,目前只支持配置扩展名,用子节点extensions表示,默认为”*",表示保留所有文件;","作为分隔符,JSON文件不需要指定,选填;UTF-8,选填;timestamp(固定写法);GMT+8,选填;regex描述,默认不跳过任何行,选填;[, JSON 格式目前不支持指定)|, JSON 格式目前只支持原生,分隔)], JSON 格式目前不支持指定)上述本地文件输入源的节点及含义这里基本都适用,下面仅列出 HDFS 输入源不一样的和特有的节点。
fs.default.name),以及文件系统的实现(fs.hdfs.impl);前面说到过支持多种关系型数据库,但由于它们的映射结构非常相似,故统称为 JDBC 输入源,然后用vendor节点区分不同的数据库。
custom_sql 和 table 参数必须填其中一个;custom_sql 和 table 参数必须填其中一个;MYSQL
| 节点 | 固定值或常见值 |
|---|---|
| vendor | MYSQL |
| driver | com.mysql.cj.jdbc.Driver |
| url | jdbc:mysql://127.0.0.1:3306 |
schema: 可空,若填写必须与 database 的值一样
POSTGRESQL
| 节点 | 固定值或常见值 |
|---|---|
| vendor | POSTGRESQL |
| driver | org.postgresql.Driver |
| url | jdbc:postgresql://127.0.0.1:5432 |
schema: 可空,默认值为“public”
ORACLE
| 节点 | 固定值或常见值 |
|---|---|
| vendor | ORACLE |
| driver | oracle.jdbc.driver.OracleDriver |
| url | jdbc:oracle:thin:@127.0.0.1:1521 |
schema: 可空,默认值与用户名相同
SQLSERVER
| 节点 | 固定值或常见值 |
|---|---|
| vendor | SQLSERVER |
| driver | com.microsoft.sqlserver.jdbc.SQLServerDriver |
| url | jdbc:sqlserver://127.0.0.1:1433 |
schema: 必填
kafka 或 KAFKA,必填;graph 或 GRAPH,必填;DEFAULT;顶点和边映射的节点(JSON 文件中的一个 key)有很多相同的部分,下面先介绍相同部分,再分别介绍顶点映射和边映射的特有节点。
相同部分的节点
label,必填;ignored同时存在,选填;selected同时存在,选填;[1,2,3],其他列的值是18,Beijing,当设置了 unfold 之后,这一行就会变成 3 行,分别是:1,18,Beijing,2,18,Beijing和3,18,Beijing。需要注意的是此项只会展开被选作为 id 的列。默认 false,选填;更新策略支持 8 种 : (需要全大写)
SUMBIGGERSMALLERUNIONINTERSECTIONAPPENDELIMINATEOVERRIDE注意: 如果新导入的属性值为空,会采用已有的旧数据而不会采用空值,效果可以参考如下示例
// JSON 文件中以如下方式指定更新策略
{
"vertices": [
{
"label": "person",
"update_strategies": {
"age": "SMALLER",
"set": "UNION"
},
"input": {
"type": "file",
"path": "vertex_person.txt",
"format": "TEXT",
"header": ["name", "age", "set"]
}
}
]
}
// 1.写入一行带 OVERRIDE 更新策略的数据 (这里 null 代表空)
'a b null null'
// 2.再写一行
'null null c d'
// 3.最后可以得到
'a b c d'
// 如果没有更新策略,则会得到
'null null c d'
注意 : 采用了批量更新的策略后, 磁盘读请求数会大幅上升, 导入速度相比纯写覆盖会慢数倍 (此时HDD磁盘IOPS会成为瓶颈, 建议采用SSD以保证速度)
顶点映射的特有节点
CUSTOMIZE时,必填;当 id 策略为PRIMARY_KEY时,必须为空;边映射的特有节点
CUSTOMIZE时,必须指定某一列作为顶点的 id 列;当源顶点的 id 策略为 PRIMARY_KEY时,必须指定一列或多列用于拼接生成顶点的 id,也就是说,不管是哪种 id 策略,此项必填;准备好图模型、数据文件以及输入源映射关系文件后,接下来就可以将数据文件导入到图数据库中。
导入过程由用户提交的命令控制,用户可以通过不同的参数控制执行的具体流程。
| 参数 | 默认值 | 是否必传 | 描述信息 |
|---|---|---|---|
-f 或 --file | Y | 配置脚本的路径 | |
-g 或 --graph | Y | 图名称 | |
--graphspace | DEFAULT | 图空间 | |
-s 或 --schema | Y | schema 文件路径 | |
-h 或 --host 或 -i | localhost | HugeGraphServer 的地址 | |
-p 或 --port | 8080 | HugeGraphServer 的端口号 | |
--username | null | 当 HugeGraphServer 开启了权限认证时,当前图的 username | |
--password | null | 当 HugeGraphServer 开启了权限认证时,当前图的 password | |
--create-graph | false | 是否在图不存在时自动创建 | |
--token | null | 当 HugeGraphServer 开启了权限认证时,当前图的 token | |
--protocol | http | 向服务端发请求的协议,可选 http 或 https | |
--pd-peers | PD 服务节点地址 | ||
--pd-token | 访问 PD 服务的 token | ||
--meta-endpoints | 元信息存储服务地址 | ||
--direct | false | 是否直连 HugeGraph-Store | |
--route-type | NODE_PORT | 路由选择方式(可选值:NODE_PORT / DDS / BOTH) | |
--cluster | hg | 集群名 | |
--trust-store-file | 请求协议为 https 时,客户端的证书文件路径 | ||
--trust-store-password | 请求协议为 https 时,客户端证书密码 | ||
--clear-all-data | false | 导入数据前是否清除服务端的原有数据 | |
--clear-timeout | 240 | 导入数据前清除服务端的原有数据的超时时间 | |
--incremental-mode | false | 是否使用断点续导模式,仅输入源为 FILE 和 HDFS 支持该模式,启用该模式能从上一次导入停止的地方开始导入 | |
--failure-mode | false | 失败模式为 true 时,会导入之前失败了的数据,一般来说失败数据文件需要在人工更正编辑好后,再次进行导入 | |
--batch-insert-threads | CPUs | 批量插入线程池大小 (CPUs 是当前 OS 可用逻辑核个数) | |
--single-insert-threads | 8 | 单条插入线程池的大小 | |
--max-conn | 4 * CPUs | HugeClient 与 HugeGraphServer 的最大 HTTP 连接数,调整线程的时候建议同时调整此项 | |
--max-conn-per-route | 2 * CPUs | HugeClient 与 HugeGraphServer 每个路由的最大 HTTP 连接数,调整线程的时候建议同时调整此项 | |
--batch-size | 500 | 导入数据时每个批次包含的数据条数 | |
--max-parse-errors | 1 | 最多允许多少行数据解析错误,达到该值则程序退出 | |
--max-insert-errors | 500 | 最多允许多少行数据插入错误,达到该值则程序退出 | |
--timeout | 60 | 插入结果返回的超时时间(秒) | |
--shutdown-timeout | 10 | 多线程停止的等待时间(秒) | |
--retry-times | 0 | 发生特定异常时的重试次数 | |
--retry-interval | 10 | 重试之前的间隔时间(秒) | |
--check-vertex | false | 插入边时是否检查边所连接的顶点是否存在 | |
--print-progress | true | 是否在控制台实时打印导入条数 | |
--dry-run | false | 打开该模式,只解析不导入,通常用于测试 | |
--help 或 -help | false | 打印帮助信息 | |
--parser-threads 或 --parallel-count | max(2,CPUS) | 并行读取数据文件最大线程数 | |
--start-file | 0 | 用于部分(分片)导入的起始文件索引 | |
--end-file | -1 | 用于部分导入的截止文件索引 | |
--scatter-sources | false | 分散(并行)读取多个数据源以优化 I/O 性能 | |
--cdc-flush-interval | 30000 | Flink CDC 的数据刷新间隔 | |
--cdc-sink-parallelism | 1 | Flink CDC 写入端(Sink)的并行度 | |
--max-read-errors | 1 | 程序退出前允许的最大读取错误行数 | |
--max-read-lines | -1L | 最大读取行数限制;一旦达到此行数,导入任务将停止 | |
--test-mode | false | 是否开启测试模式 | |
--use-prefilter | false | 是否预先过滤顶点 | |
--short-id | [] | 将自定义 ID 映射为更短的 ID | |
--vertex-edge-limit | -1L | 单个顶点的最大边数限制 | |
--sink-type | true | 是否输出至不同的存储 | |
--vertex-partitions | 64 | HBase 顶点表的预分区数量 | |
--edge-partitions | 64 | HBase 边表的预分区数量 | |
--vertex-table-name | HBase 顶点表名称 | ||
--edge-table-name | HBase 边表名称 | ||
--hbase-zk-quorum | HBase Zookeeper 集群地址 | ||
--hbase-zk-port | HBase Zookeeper 端口号 | ||
--hbase-zk-parent | HBase Zookeeper 根路径 | ||
--restore | false | 将图模式设置为恢复模式 (RESTORING) | |
--backend | hstore | 自动创建图(如果不存在)时的后端存储类型 | |
--serializer | binary | 自动创建图(如果不存在)时的序列化器类型 | |
--scheduler-type | distributed | 自动创建图(如果不存在)时的任务调度器类型 | |
--batch-failure-fallback | true | 批量插入失败时是否回退至单条插入模式 |
通常情况下,Loader 任务都需要较长时间执行,如果因为某些原因导致导入中断进程退出,而下次希望能从中断的点继续导,这就是使用断点续导的场景。
用户设置命令行参数 –incremental-mode 为 true 即打开了断点续导模式。断点续导的关键在于进度文件,导入进程退出的时候,会把退出时刻的导入进度
记录到进度文件中,进度文件位于 ${struct} 目录下,文件名形如 load-progress ${date} ,${struct} 为映射文件的前缀,${date} 为导入开始
的时刻。比如:在 2019-10-10 12:30:30 开始的一次导入任务,使用的映射文件为 struct-example.json,则进度文件的路径为与 struct-example.json
同级的 struct-example/load-progress 2019-10-10 12:30:30。
注意:进度文件的生成与 –incremental-mode 是否打开无关,每次导入结束都会生成一个进度文件。
如果数据文件格式都是合法的,是用户自己停止(CTRL + C 或 kill,kill -9 不支持)的导入任务,也就是说没有错误记录的情况下,下一次导入只需要设置 为断点续导即可。
但如果是因为太多数据不合法或者网络异常,达到了 –max-parse-errors 或 –max-insert-errors 的限制,Loader 会把这些插入失败的原始行记录到 失败文件中,用户对失败文件中的数据行修改后,设置 –reload-failure 为 true 即可把这些"失败文件"也当作输入源进行导入(不影响正常的文件的导入), 当然如果修改后的数据行仍然有问题,则会被再次记录到失败文件中(不用担心会有重复行)。
每个顶点映射或边映射有数据插入失败时都会产生自己的失败文件,失败文件又分为解析失败文件(后缀 .parse-error)和插入失败文件(后缀 .insert-error),
它们被保存在 ${struct}/current 目录下。比如映射文件中有一个顶点映射 person 和边映射 knows,它们各有一些错误行,当 Loader 退出后,在
${struct}/current 目录下会看到如下文件:
.parse-error 和 .insert-error 并不总是一起存在的,只有存在解析出错的行才会有 .parse-error 文件,只有存在插入出错的行才会有 .insert-error 文件。
程序执行过程中各日志及错误数据会写入 hugegraph-loader.log 文件中。
运行 bin/hugegraph-loader 并传入参数
bin/hugegraph-loader -g {GRAPH_NAME} -f ${INPUT_DESC_FILE} -s ${SCHEMA_FILE} -h {HOST} -p {PORT}
下面给出的是 hugegraph-loader 包中 example 目录下的例子。(GitHub 地址)
顶点文件:example/file/vertex_person.csv
marko,29,Beijing
vadas,27,Hongkong
josh,32,Beijing
peter,35,Shanghai
"li,nary",26,"Wu,han"
tom,null,NULL
顶点文件:example/file/vertex_software.txt
id|name|lang|price|ISBN
1|lop|java|328|ISBN978-7-107-18618-5
2|ripple|java|199|ISBN978-7-100-13678-5
边文件:example/file/edge_knows.json
{"source_name": "marko", "target_name": "vadas", "date": "20160110", "weight": 0.5}
{"source_name": "marko", "target_name": "josh", "date": "20130220", "weight": 1.0}
边文件:example/file/edge_created.json
{"aname": "marko", "bname": "lop", "date": "20171210", "weight": 0.4}
{"aname": "josh", "bname": "lop", "date": "20091111", "weight": 0.4}
{"aname": "josh", "bname": "ripple", "date": "20171210", "weight": 1.0}
{"aname": "peter", "bname": "lop", "date": "20170324", "weight": 0.2}
schema.propertyKey("name").asText().ifNotExist().create();
schema.propertyKey("age").asInt().ifNotExist().create();
schema.propertyKey("city").asText().ifNotExist().create();
schema.propertyKey("weight").asDouble().ifNotExist().create();
schema.propertyKey("lang").asText().ifNotExist().create();
schema.propertyKey("date").asText().ifNotExist().create();
schema.propertyKey("price").asDouble().ifNotExist().create();
schema.vertexLabel("person").properties("name", "age", "city").primaryKeys("name").ifNotExist().create();
schema.vertexLabel("software").properties("name", "lang", "price").primaryKeys("name").ifNotExist().create();
schema.indexLabel("personByAge").onV("person").by("age").range().ifNotExist().create();
schema.indexLabel("personByCity").onV("person").by("city").secondary().ifNotExist().create();
schema.indexLabel("personByAgeAndCity").onV("person").by("age", "city").secondary().ifNotExist().create();
schema.indexLabel("softwareByPrice").onV("software").by("price").range().ifNotExist().create();
schema.edgeLabel("knows").sourceLabel("person").targetLabel("person").properties("date", "weight").ifNotExist().create();
schema.edgeLabel("created").sourceLabel("person").targetLabel("software").properties("date", "weight").ifNotExist().create();
schema.indexLabel("createdByDate").onE("created").by("date").secondary().ifNotExist().create();
schema.indexLabel("createdByWeight").onE("created").by("weight").range().ifNotExist().create();
schema.indexLabel("knowsByWeight").onE("knows").by("weight").range().ifNotExist().create();
example/file/struct.json{
"vertices": [
{
"label": "person",
"input": {
"type": "file",
"path": "example/file/vertex_person.csv",
"format": "CSV",
"header": ["name", "age", "city"],
"charset": "UTF-8",
"skipped_line": {
"regex": "(^#|^//).*"
}
},
"null_values": ["NULL", "null", ""]
},
{
"label": "software",
"input": {
"type": "file",
"path": "example/file/vertex_software.txt",
"format": "TEXT",
"delimiter": "|",
"charset": "GBK"
},
"id": "id",
"ignored": ["ISBN"]
}
],
"edges": [
{
"label": "knows",
"source": ["source_name"],
"target": ["target_name"],
"input": {
"type": "file",
"path": "example/file/edge_knows.json",
"format": "JSON",
"date_format": "yyyyMMdd"
},
"field_mapping": {
"source_name": "name",
"target_name": "name"
}
},
{
"label": "created",
"source": ["source_name"],
"target": ["target_id"],
"input": {
"type": "file",
"path": "example/file/edge_created.json",
"format": "JSON",
"date_format": "yyyy-MM-dd"
},
"field_mapping": {
"source_name": "name"
}
}
]
}
sh bin/hugegraph-loader.sh -g hugegraph -f example/file/struct.json -s example/file/schema.groovy
导入结束后,会出现类似如下统计信息:
vertices/edges has been loaded this time : 8/6
--------------------------------------------------
count metrics
input read success : 14
input read failure : 0
vertex parse success : 8
vertex parse failure : 0
vertex insert success : 8
vertex insert failure : 0
edge parse success : 6
edge parse failure : 0
edge insert success : 6
edge insert failure : 0
如果仅仅尝试使用 loader, 我们可以使用内置的 example 数据集进行导入,无需自己额外准备数据
如果使用自定义的数据,则在使用 loader 导入数据之前,我们需要将数据复制到容器内部。
首先我们可以根据 4.1-4.3 的步骤准备数据,将准备好的数据通过 docker cp 复制到 loader 容器内部。
假设我们已经按照上述的步骤准备好了对应的数据集,存放在 hugegraph-dataset 文件夹下,文件结构如下:
tree -f hugegraph-dataset/
hugegraph-dataset
├── hugegraph-dataset/edge_created.json
├── hugegraph-dataset/edge_knows.json
├── hugegraph-dataset/schema.groovy
├── hugegraph-dataset/struct.json
├── hugegraph-dataset/vertex_person.csv
└── hugegraph-dataset/vertex_software.txt
将文件复制到容器内部
docker cp hugegraph-dataset loader:/loader/dataset
docker exec -it loader ls /loader/dataset
edge_created.json edge_knows.json schema.groovy struct.json vertex_person.csv vertex_software.txt
以内置的 example 数据集为例,我们可以使用以下的命令对数据进行导入。
如果需要导入自己准备的数据集,则只需要修改 -f 配置脚本的路径 以及 -s schema 文件路径即可。
其他的参数可以参照 3.4.1 参数说明
docker exec -it loader bin/hugegraph-loader.sh -g hugegraph -f example/file/struct.json -s example/file/schema.groovy -h server -p 8080
如果导入用户自定义的数据集,按照刚才的例子,则使用:
docker exec -it loader bin/hugegraph-loader.sh -g hugegraph -f /loader/dataset/struct.json -s /loader/dataset/schema.groovy -h server -p 8080
如果
loader和server位于同一 docker 网络,则可以指定-h {server_container_name}, 否则需要指定server的宿主机的 ip (在我们的例子中,server_container_name为server).
然后我们可以观察到结果:
HugeGraphLoader worked in NORMAL MODE
vertices/edges loaded this time : 8/6
--------------------------------------------------
count metrics
input read success : 14
input read failure : 0
vertex parse success : 8
vertex parse failure : 0
vertex insert success : 8
vertex insert failure : 0
edge parse success : 6
edge parse failure : 0
edge insert success : 6
edge insert failure : 0
--------------------------------------------------
meter metrics
total time : 0.199s
read time : 0.046s
load time : 0.153s
vertex load time : 0.077s
vertex load rate(vertices/s) : 103
edge load time : 0.112s
edge load rate(edges/s) : 53
也可以使用 curl 或者 hubble观察导入结果,此处以 curl 为例:
> curl "http://localhost:8080/graphs/hugegraph/graph/vertices" | gunzip
{"vertices":[{"id":1,"label":"software","type":"vertex","properties":{"name":"lop","lang":"java","price":328.0}},{"id":2,"label":"software","type":"vertex","properties":{"name":"ripple","lang":"java","price":199.0}},{"id":"1:tom","label":"person","type":"vertex","properties":{"name":"tom"}},{"id":"1:josh","label":"person","type":"vertex","properties":{"name":"josh","age":32,"city":"Beijing"}},{"id":"1:marko","label":"person","type":"vertex","properties":{"name":"marko","age":29,"city":"Beijing"}},{"id":"1:peter","label":"person","type":"vertex","properties":{"name":"peter","age":35,"city":"Shanghai"}},{"id":"1:vadas","label":"person","type":"vertex","properties":{"name":"vadas","age":27,"city":"Hongkong"}},{"id":"1:li,nary","label":"person","type":"vertex","properties":{"name":"li,nary","age":26,"city":"Wu,han"}}]}
如果想检查边的导入结果,可以使用 curl "http://localhost:8080/graphs/hugegraph/graph/edges" | gunzip
除了直接使用 docker exec 导入数据,我们也可以进入容器进行数据导入,基本流程与 4.5.1 相同
使用 docker exec -it loader bash进入容器内部,并执行命令
sh bin/hugegraph-loader.sh -g hugegraph -f example/file/struct.json -s example/file/schema.groovy -h server -p 8080
执行的结果如 4.5.1 所示
Spark 版本:Spark 3+,其他版本未测试。 HugeGraph Toolchain 版本:toolchain-1.0.0
spark-loader 的参数分为两部分,注意:因二者参数名缩写存在重合部分,请使用参数全称。两种参数之间无需保证先后顺序。
示例:
sh bin/hugegraph-spark-loader.sh --master yarn \
--deploy-mode cluster --name spark-hugegraph-loader --file ./hugegraph.json \
--username admin --token admin --host xx.xx.xx.xx --port 8093 \
--graph graph-test --num-executors 6 --executor-cores 16 --executor-memory 15g
HugeGraph-Tools 是 HugeGraph 的自动化部署、管理和备份/还原组件。
测试指南:如需在本地运行 Tools 测试,请参考 工具链本地测试指南
有两种方式可以获取 HugeGraph-Tools:(它被包含子 Toolchain 中)
下载最新版本的 HugeGraph-Toolchain 包, 然后进入 tools 子目录
wget https://downloads.apache.org/hugegraph/1.0.0/apache-hugegraph-toolchain-incubating-1.0.0.tar.gz
tar zxf *hugegraph*.tar.gz
源码编译前请确保安装了wget命令
下载最新版本的 HugeGraph-Toolchain 源码包, 然后根目录编译或者单独编译 tool 子模块:
# 1. get from github
git clone https://github.com/apache/hugegraph-toolchain.git
# 2. get from direct (e.g. here is 1.0.0, please choose the latest version)
wget https://downloads.apache.org/hugegraph/1.0.0/apache-hugegraph-toolchain-incubating-1.0.0-src.tar.gz
编译生成 tar 包:
cd hugegraph-tools
mvn package -DskipTests
生成 tar 包 hugegraph-tools-${version}.tar.gz
解压后,进入 hugegraph-tools 目录,可以使用bin/hugegraph或者bin/hugegraph help来查看 usage 信息。主要分为:
Usage: hugegraph [options] [command] [command options]
options是 HugeGraph-Tools 的全局变量,可以在 hugegraph-tools/bin/hugegraph 中配置,包括:
上述全局变量,也可以通过环境变量来设置。一种方式是在命令行使用 export 设置临时环境变量,在该命令行关闭之前均有效
| 全局变量 | 环境变量 | 示例 |
|---|---|---|
| –url | HUGEGRAPH_URL | export HUGEGRAPH_URL=http://127.0.0.1:8080 |
| –graph | HUGEGRAPH_GRAPH | export HUGEGRAPH_GRAPH=hugegraph |
| –user | HUGEGRAPH_USERNAME | export HUGEGRAPH_USERNAME=admin |
| –password | HUGEGRAPH_PASSWORD | export HUGEGRAPH_PASSWORD=test |
| –timeout | HUGEGRAPH_TIMEOUT | export HUGEGRAPH_TIMEOUT=30 |
| –trust-store-file | HUGEGRAPH_TRUST_STORE_FILE | export HUGEGRAPH_TRUST_STORE_FILE=/tmp/trust-store |
| –trust-store-password | HUGEGRAPH_TRUST_STORE_PASSWORD | export HUGEGRAPH_TRUST_STORE_PASSWORD=xxxx |
另一种方式是在 bin/hugegraph 脚本中设置环境变量:
#!/bin/bash
# Set environment here if needed
#export HUGEGRAPH_URL=
#export HUGEGRAPH_GRAPH=
#export HUGEGRAPH_USERNAME=
#export HUGEGRAPH_PASSWORD=
#export HUGEGRAPH_TIMEOUT=
#export HUGEGRAPH_TRUST_STORE_FILE=
#export HUGEGRAPH_TRUST_STORE_PASSWORD=
当需要把备份的图原样恢复到一个新的图中的时候,需要先将图模式设置为 RESTORING 模式;当需要将备份的图合并到已存在的图中时,需要先将图模式设置为 MERGING 模式。
–file 和 –script 二者互斥,必须设置其中之一
–file 和 –script 二者互斥,必须设置其中之一
只有当 –format 为 json 执行 backup 时,才可以使用 restore 命令恢复
vertex vertex-edge1 vertex-edge2...JSON格式存储。
用户也可以自定义存储格式,只需要在hugegraph-tools/src/main/java/com/baidu/hugegraph/formatter
目录下实现一个继承自Formatter的类,例如CustomFormatter,使用时指定该类为formatter即可,例如
bin/hugegraph dump -f CustomFormatterdeploy命令中有可选参数 -u,提供时会使用指定的下载地址替代默认下载地址下载 tar 包,并且将地址写入
~/hugegraph-download-url-prefix文件中;之后如果不指定地址时,会优先从~/hugegraph-download-url-prefix指定的地址下载 tar 包;如果 -u 和~/hugegraph-download-url-prefix都没有时,会从默认下载地址进行下载
各子命令的具体参数如下:
Usage: hugegraph [options] [command] [command options]
Options:
--graph
Name of graph
Default: hugegraph
--password
Password of user
--timeout
Connection timeout
Default: 30
--trust-store-file
The path of client truststore file used when https protocol is enabled
--trust-store-password
The password of the client truststore file used when the https protocol
is enabled
--url
The URL of HugeGraph-Server
Default: http://127.0.0.1:8080
--user
Name of user
Commands:
graph-list List all graphs
Usage: graph-list
graph-get Get graph info
Usage: graph-get
graph-clear Clear graph schema and data
Usage: graph-clear [options]
Options:
* --confirm-message, -c
Confirm message of graph clear is "I'm sure to delete all data".
(Note: include "")
graph-mode-set Set graph mode
Usage: graph-mode-set [options]
Options:
* --graph-mode, -m
Graph mode, include: [NONE, RESTORING, MERGING]
Possible Values: [NONE, RESTORING, MERGING, LOADING]
graph-mode-get Get graph mode
Usage: graph-mode-get
task-list List tasks
Usage: task-list [options]
Options:
--limit
Limit number, no limit if not provided
Default: -1
--status
Status of task
task-get Get task info
Usage: task-get [options]
Options:
* --task-id
Task id
Default: 0
task-delete Delete task
Usage: task-delete [options]
Options:
* --task-id
Task id
Default: 0
task-cancel Cancel task
Usage: task-cancel [options]
Options:
* --task-id
Task id
Default: 0
task-clear Clear completed tasks
Usage: task-clear [options]
Options:
--force
Force to clear all tasks, cancel all uncompleted tasks firstly,
and delete all completed tasks
Default: false
gremlin-execute Execute Gremlin statements
Usage: gremlin-execute [options]
Options:
--aliases, -a
Gremlin aliases, valid format is: 'key1=value1,key2=value2...'
Default: {}
--bindings, -b
Gremlin bindings, valid format is: 'key1=value1,key2=value2...'
Default: {}
--file, -f
Gremlin Script file to be executed, UTF-8 encoded, exclusive to
--script
--language, -l
Gremlin script language
Default: gremlin-groovy
--script, -s
Gremlin script to be executed, exclusive to --file
gremlin-schedule Execute Gremlin statements as asynchronous job
Usage: gremlin-schedule [options]
Options:
--bindings, -b
Gremlin bindings, valid format is: 'key1=value1,key2=value2...'
Default: {}
--file, -f
Gremlin Script file to be executed, UTF-8 encoded, exclusive to
--script
--language, -l
Gremlin script language
Default: gremlin-groovy
--script, -s
Gremlin script to be executed, exclusive to --file
backup Backup graph schema/data. If directory is on HDFS, use -D to
set HDFS params. For exmaple:
-Dfs.default.name=hdfs://localhost:9000
Usage: backup [options]
Options:
--all-properties
All properties to be backup flag
Default: false
--compress
compress flag
Default: true
--directory, -d
Directory of graph schema/data, default is './{graphname}' in
local file system or '{fs.default.name}/{graphname}' in HDFS
--format
File format, valid is [json, text]
Default: json
--huge-types, -t
Type of schema/data. Concat with ',' if more than one. 'all' means
all vertices, edges and schema, in other words, 'all' equals with
'vertex,edge,vertex_label,edge_label,property_key,index_label'
Default: [PROPERTY_KEY, VERTEX_LABEL, EDGE_LABEL, INDEX_LABEL, VERTEX, EDGE]
--label
Vertex or edge label, only valid when type is vertex or edge
--log, -l
Directory of log
Default: ./logs
--properties
Vertex or edge properties to backup, only valid when type is
vertex or edge
Default: []
--retry
Retry times, default is 3
Default: 3
--split-size, -s
Split size of shard
Default: 1048576
-D
HDFS config parameters
Syntax: -Dkey=value
Default: {}
schedule-backup Schedule backup task
Usage: schedule-backup [options]
Options:
--backup-num
The number of latest backups to keep
Default: 3
* --directory, -d
The directory of backups stored
--interval
The interval of backup, format is: "a b c d e". 'a' means minute
(0 - 59), 'b' means hour (0 - 23), 'c' means day of month (1 -
31), 'd' means month (1 - 12), 'e' means day of week (0 - 6)
(Sunday=0), "*" means all
Default: "0 0 * * *"
dump Dump graph to files
Usage: dump [options]
Options:
--directory, -d
Directory of graph schema/data, default is './{graphname}' in
local file system or '{fs.default.name}/{graphname}' in HDFS
--formatter, -f
Formatter to customize format of vertex/edge
Default: JsonFormatter
--log, -l
Directory of log
Default: ./logs
--retry
Retry times, default is 3
Default: 3
--split-size, -s
Split size of shard
Default: 1048576
-D
HDFS config parameters
Syntax: -Dkey=value
Default: {}
restore Restore graph schema/data. If directory is on HDFS, use -D to
set HDFS params if needed. For
exmaple:-Dfs.default.name=hdfs://localhost:9000
Usage: restore [options]
Options:
--clean
Whether to remove the directory of graph data after restored
Default: false
--directory, -d
Directory of graph schema/data, default is './{graphname}' in
local file system or '{fs.default.name}/{graphname}' in HDFS
--huge-types, -t
Type of schema/data. Concat with ',' if more than one. 'all' means
all vertices, edges and schema, in other words, 'all' equals with
'vertex,edge,vertex_label,edge_label,property_key,index_label'
Default: [PROPERTY_KEY, VERTEX_LABEL, EDGE_LABEL, INDEX_LABEL, VERTEX, EDGE]
--log, -l
Directory of log
Default: ./logs
--retry
Retry times, default is 3
Default: 3
-D
HDFS config parameters
Syntax: -Dkey=value
Default: {}
migrate Migrate graph
Usage: migrate [options]
Options:
--directory, -d
Directory of graph schema/data, default is './{graphname}' in
local file system or '{fs.default.name}/{graphname}' in HDFS
--graph-mode, -m
Mode used when migrating to target graph, include: [RESTORING,
MERGING]
Default: RESTORING
Possible Values: [NONE, RESTORING, MERGING, LOADING]
--huge-types, -t
Type of schema/data. Concat with ',' if more than one. 'all' means
all vertices, edges and schema, in other words, 'all' equals with
'vertex,edge,vertex_label,edge_label,property_key,index_label'
Default: [PROPERTY_KEY, VERTEX_LABEL, EDGE_LABEL, INDEX_LABEL, VERTEX, EDGE]
--keep-local-data
Whether to keep the local directory of graph data after restored
Default: false
--log, -l
Directory of log
Default: ./logs
--retry
Retry times, default is 3
Default: 3
--split-size, -s
Split size of shard
Default: 1048576
--target-graph
The name of target graph to migrate
Default: hugegraph
--target-password
The password of target graph to migrate
--target-timeout
The timeout to connect target graph to migrate
Default: 0
--target-trust-store-file
The trust store file of target graph to migrate
--target-trust-store-password
The trust store password of target graph to migrate
--target-url
The url of target graph to migrate
Default: http://127.0.0.1:8081
--target-user
The username of target graph to migrate
-D
HDFS config parameters
Syntax: -Dkey=value
Default: {}
deploy Install HugeGraph-Server and HugeGraph-Studio
Usage: deploy [options]
Options:
* -p
Install path of HugeGraph-Server and HugeGraph-Studio
-u
Download url prefix path of HugeGraph-Server and HugeGraph-Studio
* -v
Version of HugeGraph-Server and HugeGraph-Studio
start-all Start HugeGraph-Server and HugeGraph-Studio
Usage: start-all [options]
Options:
* -p
Install path of HugeGraph-Server and HugeGraph-Studio
* -v
Version of HugeGraph-Server and HugeGraph-Studio
clear Clear HugeGraph-Server and HugeGraph-Studio
Usage: clear [options]
Options:
* -p
Install path of HugeGraph-Server and HugeGraph-Studio
stop-all Stop HugeGraph-Server and HugeGraph-Studio
Usage: stop-all
help Print usage
Usage: help
# 同步执行gremlin
./bin/hugegraph --url http://127.0.0.1:8080 --graph hugegraph gremlin-execute --script 'g.V().count()'
# 异步执行gremlin
./bin/hugegraph --url http://127.0.0.1:8080 --graph hugegraph gremlin-schedule --script 'g.V().count()'
./bin/hugegraph --url http://127.0.0.1:8080 --graph hugegraph task-list
./bin/hugegraph --url http://127.0.0.1:8080 --graph hugegraph task-list --limit 5
./bin/hugegraph --url http://127.0.0.1:8080 --graph hugegraph task-list --status success
./bin/hugegraph --url http://127.0.0.1:8080 --graph hugegraph graph-mode-set -m RESTORING MERGING NONE
./bin/hugegraph --url http://127.0.0.1:8080 --graph hugegraph graph-mode-set -m RESTORING
./bin/hugegraph --url http://127.0.0.1:8080 --graph hugegraph graph-mode-get
./bin/hugegraph --url http://127.0.0.1:8080 --graph hugegraph graph-list
./bin/hugegraph --url http://127.0.0.1:8080 --graph hugegraph graph-clear -c "I'm sure to delete all data"
./bin/hugegraph --url http://127.0.0.1:8080 --graph hugegraph backup -t all --directory ./backup-test
./bin/hugegraph --url http://127.0.0.1:8080 --graph hugegraph --interval */2 * * * * schedule-backup -d ./backup-0.10.2
# 设置图模式
./bin/hugegraph --url http://127.0.0.1:8080 --graph hugegraph graph-mode-set -m RESTORING
# 恢复图
./bin/hugegraph --url http://127.0.0.1:8080 --graph hugegraph restore -t all --directory ./backup-test
# 恢复图模式
./bin/hugegraph --url http://127.0.0.1:8080 --graph hugegraph graph-mode-set -m NONE
./bin/hugegraph --url http://127.0.0.1:8080 --graph hugegraph migrate --target-url http://127.0.0.1:8090 --target-graph hugegraph
HugeGraph-Spark-Connector 是一个用于在 Spark 中以标准格式读写 HugeGraph 数据的连接器应用程序。
mvn clean package -DskipTests
mvn clean package
首先在你的 pom.xml 中添加依赖:
<dependency>
<groupId>org.apache.hugegraph</groupId>
<artifactId>hugegraph-spark-connector</artifactId>
<version>${revision}</version>
</dependency>
假设我们有一个图,其 schema 定义如下:
schema.propertyKey("name").asText().ifNotExist().create()
schema.propertyKey("age").asInt().ifNotExist().create()
schema.propertyKey("city").asText().ifNotExist().create()
schema.propertyKey("weight").asDouble().ifNotExist().create()
schema.propertyKey("lang").asText().ifNotExist().create()
schema.propertyKey("date").asText().ifNotExist().create()
schema.propertyKey("price").asDouble().ifNotExist().create()
schema.vertexLabel("person")
.properties("name", "age", "city")
.useCustomizeStringId()
.nullableKeys("age", "city")
.ifNotExist()
.create()
schema.vertexLabel("software")
.properties("name", "lang", "price")
.primaryKeys("name")
.ifNotExist()
.create()
schema.edgeLabel("knows")
.sourceLabel("person")
.targetLabel("person")
.properties("date", "weight")
.ifNotExist()
.create()
schema.edgeLabel("created")
.sourceLabel("person")
.targetLabel("software")
.properties("date", "weight")
.ifNotExist()
.create()
val df = sparkSession.createDataFrame(Seq(
Tuple3("marko", 29, "Beijing"),
Tuple3("vadas", 27, "HongKong"),
Tuple3("Josh", 32, "Beijing"),
Tuple3("peter", 35, "ShangHai"),
Tuple3("li,nary", 26, "Wu,han"),
Tuple3("Bob", 18, "HangZhou"),
)) toDF("name", "age", "city")
df.show()
df.write
.format("org.apache.hugegraph.spark.connector.DataSource")
.option("host", "127.0.0.1")
.option("port", "8080")
.option("graph", "hugegraph")
.option("data-type", "vertex")
.option("label", "person")
.option("id", "name")
.option("batch-size", 2)
.mode(SaveMode.Overwrite)
.save()
val df = sparkSession.createDataFrame(Seq(
Tuple4("marko", "vadas", "20160110", 0.5),
Tuple4("peter", "Josh", "20230801", 1.0),
Tuple4("peter", "li,nary", "20130220", 2.0)
)).toDF("source", "target", "date", "weight")
df.show()
df.write
.format("org.apache.hugegraph.spark.connector.DataSource")
.option("host", "127.0.0.1")
.option("port", "8080")
.option("graph", "hugegraph")
.option("data-type", "edge")
.option("label", "knows")
.option("source-name", "source")
.option("target-name", "target")
.option("batch-size", 2)
.mode(SaveMode.Overwrite)
.save()
客户端配置用于配置 hugegraph-client。
| 参数 | 默认值 | 说明 |
|---|---|---|
host | localhost | HugeGraphServer 的地址 |
port | 8080 | HugeGraphServer 的端口 |
graph | hugegraph | 图空间名称 |
protocol | http | 向服务器发送请求的协议,可选 http 或 https |
username | null | 当 HugeGraphServer 开启权限认证时,当前图的用户名 |
token | null | 当 HugeGraphServer 开启权限认证时,当前图的 token |
timeout | 60 | 插入结果返回的超时时间(秒) |
max-conn | CPUS * 4 | HugeClient 与 HugeGraphServer 之间的最大 HTTP 连接数 |
max-conn-per-route | CPUS * 2 | HugeClient 与 HugeGraphServer 之间每个路由的最大 HTTP 连接数 |
trust-store-file | null | 当请求协议为 https 时,客户端的证书文件路径 |
trust-store-token | null | 当请求协议为 https 时,客户端的证书密码 |
图数据配置用于设置图空间的配置。
| 参数 | 默认值 | 说明 |
|---|---|---|
data-type | 图数据类型,必须是 vertex 或 edge | |
label | 要导入的顶点/边数据所属的标签 | |
id | 指定某一列作为顶点的 id 列。当顶点 id 策略为 CUSTOMIZE 时,必填;当 id 策略为 PRIMARY_KEY 时,必须为空 | |
source-name | 选择输入源的某些列作为源顶点的 id 列。当源顶点的 id 策略为 CUSTOMIZE 时,必须指定某一列作为顶点的 id 列;当源顶点的 id 策略为 PRIMARY_KEY 时,必须指定一列或多列用于拼接生成顶点的 id,即无论使用哪种 id 策略,此项都是必填的 | |
target-name | 指定某些列作为目标顶点的 id 列,与 source-name 类似 | |
selected-fields | 选择某些列进行插入,其他未选择的列不插入,不能与 ignored-fields 同时存在 | |
ignored-fields | 忽略某些列使其不参与插入,不能与 selected-fields 同时存在 | |
batch-size | 500 | 导入数据时每批数据的条目数 |
通用配置包含一些常用的配置项。
| 参数 | 默认值 | 说明 |
|---|---|---|
delimiter | , | source-name、target-name、selected-fields 或 ignored-fields 的分隔符 |
与 HugeGraph 一样,hugegraph-spark-connector 也采用 Apache 2.0 许可证。