This is the multi-page printable view of this section. Click here to print.
API
- 1: HugeGraph RESTful API
- 1.1: Graphspace API
- 1.2: Schema API
- 1.3: PropertyKey API
- 1.4: VertexLabel API
- 1.5: EdgeLabel API
- 1.6: IndexLabel API
- 1.7: Rebuild API
- 1.8: Vertex API
- 1.9: Edge API
- 1.10: Traverser API
- 1.11: Rank API
- 1.12: Variable API
- 1.13: Graphs API
- 1.14: Task API
- 1.15: Gremlin API
- 1.16: Cypher API
- 1.17: Authentication API
- 1.18: Metrics API
- 1.19: Other API
- 2: HugeGraph Java Client
- 3: Gremlin-Console
1 - HugeGraph RESTful API
⚠️ Version compatibility notes
- HugeGraph 1.7.0+ introduces graphspaces, and REST paths follow
/graphspaces/{graphspace}/graphs/{graph}.- HugeGraph 1.5.x and earlier still rely on the legacy
/graphs/{graph}path, and the create/clone graph APIs requireContent-Type: text/plain; 1.7.0+ expects JSON bodies.- The default graphspace name is
DEFAULT, which you can use directly if you do not need multi-tenant isolation.- Note: Before version 1.5.0, the format of ids such as group/target was similar to -69:grant. After version 1.7.0, the id and name were consistent, such as admin HugeGraph 1.5.x RESTful API
Besides the documentation below, you can also open swagger-ui at localhost:8080/swagger-ui/index.html to explore the RESTful API. Here is an example
1.1 - Graphspace API
2.0 Graphspace
HugeGraph implements multi-tenancy through graph spaces, which isolate compute/storage resources per tenant.
Prerequisites
- Graphspace currently only works in HStore mode.
- In non-HStore mode you can only use the default graphspace
DEFAULT; creating/deleting/updating other graphspaces is not supported. - Set
usePD=trueinrest-server.propertiesandbackend=hstoreinhugegraph.properties. - Graphspace enables strict authentication by default (default credential:
admin:pa). Change the password immediately to avoid unauthorized access.
2.0.1 Create a graphspace
Method & Url
POST http://localhost:8080/graphspaces
Request Body
Note: CPU/memory and Kubernetes-related capabilities are not publicly available yet.
| Name | Required | Type | Default | Range/Note | Description |
|---|---|---|---|---|---|
| name | Yes | String | Lowercase letters, digits, underscore; must start with a letter; max length 48 | Graphspace name | |
| description | Yes | String | Description | ||
| cpu_limit | Yes | Int | > 0 | CPU cores for the graphspace | |
| memory_limit | Yes | Int | > 0 (GB) | Memory quota in GB | |
| storage_limit | Yes | Int | > 0 | Maximum disk usage | |
| compute_cpu_limit | No | Int | 0 | >= 0 | Extra HugeGraph-Computer CPU cores; falls back to cpu_limit if unset or 0 |
| compute_memory_limit | No | Int | 0 | >= 0 | Extra HugeGraph-Computer memory in GB; falls back to memory_limit if unset or 0 |
| oltp_namespace | Yes | String | Kubernetes namespace for OLTP HugeGraph-Server | ||
| olap_namespace | Yes | String | Resources are merged when identical to oltp_namespace | Kubernetes namespace for OLAP / HugeGraph-Computer | |
| storage_namespace | Yes | String | Kubernetes namespace for HugeGraph-Store | ||
| operator_image_path | No | String | HugeGraph-Computer operator image registry | ||
| internal_algorithm_image_url | No | String | HugeGraph-Computer algorithm image registry | ||
| max_graph_number | Yes | Int | > 0 | Maximum number of graphs that can be created inside the graphspace | |
| max_role_number | Yes | Int | > 0 | Maximum number of roles that can be created inside the graphspace | |
| auth | No | Boolean | false | true / false | Whether to enable authentication for the graphspace |
| configs | No | Map | Additional configuration |
{
"name": "gs1",
"description": "1st graph space",
"max_graph_number": 100,
"cpu_limit": 1000,
"memory_limit": 8192,
"storage_limit": 1000000,
"max_role_number": 10,
"auth": true,
"configs": {}
}
Response Status
201
Response Body
{
"name": "gs1",
"description": "1st graph space",
"cpu_limit": 1000,
"memory_limit": 8192,
"storage_limit": 1000000,
"compute_cpu_limit": 0,
"compute_memory_limit": 0,
"oltp_namespace": "hugegraph-server",
"olap_namespace": "hugegraph-server",
"storage_namespace": "hugegraph-server",
"operator_image_path": "127.0.0.1/hugegraph-registry/hugegraph-computer-operator:3.1.1",
"internal_algorithm_image_url": "127.0.0.1/hugegraph-registry/hugegraph-computer-algorithm:3.1.1",
"max_graph_number": 100,
"max_role_number": 10,
"cpu_used": 0,
"memory_used": 0,
"storage_used": 0,
"graph_number_used": 0,
"role_number_used": 0,
"auth": true
}
2.0.2 List all graphspaces
Method & Url
GET http://localhost:8080/graphspaces
Response Status
200
Response Body
{
"graphSpaces": [
"gs1",
"DEFAULT"
]
}
2.0.3 Get graphspace details
Params
Path parameters
- graphspace: Graphspace name
Method & Url
GET http://localhost:8080/graphspaces/gs1
Response Status
200
Response Body
{
"name": "gs1",
"description": "1st graph space",
"cpu_limit": 1000,
"memory_limit": 8192,
"storage_limit": 1000000,
"oltp_namespace": "hugegraph-server",
"olap_namespace": "hugegraph-server",
"storage_namespace": "hugegraph-server",
"operator_image_path": "127.0.0.1/hugegraph-registry/hugegraph-computer-operator:3.1.1",
"internal_algorithm_image_url": "127.0.0.1/hugegraph-registry/hugegraph-computer-algorithm:3.1.1",
"compute_cpu_limit": 0,
"compute_memory_limit": 0,
"max_graph_number": 100,
"max_role_number": 10,
"cpu_used": 0,
"memory_used": 0,
"storage_used": 0,
"graph_number_used": 0,
"role_number_used": 0,
"auth": true
}
2.0.4 Update a graphspace
authcannot be changed once a graphspace is created.
Params
Path parameter
- graphspace: Graphspace name
Request parameters
- action: Must be
"update" - update: Container for the actual fields to update (see table below)
| Name | Required | Type | Range/Note | Description |
|---|---|---|---|---|
| name | Yes | String | Graphspace name | |
| description | Yes | String | Description | |
| cpu_limit | Yes | Int | > 0 | CPU cores for OLTP HugeGraph-Server |
| memory_limit | Yes | Int | > 0 (GB) | Memory quota (GB) for OLTP HugeGraph-Server |
| storage_limit | Yes | Int | > 0 | Maximum disk usage |
| compute_cpu_limit | No | Int | >= 0 | Extra HugeGraph-Computer CPU cores; falls back to cpu_limit if unset or 0 |
| compute_memory_limit | No | Int | >= 0 | Extra HugeGraph-Computer memory in GB; falls back to memory_limit if unset or 0 |
| oltp_namespace | Yes | String | Kubernetes namespace for OLTP HugeGraph-Server | |
| olap_namespace | Yes | String | Resources are merged when identical to oltp_namespace | Kubernetes namespace for OLAP |
| storage_namespace | Yes | String | Kubernetes namespace for HugeGraph-Store | |
| operator_image_path | No | String | HugeGraph-Computer operator image registry | |
| internal_algorithm_image_url | No | String | HugeGraph-Computer algorithm image registry | |
| max_graph_number | Yes | Int | > 0 | Maximum number of graphs |
| max_role_number | Yes | Int | > 0 | Maximum number of roles |
Method & Url
PUT http://localhost:8080/graphspaces/gs1
Request Body
{
"action": "update",
"update": {
"name": "gs1",
"description": "1st graph space",
"cpu_limit": 2000,
"memory_limit": 40960,
"storage_limit": 2048,
"oltp_namespace": "hugegraph-server",
"olap_namespace": "hugegraph-server",
"operator_image_path": "127.0.0.1/hugegraph-registry/hugegraph-computer-operator:3.1.1",
"internal_algorithm_image_url": "127.0.0.1/hugegraph-registry/hugegraph-computer-algorithm:3.1.1",
"max_graph_number": 1000,
"max_role_number": 100
}
}
Response Status
200
Response Body
{
"name": "gs1",
"description": "1st graph space",
"cpu_limit": 2000,
"memory_limit": 40960,
"storage_limit": 2048,
"oltp_namespace": "hugegraph-server",
"olap_namespace": "hugegraph-server",
"storage_namespace": "hugegraph-server",
"operator_image_path": "127.0.0.1/hugegraph-registry/hugegraph-computer-operator:3.1.1",
"internal_algorithm_image_url": "127.0.0.1/hugegraph-registry/hugegraph-computer-algorithm:3.1.1",
"compute_cpu_limit": 0,
"compute_memory_limit": 0,
"max_graph_number": 1000,
"max_role_number": 100,
"cpu_used": 0,
"memory_used": 0,
"storage_used": 0,
"graph_number_used": 0,
"role_number_used": 0,
"auth": true
}
2.0.5 Delete a graphspace
Params
Path parameter
- graphspace: Graphspace name
Method & Url
DELETE http://localhost:8080/graphspaces/gs1
Response Status
204
Warning: deleting a graphspace releases all resources that belong to it.
1.2 - Schema API
1.1 Schema
HugeGraph provides a single interface to get all Schema information of a graph, including: PropertyKey, VertexLabel, EdgeLabel and IndexLabel.
Method & Url
GET http://localhost:8080/graphspaces/{graphspace}/graphs/{graph_name}/schema
e.g: GET http://localhost:8080/graphspaces/DEFAULT/graphs/hugegraph/schema
Response Status
200
Response Body
{
"propertykeys": [
{
"id": 7,
"name": "price",
"data_type": "DOUBLE",
"cardinality": "SINGLE",
"aggregate_type": "NONE",
"write_type": "OLTP",
"properties": [],
"status": "CREATED",
"user_data": {
"~create_time": "2023-05-08 17:49:05.316"
}
},
{
"id": 6,
"name": "date",
"data_type": "TEXT",
"cardinality": "SINGLE",
"aggregate_type": "NONE",
"write_type": "OLTP",
"properties": [],
"status": "CREATED",
"user_data": {
"~create_time": "2023-05-08 17:49:05.309"
}
},
{
"id": 3,
"name": "city",
"data_type": "TEXT",
"cardinality": "SINGLE",
"aggregate_type": "NONE",
"write_type": "OLTP",
"properties": [],
"status": "CREATED",
"user_data": {
"~create_time": "2023-05-08 17:49:05.287"
}
},
{
"id": 2,
"name": "age",
"data_type": "INT",
"cardinality": "SINGLE",
"aggregate_type": "NONE",
"write_type": "OLTP",
"properties": [],
"status": "CREATED",
"user_data": {
"~create_time": "2023-05-08 17:49:05.280"
}
},
{
"id": 5,
"name": "lang",
"data_type": "TEXT",
"cardinality": "SINGLE",
"aggregate_type": "NONE",
"write_type": "OLTP",
"properties": [],
"status": "CREATED",
"user_data": {
"~create_time": "2023-05-08 17:49:05.301"
}
},
{
"id": 4,
"name": "weight",
"data_type": "DOUBLE",
"cardinality": "SINGLE",
"aggregate_type": "NONE",
"write_type": "OLTP",
"properties": [],
"status": "CREATED",
"user_data": {
"~create_time": "2023-05-08 17:49:05.294"
}
},
{
"id": 1,
"name": "name",
"data_type": "TEXT",
"cardinality": "SINGLE",
"aggregate_type": "NONE",
"write_type": "OLTP",
"properties": [],
"status": "CREATED",
"user_data": {
"~create_time": "2023-05-08 17:49:05.250"
}
}
],
"vertexlabels": [
{
"id": 1,
"name": "person",
"id_strategy": "PRIMARY_KEY",
"primary_keys": [
"name"
],
"nullable_keys": [
"age",
"city"
],
"index_labels": [
"personByAge",
"personByCity",
"personByAgeAndCity"
],
"properties": [
"name",
"age",
"city"
],
"status": "CREATED",
"ttl": 0,
"enable_label_index": true,
"user_data": {
"~create_time": "2023-05-08 17:49:05.336"
}
},
{
"id": 2,
"name": "software",
"id_strategy": "CUSTOMIZE_NUMBER",
"primary_keys": [],
"nullable_keys": [],
"index_labels": [
"softwareByPrice"
],
"properties": [
"name",
"lang",
"price"
],
"status": "CREATED",
"ttl": 0,
"enable_label_index": true,
"user_data": {
"~create_time": "2023-05-08 17:49:05.347"
}
}
],
"edgelabels": [
{
"id": 1,
"name": "knows",
"source_label": "person",
"target_label": "person",
"frequency": "SINGLE",
"sort_keys": [],
"nullable_keys": [],
"index_labels": [
"knowsByWeight"
],
"properties": [
"weight",
"date"
],
"status": "CREATED",
"ttl": 0,
"enable_label_index": true,
"user_data": {
"~create_time": "2023-05-08 17:49:08.437"
}
},
{
"id": 2,
"name": "created",
"source_label": "person",
"target_label": "software",
"frequency": "SINGLE",
"sort_keys": [],
"nullable_keys": [],
"index_labels": [
"createdByDate",
"createdByWeight"
],
"properties": [
"weight",
"date"
],
"status": "CREATED",
"ttl": 0,
"enable_label_index": true,
"user_data": {
"~create_time": "2023-05-08 17:49:08.446"
}
}
],
"indexlabels": [
{
"id": 1,
"name": "personByAge",
"base_type": "VERTEX_LABEL",
"base_value": "person",
"index_type": "RANGE_INT",
"fields": [
"age"
],
"status": "CREATED",
"user_data": {
"~create_time": "2023-05-08 17:49:05.375"
}
},
{
"id": 2,
"name": "personByCity",
"base_type": "VERTEX_LABEL",
"base_value": "person",
"index_type": "SECONDARY",
"fields": [
"city"
],
"status": "CREATED",
"user_data": {
"~create_time": "2023-05-08 17:49:06.898"
}
},
{
"id": 3,
"name": "personByAgeAndCity",
"base_type": "VERTEX_LABEL",
"base_value": "person",
"index_type": "SECONDARY",
"fields": [
"age",
"city"
],
"status": "CREATED",
"user_data": {
"~create_time": "2023-05-08 17:49:07.407"
}
},
{
"id": 4,
"name": "softwareByPrice",
"base_type": "VERTEX_LABEL",
"base_value": "software",
"index_type": "RANGE_DOUBLE",
"fields": [
"price"
],
"status": "CREATED",
"user_data": {
"~create_time": "2023-05-08 17:49:07.916"
}
},
{
"id": 5,
"name": "createdByDate",
"base_type": "EDGE_LABEL",
"base_value": "created",
"index_type": "SECONDARY",
"fields": [
"date"
],
"status": "CREATED",
"user_data": {
"~create_time": "2023-05-08 17:49:08.454"
}
},
{
"id": 6,
"name": "createdByWeight",
"base_type": "EDGE_LABEL",
"base_value": "created",
"index_type": "RANGE_DOUBLE",
"fields": [
"weight"
],
"status": "CREATED",
"user_data": {
"~create_time": "2023-05-08 17:49:08.963"
}
},
{
"id": 7,
"name": "knowsByWeight",
"base_type": "EDGE_LABEL",
"base_value": "knows",
"index_type": "RANGE_DOUBLE",
"fields": [
"weight"
],
"status": "CREATED",
"user_data": {
"~create_time": "2023-05-08 17:49:09.473"
}
}
]
}
1.3 - PropertyKey API
1.2 PropertyKey
Params Description:
- name: The name of the property type, required.
- data_type: The data type of the property type, including: bool, byte, int, long, float, double, text, blob, date, uuid. The default data type is
text(Represent astringtype) - cardinality: The cardinality of the property type, including: single, list, set. The default cardinality is
single.
Request Body Field Description:
- id: The ID value of the property type.
- properties: The properties of the property type. For properties, this field is empty.
- user_data: Setting the common information of the property type, such as setting the value range of the age property from 0 to 100. Currently, no validation is performed on this field, and it is only a reserved entry for future expansion.
1.2.1 Create a PropertyKey
Method & Url
POST http://localhost:8080/graphspaces/DEFAULT/graphs/hugegraph/schema/propertykeys
Request Body
{
"name": "age",
"data_type": "INT",
"cardinality": "SINGLE"
}
Response Status
202
Response Body
{
"property_key": {
"id": 1,
"name": "age",
"data_type": "INT",
"cardinality": "SINGLE",
"aggregate_type": "NONE",
"write_type": "OLTP",
"properties": [],
"status": "CREATED",
"user_data": {
"~create_time": "2022-05-13 13:47:23.745"
}
},
"task_id": 0
}
1.2.2 Add or Remove userdata for an existing PropertyKey
Params
- action: Indicates whether the current action is to add or remove userdata. Possible values are
append(add) andeliminate(remove).
Method & Url
PUT http://localhost:8080/graphspaces/DEFAULT/graphs/hugegraph/schema/propertykeys/age?action=append
Request Body
{
"name": "age",
"user_data": {
"min": 0,
"max": 100
}
}
Response Status
202
Response Body
{
"property_key": {
"id": 1,
"name": "age",
"data_type": "INT",
"cardinality": "SINGLE",
"aggregate_type": "NONE",
"write_type": "OLTP",
"properties": [],
"status": "CREATED",
"user_data": {
"min": 0,
"max": 100,
"~create_time": "2022-05-13 13:47:23.745"
}
},
"task_id": 0
}
1.2.3 Get all PropertyKeys
Method & Url
GET http://localhost:8080/graphspaces/DEFAULT/graphs/hugegraph/schema/propertykeys
Response Status
200
Response Body
{
"propertykeys": [
{
"id": 3,
"name": "city",
"data_type": "TEXT",
"cardinality": "SINGLE",
"properties": [],
"user_data": {}
},
{
"id": 2,
"name": "age",
"data_type": "INT",
"cardinality": "SINGLE",
"properties": [],
"user_data": {}
},
{
"id": 5,
"name": "lang",
"data_type": "TEXT",
"cardinality": "SINGLE",
"properties": [],
"user_data": {}
},
{
"id": 4,
"name": "weight",
"data_type": "DOUBLE",
"cardinality": "SINGLE",
"properties": [],
"user_data": {}
},
{
"id": 6,
"name": "date",
"data_type": "TEXT",
"cardinality": "SINGLE",
"properties": [],
"user_data": {}
},
{
"id": 1,
"name": "name",
"data_type": "TEXT",
"cardinality": "SINGLE",
"properties": [],
"user_data": {}
},
{
"id": 7,
"name": "price",
"data_type": "INT",
"cardinality": "SINGLE",
"properties": [],
"user_data": {}
}
]
}
1.2.4 Get PropertyKey according to name
Method & Url
GET http://localhost:8080/graphspaces/DEFAULT/graphs/hugegraph/schema/propertykeys/age
Where age is the name of the PropertyKey to be retrieved.
Response Status
200
Response Body
{
"id": 1,
"name": "age",
"data_type": "INT",
"cardinality": "SINGLE",
"aggregate_type": "NONE",
"write_type": "OLTP",
"properties": [],
"status": "CREATED",
"user_data": {
"min": 0,
"max": 100,
"~create_time": "2022-05-13 13:47:23.745"
}
}
1.2.5 Delete PropertyKey according to name
Method & Url
DELETE http://localhost:8080/graphspaces/DEFAULT/graphs/hugegraph/schema/propertykeys/age
Where age is the name of the PropertyKey to be deleted.
Response Status
202
Response Body
{
"task_id" : 0
}
1.4 - VertexLabel API
1.3 VertexLabel
Assuming that the PropertyKeys listed in 1.1.3 have already been created.
Params Description:
- id: The ID value of the vertex type.
- name: The name of the vertex type, required.
- id_strategy: The ID strategy for the vertex type, including primary key ID, auto-generated, custom string, custom number, custom UUID. The default strategy is primary key ID.
- properties: The property types associated with the vertex type.
- primary_keys: The primary key properties. This field must have a value when the ID strategy is PRIMARY_KEY, and must be empty for other ID strategies.
- enable_label_index: Whether to enable label indexing. It is disabled by default.
- index_names: The indexes created for the vertex type. See details in section 3.4.
- nullable_keys: Nullable properties.
- user_data: Setting the common information of the vertex type, similar to the property type.
1.3.1 Create a VertexLabel
Method & Url
POST http://localhost:8080/graphspaces/DEFAULT/graphs/hugegraph/schema/vertexlabels
Request Body
{
"name": "person",
"id_strategy": "DEFAULT",
"properties": [
"name",
"age"
],
"primary_keys": [
"name"
],
"nullable_keys": [],
"enable_label_index": true
}
Response Status
201
Response Body
{
"id": 1,
"primary_keys": [
"name"
],
"id_strategy": "PRIMARY_KEY",
"name": "person2",
"index_names": [
],
"properties": [
"name",
"age"
],
"nullable_keys": [
],
"enable_label_index": true,
"user_data": {}
}
Starting from version v0.11.2, hugegraph-server supports Time-to-Live (TTL) functionality for vertices. The TTL for vertices is set through VertexLabel. For example, if you want the vertices of type “person” to have a lifespan of one day, you need to set the TTL field to 86400000 (in milliseconds) when creating the “person” VertexLabel.
{
"name": "person",
"id_strategy": "DEFAULT",
"properties": [
"name",
"age"
],
"primary_keys": [
"name"
],
"nullable_keys": [],
"ttl": 86400000,
"enable_label_index": true
}
Additionally, if the vertex has a property called “createdTime” and you want to use it as the starting point for calculating the vertex’s lifespan, you can set the ttl_start_time field in the VertexLabel. For example, if the “person” VertexLabel has a property called “createdTime” of type Date, and you want the vertices of type “person” to live for one day starting from the creation time, the Request Body for creating the “person” VertexLabel would be as follows:
{
"name": "person",
"id_strategy": "DEFAULT",
"properties": [
"name",
"age",
"createdTime"
],
"primary_keys": [
"name"
],
"nullable_keys": [],
"ttl": 86400000,
"ttl_start_time": "createdTime",
"enable_label_index": true
}
1.3.2 Add properties or userdata to an existing VertexLabel, or remove userdata (removing properties is currently not supported)
Params
- action: Indicates whether the current action is to add or remove. Possible values are
append(add) andeliminate(remove).
Method & Url
PUT http://localhost:8080/graphspaces/DEFAULT/graphs/hugegraph/schema/vertexlabels/person?action=append
Request Body
{
"name": "person",
"properties": [
"city"
],
"nullable_keys": ["city"],
"user_data": {
"super": "animal"
}
}
Response Status
200
Response Body
{
"id": 1,
"primary_keys": [
"name"
],
"id_strategy": "PRIMARY_KEY",
"name": "person",
"index_names": [
],
"properties": [
"city",
"name",
"age"
],
"nullable_keys": [
"city"
],
"enable_label_index": true,
"user_data": {
"super": "animal"
}
}
1.3.3 Get all VertexLabels
Method & Url
GET http://localhost:8080/graphspaces/DEFAULT/graphs/hugegraph/schema/vertexlabels
Response Status
200
Response Body
{
"vertexlabels": [
{
"id": 1,
"primary_keys": [
"name"
],
"id_strategy": "PRIMARY_KEY",
"name": "person",
"index_names": [
],
"properties": [
"city",
"name",
"age"
],
"nullable_keys": [
"city"
],
"enable_label_index": true,
"user_data": {
"super": "animal"
}
},
{
"id": 2,
"primary_keys": [
"name"
],
"id_strategy": "PRIMARY_KEY",
"name": "software",
"index_names": [
],
"properties": [
"price",
"name",
"lang"
],
"nullable_keys": [
"price"
],
"enable_label_index": false,
"user_data": {}
}
]
}
1.3.4 Get VertexLabel by name
Method & Url
GET http://localhost:8080/graphspaces/DEFAULT/graphs/hugegraph/schema/vertexlabels/person
Response Status
200
Response Body
{
"id": 1,
"primary_keys": [
"name"
],
"id_strategy": "PRIMARY_KEY",
"name": "person",
"index_names": [
],
"properties": [
"city",
"name",
"age"
],
"nullable_keys": [
"city"
],
"enable_label_index": true,
"user_data": {
"super": "animal"
}
}
1.3.5 Delete VertexLabel by name
Deleting a VertexLabel will result in the removal of corresponding vertices and related index data. This operation will generate an asynchronous task.
Method & Url
DELETE http://localhost:8080/graphspaces/DEFAULT/graphs/hugegraph/schema/vertexlabels/person
Response Status
202
Response Body
{
"task_id": 1
}
Note:
You can use
GET http://localhost:8080/graphspaces/DEFAULT/graphs/hugegraph/tasks/1(where “1” is the task_id) to query the execution status of the asynchronous task. For more information, refer to the Asynchronous Task RESTful API.
1.5 - EdgeLabel API
1.4 EdgeLabel
Assuming PropertyKeys from version 1.2.3 and VertexLabels from version 1.3.3 have already been created.
Params Explanation
- name: Name of the vertex type, required.
- source_label: Name of the source vertex type, required.
- target_label: Name of the target vertex type, required.
- frequency: Whether there can be multiple edges between two points, can have values SINGLE or MULTIPLE, optional (default value: SINGLE).
- properties: Property types associated with the edge type, optional.
- sort_keys: Specifies a list of differentiating key properties when multiple associations are allowed.
- nullable_keys: Nullable properties, optional (default: nullable).
- enable_label_index: Whether to enable type indexing, disabled by default.
1.4.1 Create an EdgeLabel
Method & Url
POST http://localhost:8080/graphspaces/DEFAULT/graphs/hugegraph/schema/edgelabels
Request Body
{
"name": "created",
"source_label": "person",
"target_label": "software",
"frequency": "SINGLE",
"properties": [
"date"
],
"sort_keys": [],
"nullable_keys": [],
"enable_label_index": true
}
Response Status
201
Response Body
{
"id": 1,
"sort_keys": [
],
"source_label": "person",
"name": "created",
"index_names": [
],
"properties": [
"date"
],
"target_label": "software",
"frequency": "SINGLE",
"nullable_keys": [
],
"enable_label_index": true,
"user_data": {}
}
Starting from version 0.11.2 of hugegraph-server, the TTL (Time to Live) feature for edges is supported. The TTL for edges is set through EdgeLabel. For example, if you want the “knows” type of edge to have a lifespan of one day, you need to set the TTL field to 86400000 when creating the “knows” EdgeLabel, where the unit is milliseconds.
{
"id": 1,
"sort_keys": [
],
"source_label": "person",
"name": "knows",
"index_names": [
],
"properties": [
"date",
"createdTime"
],
"target_label": "person",
"frequency": "SINGLE",
"nullable_keys": [
],
"enable_label_index": true,
"ttl": 86400000,
"user_data": {}
}
Additionally, when the edge has a property called “createdTime” and you want to use the “createdTime” property as the starting point for calculating the edge’s lifespan, you can set the ttl_start_time field in the EdgeLabel. For example, if the knows EdgeLabel has a property called “createdTime” which is of type Date, and you want the “knows” type of edge to live for one day from the time of creation, the Request Body for creating the knows EdgeLabel would be as follows:
{
"id": 1,
"sort_keys": [
],
"source_label": "person",
"name": "knows",
"index_names": [
],
"properties": [
"date",
"createdTime"
],
"target_label": "person",
"frequency": "SINGLE",
"nullable_keys": [
],
"enable_label_index": true,
"ttl": 86400000,
"ttl_start_time": "createdTime",
"user_data": {}
}
1.4.2 Add properties or userdata to an existing EdgeLabel, or remove userdata (removing properties is currently not supported)
Params
- action: Indicates whether the current action is to add or remove, with values
append(add) andeliminate(remove).
Method & Url
PUT http://localhost:8080/graphspaces/DEFAULT/graphs/hugegraph/schema/edgelabels/created?action=append
Request Body
{
"name": "created",
"properties": [
"weight"
],
"nullable_keys": [
"weight"
]
}
Response Status
200
Response Body
{
"id": 2,
"sort_keys": [
],
"source_label": "person",
"name": "created",
"index_names": [
],
"properties": [
"date",
"weight"
],
"target_label": "software",
"frequency": "SINGLE",
"nullable_keys": [
"weight"
],
"enable_label_index": true,
"user_data": {}
}
1.4.3 Get all EdgeLabels
Method & Url
GET http://localhost:8080/graphspaces/DEFAULT/graphs/hugegraph/schema/edgelabels
Response Status
200
Response Body
{
"edgelabels": [
{
"id": 1,
"sort_keys": [
],
"source_label": "person",
"name": "created",
"index_names": [
],
"properties": [
"date",
"weight"
],
"target_label": "software",
"frequency": "SINGLE",
"nullable_keys": [
"weight"
],
"enable_label_index": true,
"user_data": {}
},
{
"id": 2,
"sort_keys": [
],
"source_label": "person",
"name": "knows",
"index_names": [
],
"properties": [
"date",
"weight"
],
"target_label": "person",
"frequency": "SINGLE",
"nullable_keys": [
],
"enable_label_index": false,
"user_data": {}
}
]
}
1.4.4 Get EdgeLabel by name
Method & Url
GET http://localhost:8080/graphspaces/DEFAULT/graphs/hugegraph/schema/edgelabels/created
Response Status
200
Response Body
{
"id": 1,
"sort_keys": [
],
"source_label": "person",
"name": "created",
"index_names": [
],
"properties": [
"date",
"city",
"weight"
],
"target_label": "software",
"frequency": "SINGLE",
"nullable_keys": [
"city",
"weight"
],
"enable_label_index": true,
"user_data": {}
}
1.4.5 Delete EdgeLabel by name
Deleting an EdgeLabel will result in the deletion of corresponding edges and related index data. This operation will generate an asynchronous task.
Method & Url
DELETE http://localhost:8080/graphspaces/DEFAULT/graphs/hugegraph/schema/edgelabels/created
Response Status
202
Response Body
{
"task_id": 1
}
Note:
You can query the execution status of an asynchronous task by using
GET http://localhost:8080/graphspaces/DEFAULT/graphs/hugegraph/tasks/1(where “1” is the task_id). For more information, refer to the Asynchronous Task RESTful API.
1.6 - IndexLabel API
1.5 IndexLabel
Assuming PropertyKeys from version 1.1.3, VertexLabels from version 1.2.3, and EdgeLabels from version 1.3.3 have already been created.
1.5.1 Create an IndexLabel
Method & Url
POST http://localhost:8080/graphspaces/DEFAULT/graphs/hugegraph/schema/indexlabels
Request Body
{
"name": "personByCity",
"base_type": "VERTEX_LABEL",
"base_value": "person",
"index_type": "SECONDARY",
"fields": [
"city"
]
}
Response Status
202
Response Body
{
"index_label": {
"id": 1,
"base_type": "VERTEX_LABEL",
"base_value": "person",
"name": "personByCity",
"fields": [
"city"
],
"index_type": "SECONDARY"
},
"task_id": 2
}
1.5.2 Get all IndexLabels
Method & Url
GET http://localhost:8080/graphspaces/DEFAULT/graphs/hugegraph/schema/indexlabels
Response Status
200
Response Body
{
"indexlabels": [
{
"id": 3,
"base_type": "VERTEX_LABEL",
"base_value": "software",
"name": "softwareByPrice",
"fields": [
"price"
],
"index_type": "RANGE"
},
{
"id": 4,
"base_type": "EDGE_LABEL",
"base_value": "created",
"name": "createdByDate",
"fields": [
"date"
],
"index_type": "SECONDARY"
},
{
"id": 1,
"base_type": "VERTEX_LABEL",
"base_value": "person",
"name": "personByCity",
"fields": [
"city"
],
"index_type": "SECONDARY"
},
{
"id": 3,
"base_type": "VERTEX_LABEL",
"base_value": "person",
"name": "personByAgeAndCity",
"fields": [
"age",
"city"
],
"index_type": "SECONDARY"
}
]
}
1.5.3 Get IndexLabel by name
Method & Url
GET http://localhost:8080/graphspaces/DEFAULT/graphs/hugegraph/schema/indexlabels/personByCity
Response Status
200
Response Body
{
"id": 1,
"base_type": "VERTEX_LABEL",
"base_value": "person",
"name": "personByCity",
"fields": [
"city"
],
"index_type": "SECONDARY"
}
1.5.4 Delete IndexLabel by name
Deleting an IndexLabel will result in the deletion of related index data. This operation will generate an asynchronous task.
Method & Url
DELETE http://localhost:8080/graphspaces/DEFAULT/graphs/hugegraph/schema/indexlabels/personByCity
Response Status
202
Response Body
{
"task_id": 1
}
Note:
You can query the execution status of an asynchronous task by using
GET http://localhost:8080/graphspaces/DEFAULT/graphs/hugegraph/tasks/1(where “1” is the task_id). For more information, refer to the Asynchronous Task RESTful API.
1.7 - Rebuild API
1.6 Rebuild
1.6.1 Rebuild IndexLabel
Method & Url
PUT http://localhost:8080/graphspaces/DEFAULT/graphs/hugegraph/jobs/rebuild/indexlabels/personByCity
Response Status
202
Response Body
{
"task_id": 1
}
Note:
You can get the asynchronous job status by
GET http://localhost:8080/graphspaces/DEFAULT/graphs/hugegraph/tasks/${task_id}(the task_id here should be 1). See More AsyncJob RESTfull API
1.6.2 Rebulid all Indexs of VertexLabel
Method & Url
PUT http://localhost:8080/graphspaces/DEFAULT/graphs/hugegraph/jobs/rebuild/vertexlabels/person
Response Status
202
Response Body
{
"task_id": 2
}
Note:
You can get the asynchronous job status by
GET http://localhost:8080/graphspaces/DEFAULT/graphs/hugegraph/tasks/${task_id}(the task_id here should be 2). See More AsyncJob RESTfull API
1.6.3 Rebulid all Indexs of EdgeLabel
Method & Url
PUT http://localhost:8080/graphspaces/DEFAULT/graphs/hugegraph/jobs/rebuild/edgelabels/created
Response Status
202
Response Body
{
"task_id": 3
}
Note:
You can get the asynchronous job status by
GET http://localhost:8080/graphspaces/DEFAULT/graphs/hugegraph/tasks/${task_id}(the task_id here should be 3). See More AsyncJob RESTfull API
1.8 - Vertex API
2.1 Vertex
In vertex types, the Id strategy determines the type of the vertex Id, with the corresponding relationships as follows:
| Id_Strategy | id type |
|---|---|
| AUTOMATIC | number |
| PRIMARY_KEY | string |
| CUSTOMIZE_STRING | string |
| CUSTOMIZE_NUMBER | number |
| CUSTOMIZE_UUID | uuid |
For the GET/PUT/DELETE API of a vertex, the id part in the URL should be passed as the id value with type information. This type information is indicated by whether the JSON string is enclosed in quotes, meaning:
- When the id type is
number, the id in the URL is without quotes, for example:xxx/vertices/123456. - When the id type is
string, the id in the URL is enclosed in quotes, for example:xxx/vertices/"123456".
The next example requires first creating the graph schema from the following groovy script
schema.propertyKey("name").asText().ifNotExist().create();
schema.propertyKey("age").asInt().ifNotExist().create();
schema.propertyKey("city").asText().ifNotExist().create();
schema.propertyKey("weight").asDouble().ifNotExist().create();
schema.propertyKey("lang").asText().ifNotExist().create();
schema.propertyKey("price").asDouble().ifNotExist().create();
schema.propertyKey("hobby").asText().valueList().ifNotExist().create();
schema.vertexLabel("person").properties("name", "age", "city", "weight", "hobby").primaryKeys("name").nullableKeys("age", "city", "weight", "hobby").ifNotExist().create();
schema.vertexLabel("software").properties("name", "lang", "price").primaryKeys("name").nullableKeys("lang", "price").ifNotExist().create();
schema.indexLabel("personByAge").onV("person").by("age").range().ifNotExist().create();
2.1.1 Create a vertex
Method & Url
POST http://localhost:8080/graphspaces/DEFAULT/graphs/hugegraph/graph/vertices
Request Body
{
"label": "person",
"properties": {
"name": "marko",
"age": 29
}
}
Response Status
201
Response Body
{
"id": "1:marko",
"label": "person",
"type": "vertex",
"properties": {
"name": "marko",
"age": 29
}
}
2.1.2 Create multiple vertices
Method & Url
POST http://localhost:8080/graphspaces/DEFAULT/graphs/hugegraph/graph/vertices/batch
Request Body
[
{
"label": "person",
"properties": {
"name": "marko",
"age": 29
}
},
{
"label": "software",
"properties": {
"name": "ripple",
"lang": "java",
"price": 199
}
}
]
Response Status
201
Response Body
[
"1:marko",
"2:ripple"
]
2.1.3 Update vertex properties
Method & Url
PUT http://127.0.0.1:8080/graphspaces/DEFAULT/graphs/hugegraph/graph/vertices/"1:marko"?action=append
Request Body
{
"label": "person",
"properties": {
"age": 30,
"city": "Beijing"
}
}
Note: There are three categories for property values: single, set, and list. If it is single, it means adding or updating the property value. If it is set or list, it means appending the property value.
Response Status
200
Response Body
{
"id": "1:marko",
"label": "person",
"type": "vertex",
"properties": {
"name": "marko",
"age": 30,
"city": "Beijing"
}
}
2.1.4 Batch Update Vertex Properties
Function Description
Batch update properties of vertices and support various update strategies, including:
- SUM: Numeric accumulation
- BIGGER: Take the larger value between two numbers/dates
- SMALLER: Take the smaller value between two numbers/dates
- UNION: Take the union of set properties
- INTERSECTION: Take the intersection of set properties
- APPEND: Append elements to list properties
- ELIMINATE: Remove elements from list/set properties
- OVERRIDE: Override existing properties, if the new property is null, the old property is still used
Assuming the original vertex and properties are:
{
"vertices": [
{
"id": "2:lop",
"label": "software",
"type": "vertex",
"properties": {
"name": "lop",
"lang": "java",
"price": 328
}
},
{
"id": "1:josh",
"label": "person",
"type": "vertex",
"properties": {
"name": "josh",
"age": 32,
"city": "Beijing",
"weight": 0.1,
"hobby": [
"reading",
"football"
]
}
}
]
}
Add vertices with the following command:
curl -H "Content-Type: application/json" -d '[{"label":"person","properties":{"name":"josh","age":32,"city":"Beijing","weight":0.1,"hobby":["reading","football"]}},{"label":"software","properties":{"name":"lop","lang":"java","price":328}}]' http://127.0.0.1:8080/graphspaces/DEFAULT/graphs/hugegraph/graph/vertices/batch
Method & Url
PUT http://127.0.0.1:8080/graphspaces/DEFAULT/graphs/hugegraph/graph/vertices/batch
Request Body
{
"vertices": [
{
"label": "software",
"type": "vertex",
"properties": {
"name": "lop",
"lang": "c++",
"price": 299
}
},
{
"label": "person",
"type": "vertex",
"properties": {
"name": "josh",
"city": "Shanghai",
"weight": 0.2,
"hobby": [
"swimming"
]
}
}
],
"update_strategies": {
"price": "BIGGER",
"age": "OVERRIDE",
"city": "OVERRIDE",
"weight": "SUM",
"hobby": "UNION"
},
"create_if_not_exist": true
}
Response Status
200
Response Body
{
"vertices": [
{
"id": "2:lop",
"label": "software",
"type": "vertex",
"properties": {
"name": "lop",
"lang": "c++",
"price": 328
}
},
{
"id": "1:josh",
"label": "person",
"type": "vertex",
"properties": {
"name": "josh",
"age": 32,
"city": "Shanghai",
"weight": 0.3,
"hobby": [
"reading",
"football",
"swimming"
]
}
}
]
}
Result Analysis:
- The lang property does not specify an update strategy and is directly overwritten by the new value, regardless of whether the new value is null.
- The price property specifies the BIGGER update strategy. The old property value is 328, and the new property value is 299, so the old property value of 328 is retained.
- The age property specifies the OVERRIDE update strategy, but the new property value does not include age, which is equivalent to age being null. Therefore, the original property value of 32 is still retained.
- The city property also specifies the OVERRIDE update strategy, and the new property value is not null, so it overrides the old value.
- The weight property specifies the SUM update strategy. The old property value is 0.1, and the new property value is 0.2. The final value is 0.3.
- The hobby property (cardinality is Set) specifies the UNION update strategy, so the new value is taken as the union with the old value.
The usage of other update strategies can be inferred in a similar manner and will not be further elaborated.
2.1.5 Delete Vertex Properties
Method & Url
PUT http://127.0.0.1:8080/graphspaces/DEFAULT/graphs/hugegraph/graph/vertices/"1:marko"?action=eliminate
Request Body
{
"label": "person",
"properties": {
"city": "Beijing"
}
}
Note: Here, the properties (keys and all values) will be directly deleted, regardless of whether the property values are single, set, or list.
Response Status
200
Response Body
{
"id": "1:marko",
"label": "person",
"type": "vertex",
"properties": {
"name": "marko",
"age": 30
}
}
2.1.6 Get Vertices that Meet the Criteria
Params
- label: Vertex type
- properties: Property key-value pairs (precondition: indexes are created for property queries)
- limit: Maximum number of results
- page: Page number
All of the above parameters are optional. If the page parameter is provided, the limit parameter must also be provided, and no other parameters are allowed. label, properties, and limit can be combined in any way.
Property key-value pairs consist of the property name and value in JSON format. Multiple property key-value pairs are allowed as query conditions. The property value supports exact matching, range matching, and fuzzy matching. For exact matching, use the format properties={"age":29}, for range matching, use the format properties={"age":"P.gt(29)"}, and for fuzzy matching, use the format properties={"city": "P.textcontains("ChengDu China")}. The following expressions are supported for range matching:
| Expression | Explanation |
|---|---|
| P.eq(number) | Vertices with property value equal to number |
| P.neq(number) | Vertices with property value not equal to number |
| P.lt(number) | Vertices with property value less than number |
| P.lte(number) | Vertices with property value less than or equal to number |
| P.gt(number) | Vertices with property value greater than number |
| P.gte(number) | Vertices with property value greater than or equal to number |
| P.between(number1,number2) | Vertices with property value greater than or equal to number1 and less than number2 |
| P.inside(number1,number2) | Vertices with property value greater than number1 and less than number2 |
| P.outside(number1,number2) | Vertices with property value less than number1 and greater than number2 |
| P.within(value1,value2,value3,…) | Vertices with property value equal to any of the given values |
Query all vertices with age 29 and label person
Method & Url
GET http://localhost:8080/graphspaces/DEFAULT/graphs/hugegraph/graph/vertices?label=person&properties={"age":29}&limit=1
Response Status
200
Response Body
{
"vertices": [
{
"id": "1:marko",
"label": "person",
"type": "vertex",
"properties": {
"name": "marko",
"age": 30
}
}
]
}
Paginate through all vertices, retrieve the first page (page without parameter value), limited to 3 records
Add vertices with the following command:
curl -H "Content-Type: application/json" -d '[{"label":"person","properties":{"name":"peter","age":29,"city":"Shanghai"}},{"label":"person","properties":{"name":"vadas","age":27,"city":"Hongkong"}}]' http://localhost:8080/graphspaces/DEFAULT/graphs/hugegraph/graph/vertices/batch
Method & Url
GET http://localhost:8080/graphspaces/DEFAULT/graphs/hugegraph/graph/vertices?page&limit=3
Response Status
200
Response Body
{
"vertices": [
{
"id": "2:lop",
"label": "software",
"type": "vertex",
"properties": {
"name": "lop",
"lang": "c++",
"price": 328
}
},
{
"id": "1:josh",
"label": "person",
"type": "vertex",
"properties": {
"name": "josh",
"age": 32,
"city": "Shanghai",
"weight": 0.3,
"hobby": [
"reading",
"football",
"swimming"
]
}
},
{
"id": "1:marko",
"label": "person",
"type": "vertex",
"properties": {
"name": "marko",
"age": 30
}
}
],
"page": "CIYxOnBldGVyAAAAAAAAAAM="
}
The returned body contains information about the page number of the next page, "page": "CIYxOnBldGVyAAAAAAAAAAM". When querying the next page, assign this value to the page parameter.
Paginate and retrieve all vertices, including the next page (passing the page value returned from the previous page), limited to 3 items.
Method & Url
GET http://localhost:8080/graphspaces/DEFAULT/graphs/hugegraph/graph/vertices?page=CIYxOnBldGVyAAAAAAAAAAM=&limit=3
Response Status
200
Response Body
{
"vertices": [
{
"id": "1:peter",
"label": "person",
"type": "vertex",
"properties": {
"name": "peter",
"age": 29,
"city": "Shanghai"
}
},
{
"id": "1:vadas",
"label": "person",
"type": "vertex",
"properties": {
"name": "vadas",
"age": 27,
"city": "Hongkong"
}
},
{
"id": "2:ripple",
"label": "software",
"type": "vertex",
"properties": {
"name": "ripple",
"lang": "java",
"price": 199
}
}
],
"page": null
}
At this point, "page": null indicates that there are no more pages available. (Note: When using Cassandra as the backend for performance reasons, if the returned page happens to be the last page, the page value may not be empty. When requesting the next page using that page value, it will return empty data and page = null. The same applies to other similar situations.)
2.1.7 Retrieve Vertex by ID
Method & Url
GET http://localhost:8080/graphspaces/DEFAULT/graphs/hugegraph/graph/vertices/"1:marko"
Response Status
200
Response Body
{
"id": "1:marko",
"label": "person",
"type": "vertex",
"properties": {
"name": "marko",
"age": 30
}
}
2.1.8 Delete Vertex by ID
Params
- label: Vertex type, optional parameter
Delete the vertex based on ID only.
Method & Url
DELETE http://localhost:8080/graphspaces/DEFAULT/graphs/hugegraph/graph/vertices/"1:marko"
Response Status
204
Delete Vertex by Label+ID
When deleting a vertex by specifying both the Label parameter and the ID, it generally offers better performance compared to deleting by ID alone.
Method & Url
DELETE http://localhost:8080/graphspaces/DEFAULT/graphs/hugegraph/graph/vertices/"1:marko"?label=person
Response Status
204
1.9 - Edge API
2.2 Edge
The modification of the vertex ID format also affects the ID of the edge, as well as the formats of the source vertex and target vertex IDs.
The EdgeId is formed by concatenating src-vertex-id + direction + label + sort-values + tgt-vertex-id, but the vertex ID types are not distinguished by quotation marks here. Instead, they are distinguished by prefixes:
- When the ID type is number, the vertex ID in the EdgeId has a prefix
L, like “L123456>1»L987654”. - When the ID type is string, the vertex ID in the EdgeId has a prefix
S, like “S1:peter>1»S2:lop”.
The following example requires creating a graph schema based on the following groovy script:
import org.apache.hugegraph.HugeFactory
import org.apache.tinkerpop.gremlin.structure.T
conf = "conf/graphs/hugegraph.properties"
graph = HugeFactory.open(conf)
schema = graph.schema()
schema.propertyKey("name").asText().ifNotExist().create()
schema.propertyKey("age").asInt().ifNotExist().create()
schema.propertyKey("city").asText().ifNotExist().create()
schema.propertyKey("weight").asDouble().ifNotExist().create()
schema.propertyKey("lang").asText().ifNotExist().create()
schema.propertyKey("date").asText().ifNotExist().create()
schema.propertyKey("price").asInt().ifNotExist().create()
schema.vertexLabel("person").properties("name", "age", "city").primaryKeys("name").ifNotExist().create()
schema.vertexLabel("software").properties("name", "lang", "price").primaryKeys("name").ifNotExist().create()
schema.indexLabel("personByCity").onV("person").by("city").secondary().ifNotExist().create()
schema.indexLabel("personByAgeAndCity").onV("person").by("age", "city").secondary().ifNotExist().create()
schema.indexLabel("softwareByPrice").onV("software").by("price").range().ifNotExist().create()
schema.edgeLabel("knows").sourceLabel("person").targetLabel("person").properties("date", "weight").ifNotExist().create()
schema.edgeLabel("created").sourceLabel("person").targetLabel("software").properties("date", "weight").ifNotExist().create()
schema.indexLabel("createdByDate").onE("created").by("date").secondary().ifNotExist().create()
schema.indexLabel("createdByWeight").onE("created").by("weight").range().ifNotExist().create()
schema.indexLabel("knowsByWeight").onE("knows").by("weight").range().ifNotExist().create()
marko = graph.addVertex(T.label, "person", "name", "marko", "age", 29, "city", "Beijing")
vadas = graph.addVertex(T.label, "person", "name", "vadas", "age", 27, "city", "Hongkong")
lop = graph.addVertex(T.label, "software", "name", "lop", "lang", "java", "price", 328)
josh = graph.addVertex(T.label, "person", "name", "josh", "age", 32, "city", "Beijing")
ripple = graph.addVertex(T.label, "software", "name", "ripple", "lang", "java", "price", 199)
peter = graph.addVertex(T.label, "person", "name", "peter", "age", 35, "city", "Shanghai")
graph.tx().commit()
g = graph.traversal()
2.2.1 Creating an Edge
Params
Path Parameter Description:
- graph: The graph to operate on
Request Body Description:
- label: The edge type name (required)
- outV: The source vertex id (required)
- inV: The target vertex id (required)
- outVLabel: The source vertex type (required)
- inVLabel: The target vertex type (required)
- properties: The properties associated with the edge. The internal structure of the object is as follows:
- name: The property name
- value: The property value
Method & Url
POST http://localhost:8080/graphspaces/DEFAULT/graphs/hugegraph/graph/edges
Request Body
{
"label": "created",
"outV": "1:marko",
"inV": "2:lop",
"outVLabel": "person",
"inVLabel": "software",
"properties": {
"date": "20171210",
"weight": 0.4
}
}
Response Status
201
Response Body
{
"id": "S1:marko>2>>S2:lop",
"label": "created",
"type": "edge",
"outV": "1:marko",
"outVLabel": "person",
"inV": "2:lop",
"inVLabel": "software",
"properties": {
"weight": 0.4,
"date": "20171210"
}
}
2.2.2 Creating Multiple Edges
Params
Path Parameter Description:
- graph: The graph to operate on
Request Parameter Description:
- check_vertex: Whether to check the existence of vertices (true | false). When set to true, an error will be thrown if the source or target vertices of the edge to be inserted do not exist. Default is true.
Request Body Description:
- List of edge information
Method & Url
POST http://localhost:8080/graphspaces/DEFAULT/graphs/hugegraph/graph/edges/batch
Request Body
[
{
"label": "knows",
"outV": "1:marko",
"inV": "1:vadas",
"outVLabel": "person",
"inVLabel": "person",
"properties": {
"date": "20160110",
"weight": 0.5
}
},
{
"label": "knows",
"outV": "1:marko",
"inV": "1:josh",
"outVLabel": "person",
"inVLabel": "person",
"properties": {
"date": "20130220",
"weight": 1.0
}
}
]
Response Status
201
Response Body
[
"S1:marko>1>>S1:vadas",
"S1:marko>1>>S1:josh"
]
2.2.3 Updating Edge Properties
Params
Path Parameter Description:
- graph: The graph to operate on
- id: The ID of the edge to be operated on
Request Parameter Description:
- action: The append action
Request Body Description:
- Edge information
Method & Url
PUT http://localhost:8080/graphspaces/DEFAULT/graphs/hugegraph/graph/edges/S1:marko>2>>S2:lop?action=append
Request Body
{
"properties": {
"weight": 1.0
}
}
NOTE: There are three categories of property values: single, set, and list. If it is single, it means adding or updating the property value. If it is set or list, it means appending the property value.
Response Status
200
Response Body
{
"id": "S1:marko>2>>S2:lop",
"label": "created",
"type": "edge",
"outV": "1:marko",
"outVLabel": "person",
"inV": "2:lop",
"inVLabel": "software",
"properties": {
"weight": 1.0,
"date": "20171210"
}
}
2.2.4 Batch Updating Edge Properties
Params
Path Parameter Description:
- graph: The graph to operate on
Request Body Description:
- edges: List of edge information
- update_strategies: For each property, you can set its update strategy individually, including:
- SUM: Only supports number type
- BIGGER/SMALLER: Only supports date/number type
- UNION/INTERSECTION: Only supports set type
- APPEND/ELIMINATE: Only supports collection type
- OVERRIDE
- check_vertex: Whether to check the existence of vertices (true | false). When set to true, an error will be thrown if the source or target vertices of the edge to be inserted do not exist. Default is true.
- create_if_not_exist: Currently only supports setting to true
Method & Url
PUT http://127.0.0.1:8080/graphspaces/DEFAULT/graphs/hugegraph/graph/edges/batch
Request Body
{
"edges": [
{
"label": "knows",
"outV": "1:marko",
"inV": "1:vadas",
"outVLabel": "person",
"inVLabel": "person",
"properties": {
"date": "20160111",
"weight": 1.0
}
},
{
"label": "knows",
"outV": "1:marko",
"inV": "1:josh",
"outVLabel": "person",
"inVLabel": "person",
"properties": {
"date": "20130221",
"weight": 0.5
}
}
],
"update_strategies": {
"weight": "SUM",
"date": "OVERRIDE"
},
"check_vertex": false,
"create_if_not_exist": true
}
Response Status
200
Response Body
{
"edges": [
{
"id": "S1:marko>1>>S1:vadas",
"label": "knows",
"type": "edge",
"outV": "1:marko",
"outVLabel": "person",
"inV": "1:vadas",
"inVLabel": "person",
"properties": {
"weight": 1.5,
"date": "20160111"
}
},
{
"id": "S1:marko>1>>S1:josh",
"label": "knows",
"type": "edge",
"outV": "1:marko",
"outVLabel": "person",
"inV": "1:josh",
"inVLabel": "person",
"properties": {
"weight": 1.5,
"date": "20130221"
}
}
]
}
2.2.5 Deleting Edge Properties
Params
Path Parameter Description:
- graph: The graph to operate on
- id: The ID of the edge to be operated on
Request Parameter Description:
- action: The eliminate action
Request Body Description:
- Edge information
Method & Url
PUT http://localhost:8080/graphspaces/DEFAULT/graphs/hugegraph/graph/edges/S1:marko>2>>S2:lop?action=eliminate
Request Body
{
"properties": {
"weight": 1.0
}
}
NOTE: This will directly delete the properties (removing the key and all values), regardless of whether the property values are single, set, or list.
Response Status
400
Response Body
It is not possible to delete an attribute that is not set as nullable.
{
"exception": "class java.lang.IllegalArgumentException",
"message": "Can't remove non-null edge property 'p[weight->1.0]'",
"cause": ""
}
2.2.6 Fetching Edges that Match the Criteria
Params
Path Parameter:
- graph: The graph to operate on
Request Parameters:
- vertex_id: Vertex ID
- direction: Edge direction (OUT | IN | BOTH), default is BOTH
- label: Edge label
- properties: Key-value pairs of properties (requires pre-built indexes for property queries)
- keep_start_p: Default is false. When set to true, the range matching input expression will not be automatically escaped. For example,
properties={"age":"P.gt(0.8)"}will be interpreted as an exact match, i.e., the age property is equal to “P.gt(0.8)” - offset: Offset, default is 0
- limit: Number of queries, default is 100
- page: Page number
Key-value pairs of properties consist of the property name and value in JSON format. Multiple key-value pairs are allowed as query conditions. Property values support exact matching and range matching. For exact matching, it is in the form properties={"weight":0.8}. For range matching, it is in the form properties={"age":"P.gt(0.8)"}. The expressions supported by range matching are as follows:
| Expression | Description |
|---|---|
| P.eq(number) | Edges with property value equal to number |
| P.neq(number) | Edges with property value not equal to number |
| P.lt(number) | Edges with property value less than number |
| P.lte(number) | Edges with property value less than or equal to number |
| P.gt(number) | Edges with property value greater than number |
| P.gte(number) | Edges with property value greater than or equal to number |
| P.between(number1,number2) | Edges with property value greater than or equal to number1 and less than number2 |
| P.inside(number1,number2) | Edges with property value greater than number1 and less than number2 |
| P.outside(number1,number2) | Edges with property value less than number1 and greater than number2 |
| P.within(value1,value2,value3,…) | Edges with property value equal to any of the given values |
| P.textcontains(value) | Edges with property value containing the given value (string type) |
| P.contains(value) | Edges with property value containing the given value (collection type) |
Edges connected to the vertex person:marko(vertex_id=“1:marko”) with label knows and date property equal to “20160111”
Method & Url
GET http://127.0.0.1:8080/graphspaces/DEFAULT/graphs/hugegraph/graph/edges?vertex_id="1:marko"&label=knows&properties={"date":"P.within(\"20160111\")"}
Response Status
200
Response Body
{
"edges": [
{
"id": "S1:marko>1>>S1:vadas",
"label": "knows",
"type": "edge",
"outV": "1:marko",
"outVLabel": "person",
"inV": "1:vadas",
"inVLabel": "person",
"properties": {
"weight": 1.5,
"date": "20160111"
}
}
]
}
Paginate and retrieve all edges, get the first page (page without parameter value), limit to 2 entries
Method & Url
GET http://127.0.0.1:8080/graphspaces/DEFAULT/graphs/hugegraph/graph/edges?page&limit=2
Response Status
200
Response Body
{
"edges": [
{
"id": "S1:marko>1>>S1:josh",
"label": "knows",
"type": "edge",
"outV": "1:marko",
"outVLabel": "person",
"inV": "1:josh",
"inVLabel": "person",
"properties": {
"weight": 1.5,
"date": "20130221"
}
},
{
"id": "S1:marko>1>>S1:vadas",
"label": "knows",
"type": "edge",
"outV": "1:marko",
"outVLabel": "person",
"inV": "1:vadas",
"inVLabel": "person",
"properties": {
"weight": 1.5,
"date": "20160111"
}
}
],
"page": "EoYxOm1hcmtvgggCAIQyOmxvcAAAAAAAAAAC"
}
The returned body contains the page number information for the next page, "page": "EoYxOm1hcmtvgggCAIQyOmxvcAAAAAAAAAAC". When querying the next page, assign this value to the page parameter.
Paginate and retrieve all edges, get the next page (include the page value returned from the previous page), limit to 2 entries
Method & Url
GET http://127.0.0.1:8080/graphspaces/DEFAULT/graphs/hugegraph/graph/edges?page=EoYxOm1hcmtvgggCAIQyOmxvcAAAAAAAAAAC&limit=2
Response Status
200
Response Body
{
"edges": [
{
"id": "S1:marko>2>>S2:lop",
"label": "created",
"type": "edge",
"outV": "1:marko",
"outVLabel": "person",
"inV": "2:lop",
"inVLabel": "software",
"properties": {
"weight": 1.0,
"date": "20171210"
}
}
],
"page": null
}
When "page": null is returned, it indicates that there are no more pages available.
NOTE: When the backend is Cassandra, for performance considerations, if the returned page happens to be the last page, the
pagevalue may not be empty. When requesting the next page data using thatpagevalue, it will returnempty dataandpage = null. Similar situations apply for other cases.
2.2.7 Fetching Edge by ID
Params
Path parameter description:
- graph: The graph to be operated on.
- id: The ID of the edge to be operated on.
Method & Url
GET http://localhost:8080/graphspaces/DEFAULT/graphs/hugegraph/graph/edges/S1:marko>2>>S2:lop
Response Status
200
Response Body
{
"id": "S1:marko>2>>S2:lop",
"label": "created",
"type": "edge",
"outV": "1:marko",
"outVLabel": "person",
"inV": "2:lop",
"inVLabel": "software",
"properties": {
"weight": 1.0,
"date": "20171210"
}
}
2.2.8 Deleting Edge by ID
Params
Path parameter description:
- graph: The graph to be operated on.
- id: The ID of the edge to be operated on.
Request parameter description:
- label: The label of the edge.
Deleting Edge by ID only
Method & Url
DELETE http://localhost:8080/graphspaces/DEFAULT/graphs/hugegraph/graph/edges/S1:marko>2>>S2:lop
Response Status
204
Deleting Edge by Label + ID
In general, specifying the Label parameter along with the ID to delete an edge will provide better performance compared to deleting by ID only.
Method & Url
DELETE http://localhost:8080/graphspaces/DEFAULT/graphs/hugegraph/graph/edges/S1:marko>1>>S1:vadas?label=knows
Response Status
204
1.10 - Traverser API
3.1 Overview of Traverser API
HugeGraphServer provides a RESTful API interface for the HugeGraph graph database. In addition to the basic CRUD operations for vertices and edges, it also offers several traversal methods, which we refer to as the traverser API. These traversal methods implement various complex graph algorithms, making it convenient for users to analyze and explore the graph.
The Traverser API supported by HugeGraph includes:
- K-out API: It finds neighbors that are exactly N steps away from a given starting vertex. There are two versions:
- The basic version uses the GET method to find neighbors that are exactly N steps away from a given starting vertex.
- The advanced version uses the POST method to find neighbors that are exactly N steps away from a given starting vertex. The advanced version differs from the basic version in the following ways:
- Supports counting the number of neighbors only
- Supports filtering by edge and vertex properties
- Supports returning the shortest path to reach the neighbor
- K-neighbor API: It finds all neighbors that are within N steps of a given starting vertex. There are two versions:
- The basic version uses the GET method to find all neighbors that are within N steps of a given starting vertex.
- The advanced version uses the POST method to find all neighbors that are within N steps of a given starting vertex. The advanced version differs from the basic version in the following ways:
- Supports counting the number of neighbors only
- Supports filtering by edge and vertex properties
- Supports returning the shortest path to reach the neighbor
- Same Neighbors: It queries the common neighbors of two vertices.
- Jaccard Similarity API: It calculates the Jaccard similarity, which includes two types:
- One type uses the GET method to calculate the similarity (intersection over union) of neighbors between two vertices.
- The other type uses the POST method to find the top N vertices with the highest Jaccard similarity to a given starting vertex in the entire graph.
- Shortest Path API: It finds the shortest path between two vertices.
- All Shortest Paths: It finds all shortest paths between two vertices.
- Weighted Shortest Path: It finds the shortest weighted path from a starting vertex to a target vertex.
- Single Source Shortest Path: It finds the weighted shortest path from a single source vertex to all other vertices.
- Multi Node Shortest Path: It finds the shortest path between every pair of specified vertices.
- Paths API: It finds all paths between two vertices. There are two versions:
- The basic version uses the GET method to find all paths between a given starting vertex and an ending vertex.
- The advanced version uses the POST method to find all paths that meet certain conditions between a set of starting vertices and a set of ending vertices.
3.2 Detailed Explanation of Traverser API
In the following, we provide a detailed explanation of the Traverser API:
- Customized Paths API: It traverses all paths that pass through a batch of vertices according to a specific pattern.
- Template Path API: It specifies a starting point, an ending point, and the path information between them to find matching paths.
- Crosspoints API: It finds the intersection (common ancestors or common descendants) between two vertices.
- Customized Crosspoints API: It traverses multiple patterns starting from a batch of vertices and finds the intersections with the vertices reached in the final step.
- Rings API: It finds the cyclic paths that can be reached from a starting vertex.
- Rays API: It finds the paths from a starting vertex that reach the boundaries (i.e., paths without cycles).
- Fusiform Similarity API: It finds the fusiform similar vertices to a given vertex.
- Vertices API:
- Batch querying vertices by ID.
- Getting the partitions of vertices.
- Querying vertices by partition.
- Edges API:
- Batch querying edges by ID.
- Getting the partitions of edges.
- Querying edges by partition.
3.2 Detailed Explanation of Traverser API
The usage examples provided in this section are based on the graph presented on the TinkerPop official website:
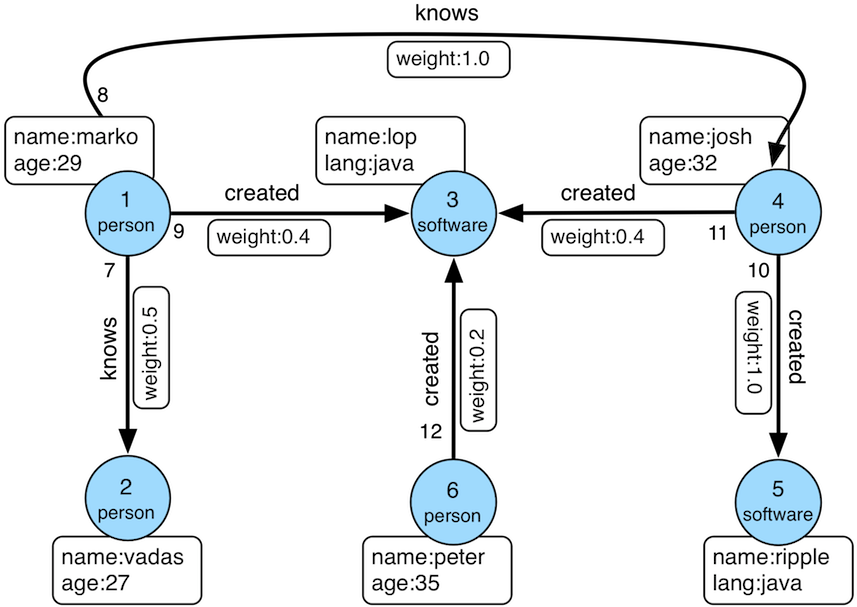
The data import program is as follows:
public class Loader {
public static void main(String[] args) {
HugeClient client = new HugeClient("http://127.0.0.1:8080", "hugegraph");
SchemaManager schema = client.schema();
schema.propertyKey("name").asText().ifNotExist().create();
schema.propertyKey("age").asInt().ifNotExist().create();
schema.propertyKey("city").asText().ifNotExist().create();
schema.propertyKey("weight").asDouble().ifNotExist().create();
schema.propertyKey("lang").asText().ifNotExist().create();
schema.propertyKey("date").asText().ifNotExist().create();
schema.propertyKey("price").asInt().ifNotExist().create();
schema.vertexLabel("person")
.properties("name", "age", "city")
.primaryKeys("name")
.nullableKeys("age")
.ifNotExist()
.create();
schema.vertexLabel("software")
.properties("name", "lang", "price")
.primaryKeys("name")
.nullableKeys("price")
.ifNotExist()
.create();
schema.indexLabel("personByCity")
.onV("person")
.by("city")
.secondary()
.ifNotExist()
.create();
schema.indexLabel("personByAgeAndCity")
.onV("person")
.by("age", "city")
.secondary()
.ifNotExist()
.create();
schema.indexLabel("softwareByPrice")
.onV("software")
.by("price")
.range()
.ifNotExist()
.create();
schema.edgeLabel("knows")
.multiTimes()
.sourceLabel("person")
.targetLabel("person")
.properties("date", "weight")
.sortKeys("date")
.nullableKeys("weight")
.ifNotExist()
.create();
schema.edgeLabel("created")
.sourceLabel("person").targetLabel("software")
.properties("date", "weight")
.nullableKeys("weight")
.ifNotExist()
.create();
schema.indexLabel("createdByDate")
.onE("created")
.by("date")
.secondary()
.ifNotExist()
.create();
schema.indexLabel("createdByWeight")
.onE("created")
.by("weight")
.range()
.ifNotExist()
.create();
schema.indexLabel("knowsByWeight")
.onE("knows")
.by("weight")
.range()
.ifNotExist()
.create();
GraphManager graph = client.graph();
Vertex marko = graph.addVertex(T.label, "person", "name", "marko",
"age", 29, "city", "Beijing");
Vertex vadas = graph.addVertex(T.label, "person", "name", "vadas",
"age", 27, "city", "Hongkong");
Vertex lop = graph.addVertex(T.label, "software", "name", "lop",
"lang", "java", "price", 328);
Vertex josh = graph.addVertex(T.label, "person", "name", "josh",
"age", 32, "city", "Beijing");
Vertex ripple = graph.addVertex(T.label, "software", "name", "ripple",
"lang", "java", "price", 199);
Vertex peter = graph.addVertex(T.label, "person", "name", "peter",
"age", 35, "city", "Shanghai");
marko.addEdge("knows", vadas, "date", "20160110", "weight", 0.5);
marko.addEdge("knows", josh, "date", "20130220", "weight", 1.0);
marko.addEdge("created", lop, "date", "20171210", "weight", 0.4);
josh.addEdge("created", lop, "date", "20091111", "weight", 0.4);
josh.addEdge("created", ripple, "date", "20171210", "weight", 1.0);
peter.addEdge("created", lop, "date", "20170324", "weight", 0.2);
}
}
The vertex IDs are:
"2:ripple",
"1:vadas",
"1:peter",
"1:josh",
"1:marko",
"2:lop"
The edge IDs are:
"S1:peter>2>>S2:lop",
"S1:josh>2>>S2:lop",
"S1:josh>2>>S2:ripple",
"S1:marko>1>20130220>S1:josh",
"S1:marko>1>20160110>S1:vadas",
"S1:marko>2>>S2:lop"
3.2.1 K-out API (GET, Basic Version)
3.2.1.1 Functionality Overview
The K-out API allows you to find vertices that are exactly “depth” steps away from a given starting vertex, considering the specified direction, edge type (optional), and depth.
Params
- source: ID of the starting vertex (required)
- direction: Direction of traversal from the starting vertex (OUT, IN, BOTH). Optional, default is BOTH.
- max_depth: Number of steps (required)
- label: Edge type (optional), represents all edge labels by default
- nearest: When nearest is set to true, it means the shortest path length from the starting vertex to the result vertices is equal to the depth, and there is no shorter path. When nearest is set to false, it means there is at least one path of length depth from the starting vertex to the result vertices (not necessarily the shortest and may contain cycles). Optional, default is true.
- max_degree: Maximum number of adjacent edges to traverse per vertex during the query. Optional, default is 10000.
- capacity: Maximum number of vertices to be visited during the traversal. Optional, default is 10000000.
- limit: Maximum number of vertices to be returned. Optional, default is 10000000.
3.2.1.2 Usage Example
Method & Url
GET http://localhost:8080/graphs/{graph}/traversers/kout?source="1:marko"&max_depth=2
Response Status
200
Response Body
{
"vertices":[
"2:ripple",
"1:peter"
]
}
3.2.1.3 Use Cases
Finding vertices that are exactly N steps away in a relationship. Two examples:
- In a family relationship, finding all grandchildren of a person. The set of vertices that can be reached by person A through two consecutive “son” edges.
- Discovering potential friends in a social network. For example, finding users who are two degrees of friendship away from the target user, reachable through two consecutive “friend” edges.
3.2.2 K-out API (POST, Advanced Version)
3.2.2.1 Functionality Overview
The K-out API allows you to find vertices that are exactly “depth” steps away from a given starting vertex, considering the specified steps (including direction, edge type, and attribute filtering).
The advanced version differs from the basic version of K-out API in the following aspects:
- Supports counting the number of neighbors only
- Supports edge attribute filtering
- Supports returning the shortest path to the neighbor
Params
- source: The ID of the starting vertex, required.
- steps: Steps from the starting point, required, with the following structure:
- direction: Represents the direction of the edges (OUT, IN, BOTH), default is BOTH.
- edge_steps: The step set of edges, supporting label and properties filtering for the edge. If edge_steps is empty, the edge is not filtered.
- label: Edge types.
- properties: Filter edges based on property values.
- vertex_steps: The step set of vertices, supporting label and properties filtering for the vertex. If vertex_steps is empty, the vertex is not filtered.
- label: Vertex types.
- properties: Filter vertices based on property values.
- max_degree: Maximum number of adjacent edges to traverse for a single vertex, default is 10000 (Note: Prior to version 0.12, the parameter name was “degree” instead of “max_degree”. Starting from version 0.12, “max_degree” is used uniformly, while still supporting the “degree” syntax for backward compatibility).
- skip_degree: Sets the minimum number of edges to skip super vertices during the query process. If the number of adjacent edges for a vertex is greater than skip_degree, the vertex is completely skipped. Optional. If enabled, it should satisfy the constraint
skip_degree >= max_degree. Default is 0 (not enabled), indicating no skipping of any vertices (Note: Enabling this configuration means that during traversal, an attempt will be made to access skip_degree edges of a vertex, not just max_degree edges. This incurs additional traversal overhead and may have a significant impact on query performance. Please enable it only after understanding the implications).
- max_depth: Number of steps, required.
- nearest: When nearest is true, it means the shortest path length from the starting vertex to the result vertex is equal to depth, and there is no shorter path. When nearest is false, it means there is a path of length depth from the starting vertex to the result vertex (not necessarily the shortest and can contain cycles). Optional, default is true.
- count_only: Boolean value, true indicates only counting the number of results without returning specific results, false indicates returning specific results. Default is false.
- with_path: When true, it returns the shortest path from the starting vertex to each neighbor. When false, it does not return the shortest path. Optional, default is false.
- with_edge: Optional parameter, default is false:
- When true, the result will include complete edge information (all edges in the path):
- When with_path is true, it returns complete information of all edges in all paths.
- When with_path is false, no information is returned.
- When false, it only returns edge IDs.
- When true, the result will include complete edge information (all edges in the path):
- with_vertex: Optional parameter, default is false:
- When true, the result will include complete vertex information (all vertices in the path):
- When with_path is true, it returns complete information of all vertices in all paths.
- When with_path is false, it returns complete information of all neighbors.
- When false, it only returns vertex IDs.
- When true, the result will include complete vertex information (all vertices in the path):
- capacity: Maximum number of vertices to visit during traversal. Optional, default is 10000000.
- limit: Maximum number of vertices to return. Optional, default is 10000000.
- traverse_mode: Traversal mode. There are two options: “breadth_first_search” and “depth_first_search”, default is “breadth_first_search”.
3.2.2.2 Usage
Method & Url
POST http://localhost:8080/graphs/{graph}/traversers/kout
Request Body
{
"source": "1:marko",
"steps": {
"direction": "BOTH",
"edge_steps": [
{
"label": "knows",
"properties": {
"weight": "P.gt(0.1)"
}
},
{
"label": "created",
"properties": {
"weight": "P.gt(0.1)"
}
}
],
"vertex_steps": [
{
"label": "person",
"properties": {
"age": "P.lt(32)"
}
},
{
"label": "software",
"properties": {}
}
],
"max_degree": 10000,
"skip_degree": 100000
},
"max_depth": 1,
"nearest": true,
"limit": 10000,
"with_vertex": true,
"with_path": true,
"with_edge": true
}
Response Status
200
Response Body
{
"size": 2,
"kout": [
"1:vadas",
"2:lop"
],
"paths": [
{
"objects": [
"1:marko",
"2:lop"
]
},
{
"objects": [
"1:marko",
"1:vadas"
]
}
],
"vertices": [
{
"id": "1:marko",
"label": "person",
"type": "vertex",
"properties": {
"name": "marko",
"age": 29,
"city": "Beijing"
}
},
{
"id": "1:vadas",
"label": "person",
"type": "vertex",
"properties": {
"name": "vadas",
"age": 27,
"city": "Hongkong"
}
},
{
"id": "2:lop",
"label": "software",
"type": "vertex",
"properties": {
"name": "lop",
"lang": "java",
"price": 328
}
}
],
"edges": [
{
"id": "S1:marko>1>20160110>S1:vadas",
"label": "knows",
"type": "edge",
"outV": "1:marko",
"outVLabel": "person",
"inV": "1:vadas",
"inVLabel": "person",
"properties": {
"weight": 0.5,
"date": "20160110"
}
},
{
"id": "S1:marko>2>>S2:lop",
"label": "created",
"type": "edge",
"outV": "1:marko",
"outVLabel": "person",
"inV": "2:lop",
"inVLabel": "software",
"properties": {
"weight": 0.4,
"date": "20171210"
}
}
]
}
3.2.2.3 Use Cases
Refer to 3.2.1.3.
3.2.3 K-neighbor (GET, Basic Version)
3.2.3.1 Function Introduction
Find all vertices that are reachable within depth steps, including the starting vertex, based on the starting vertex, direction, edge type (optional), and depth.
Equivalent to the union of: starting vertex, K-out(1), K-out(2), …, K-out(max_depth).
Params
- source: ID of the starting vertex, required.
- direction: Direction in which the starting vertex’s edges extend (OUT, IN, BOTH). Optional, default is BOTH.
- max_depth: Number of steps, required.
- label: Edge type, optional, default represents all edge labels.
- max_degree: Maximum number of adjacent edges to traverse for a single vertex during the query process. Optional, default is 10000.
- limit: Maximum number of vertices to return, also represents the maximum number of vertices to visit during traversal. Optional, default is 10000000.
3.2.3.2 Usage
Method & Url
GET http://localhost:8080/graphs/{graph}/traversers/kneighbor?source=“1:marko”&max_depth=2
Response Status
200
Response Body
{
"vertices":[
"2:ripple",
"1:marko",
"1:josh",
"1:vadas",
"1:peter",
"2:lop"
]
}
3.2.3.3 Use Cases
Find all vertices reachable within N steps, for example:
- In a family relationship, find all descendants within five generations of a person. This can be achieved by traversing five consecutive “parent-child” edges from person A.
- In a social network, discover friend circles. For example, users who can be reached by 1, 2, or 3 “friend” edges from the target user can form the target user’s friend circle.
3.2.4 K-neighbor API (POST, Advanced Version)
3.2.4.1 Function Introduction
Find all vertices that are reachable within depth steps from the starting vertex, based on the starting vertex, steps (including direction, edge type, and filter properties), and depth.
The difference from the Basic Version of K-neighbor API is that:
- It supports counting the number of neighbors only.
- It supports filtering edges based on their properties.
- It supports returning the shortest path to reach the neighbors.
Params
- source: Starting vertex ID, required.
- steps: Steps from the starting point, required, with the following structure:
- direction: Represents the direction of the edges (OUT, IN, BOTH), default is BOTH.
- edge_steps: The step set of edges, supporting label and properties filtering for the edge. If edge_steps is empty, the edge is not filtered.
- label: Edge types.
- properties: Filter edges based on property values.
- vertex_steps: The step set of vertices, supporting label and properties filtering for the vertex. If vertex_steps is empty, the vertex is not filtered.
- label: Vertex types.
- properties: Filter vertices based on property values.
- max_degree: Maximum number of adjacent edges to traverse for each vertex during the query process. Default is 10000. (Note: Before version 0.12, the parameter name within the step only supported “degree.” Starting from version 0.12, it is unified as “max_degree” and is backward compatible with the “degree” notation.)
- skip_degree: Used to set the minimum number of edges to discard super vertices during the query process. When the number of adjacent edges for a vertex exceeds skip_degree, the vertex is completely discarded. This is an optional parameter. If enabled, it should satisfy the constraint
skip_degree >= max_degree. Default is 0 (not enabled), which means no vertices are skipped. (Note: When this configuration is enabled, the traversal will attempt to access skip_degree edges for each vertex, not just max_degree edges. This incurs additional traversal overhead and may significantly impact query performance. Please make sure to understand this before enabling.)
- max_depth: Number of steps, required.
- count_only: Boolean value. If true, only the count of results is returned without the actual results. If false, the specific results are returned. Default is false.
- with_path: If true, the shortest path from the starting point to each neighbor is returned. If false, the shortest path from the starting point to each neighbor is not returned. This is an optional parameter. Default is false.
- with_edge: Optional parameter, default is false:
- When true, the result will include complete edge information (all edges in the path):
- When with_path is true, it returns complete information of all edges in all paths.
- When with_path is false, no information is returned.
- When false, it only returns edge IDs.
- When true, the result will include complete edge information (all edges in the path):
- with_vertex: Optional parameter, default is false:
- When true, the result will include complete vertex information (all vertices in the path):
- When with_path is true, it returns complete information of all vertices in all paths.
- When with_path is false, it returns complete information of all neighbors.
- When false, it only returns vertex IDs.
- When true, the result will include complete vertex information (all vertices in the path):
- limit: Maximum number of vertices to be returned. Also, the maximum number of vertices visited during the traversal process. This is an optional parameter. Default is 10000000.
3.2.4.2 Usage Method
Method & Url
POST http://localhost:8080/graphs/{graph}/traversers/kneighbor
Request Body
{
"source": "1:marko",
"steps": {
"direction": "BOTH",
"edge_steps": [
{
"label": "knows",
"properties": {
"weight": "P.gt(0.1)"
}
},
{
"label": "created",
"properties": {
"weight": "P.gt(0.1)"
}
}
],
"vertex_steps": [
{
"label": "person",
"properties": {
"age": "P.lt(32)"
}
},
{
"label": "software",
"properties": {}
}
],
"max_degree": 10000,
"skip_degree": 100000
},
"max_depth": 1,
"nearest": true,
"limit": 10000,
"with_vertex": true,
"with_path": true,
"with_edge": true
}
Response Status
200
Response Body
{
"size": 4,
"kneighbor": [
"1:josh",
"2:lop",
"1:peter",
"2:ripple"
],
"paths": [
{
"objects": [
"1:marko",
"2:lop"
]
},
{
"objects": [
"1:marko",
"2:lop",
"1:peter"
]
},
{
"objects": [
"1:marko",
"1:josh"
]
},
{
"objects": [
"1:marko",
"1:josh",
"2:ripple"
]
}
],
"vertices": [
{
"id": "2:ripple",
"label": "software",
"type": "vertex",
"properties": {
"name": "ripple",
"lang": "java",
"price": 199
}
},
{
"id": "1:marko",
"label": "person",
"type": "vertex",
"properties": {
"name": "marko",
"age": 29,
"city": "Beijing"
}
},
{
"id": "1:josh",
"label": "person",
"type": "vertex",
"properties": {
"name": "josh",
"age": 32,
"city": "Beijing"
}
},
{
"id": "1:peter",
"label": "person",
"type": "vertex",
"properties": {
"name": "peter",
"age": 35,
"city": "Shanghai"
}
},
{
"id": "2:lop",
"label": "software",
"type": "vertex",
"properties": {
"name": "lop",
"lang": "java",
"price": 328
}
}
],
"edges": [
{
"id": "S1:josh>2>>S2:ripple",
"label": "created",
"type": "edge",
"outV": "1:josh",
"outVLabel": "person",
"inV": "2:ripple",
"inVLabel": "software",
"properties": {
"weight": 1.0,
"date": "20171210"
}
},
{
"id": "S1:marko>2>>S2:lop",
"label": "created",
"type": "edge",
"outV": "1:marko",
"outVLabel": "person",
"inV": "2:lop",
"inVLabel": "software",
"properties": {
"weight": 0.4,
"date": "20171210"
}
},
{
"id": "S1:marko>1>20130220>S1:josh",
"label": "knows",
"type": "edge",
"outV": "1:marko",
"outVLabel": "person",
"inV": "1:josh",
"inVLabel": "person",
"properties": {
"weight": 1.0,
"date": "20130220"
}
},
{
"id": "S1:peter>2>>S2:lop",
"label": "created",
"type": "edge",
"outV": "1:peter",
"outVLabel": "person",
"inV": "2:lop",
"inVLabel": "software",
"properties": {
"weight": 0.2,
"date": "20170324"
}
}
]
}
3.2.4.3 Use Cases
See 3.2.3.3
3.2.5 Same Neighbors
3.2.5.1 Function Introduction
Retrieve the common neighbors of two vertices.
Params
- vertex: ID of one vertex, required.
- other: ID of another vertex, required.
- direction: Direction in which the vertex expands outward (OUT, IN, BOTH). Optional, default is BOTH.
- label: Edge type. Optional, default represents all edge labels.
- max_degree: Maximum number of adjacent edges to traverse for each vertex during the query process. Optional, default is 10000.
- limit: Maximum number of common neighbors to be returned. Optional, default is 10000000.
3.2.5.2 Usage Method
Method & Url
GET http://localhost:8080/graphs/{graph}/traversers/sameneighbors?vertex=“1:marko”&other="1:josh"
Response Status
200
Response Body
{
"same_neighbors":[
"2:lop"
]
}
3.2.5.3 Use Cases
Find the common neighbors of two vertices:
- In a social network, find the common followers or users both users are following.
3.2.6 Jaccard Similarity (GET)
3.2.6.1 Function Introduction
Compute the Jaccard similarity between two vertices (the intersection of the neighbors of the two vertices divided by the union of the neighbors of the two vertices).
Params
- vertex: ID of one vertex, required.
- other: ID of another vertex, required.
- direction: Direction in which the vertex expands outward (OUT, IN, BOTH). Optional, default is BOTH.
- label: Edge type. Optional, default represents all edge labels.
- max_degree: Maximum number of adjacent edges to traverse for each vertex during the query process. Optional, default is 10000.
3.2.6.2 Usage Method
Method & Url
GET http://localhost:8080/graphs/{graph}/traversers/jaccardsimilarity?vertex="1:marko"&other="1:josh"
Response Status
200
Response Body
{
"jaccard_similarity": 0.2
}
3.2.6.3 Use Cases
Used to evaluate the similarity or closeness between two vertices.
3.2.7 Jaccard Similarity (POST)
3.2.7.1 Function Introduction
Compute the N vertices with the highest Jaccard similarity to a specified vertex.
The Jaccard similarity is calculated as the intersection of the neighbors of the two vertices divided by the union of the neighbors of the two vertices.
Params
- vertex: ID of a vertex, required.
- Steps from the starting point, required. The structure is as follows:
- direction: Direction of the edges (OUT, IN, BOTH). Optional, default is BOTH.
- labels: List of edge types.
- properties: Filter edges based on property values.
- max_degree: Maximum number of adjacent edges to traverse for each vertex during the query process. Default is 10000. (Note: Prior to version 0.12, the parameter name inside “step” was “degree”. Starting from version 0.12, it is unified as “max_degree” and still compatible with “degree” notation.)
- skip_degree: Used to set the minimum number of edges to skip super vertices during the query process. If the number of adjacent edges for a vertex is greater than skip_degree, the vertex is completely skipped. Optional, default is 0 (not enabled), which means no skipping. (Note: When this configuration is enabled, the traversal will attempt to access skip_degree edges of a vertex, not just max_degree edges. This incurs additional traversal overhead and may have a significant impact on query performance. Please enable it after understanding and confirming.)
- top: Return the top N vertices with the highest Jaccard similarity for a starting vertex. Optional, default is 100.
- capacity: Maximum number of vertices to be visited during the traversal process. Optional, default is 10000000.
3.2.7.2 Usage Method
Method & Url
POST http://localhost:8080/graphs/{graph}/traversers/jaccardsimilarity
Request Body
{
"vertex": "1:marko",
"step": {
"direction": "BOTH",
"labels": [],
"max_degree": 10000,
"skip_degree": 100000
},
"top": 3
}
Response Status
200
Response Body
{
"2:ripple": 0.3333333333333333,
"1:peter": 0.3333333333333333,
"1:josh": 0.2
}
3.2.7.3 Use Cases
Used to find the vertices in the graph that have the highest similarity to a specified vertex.
3.2.8 Shortest Path
3.2.8.1 Function Introduction
Find the shortest path between a starting vertex and a target vertex based on the direction, edge type (optional), and maximum depth.
Params
- source: ID of the starting vertex, required.
- target: ID of the target vertex, required.
- direction: Direction in which the starting vertex expands (OUT, IN, BOTH). Optional, default is BOTH.
- max_depth: Maximum number of steps, required.
- label: Edge type, optional. Default represents all edge labels.
- max_degree: Maximum number of adjacent edges to traverse for each vertex during the query process. Optional, default is 10000.
- skip_degree: Used to set the minimum number of edges to skip super vertices during the query process. If the number of adjacent edges for a vertex is greater than skip_degree, the vertex is completely skipped. Optional, default is 0 (not enabled), which means no skipping. (Note: When this configuration is enabled, the traversal will attempt to access skip_degree edges of a vertex, not just max_degree edges. This incurs additional traversal overhead and may have a significant impact on query performance. Please enable it after understanding and confirming.)
- capacity: Maximum number of vertices to be visited during the traversal process. Optional, default is 10000000.
3.2.8.2 Usage Method
Method & Url
GET http://localhost:8080/graphs/{graph}/traversers/shortestpath?source="1:marko"&target="2:ripple"&max_depth=3
Response Status
200
Response Body
{
"path":[
"1:marko",
"1:josh",
"2:ripple"
]
}
3.2.8.3 Use Cases
Used to find the shortest path between two vertices, for example:
- In a social network, finding the shortest path between two users, representing the closest friend relationship chain.
- In a device association network, finding the shortest association relationship between two devices.
3.2.9 All Shortest Paths
3.2.9.1 Function Introduction
Find all shortest paths between a starting vertex and a target vertex based on the direction, edge type (optional), and maximum depth.
Params
- source: ID of the starting vertex, required.
- target: ID of the target vertex, required.
- direction: Direction in which the starting vertex expands (OUT, IN, BOTH). Optional, default is BOTH.
- max_depth: Maximum number of steps, required.
- label: Edge type, optional. Default represents all edge labels.
- max_degree: Maximum number of adjacent edges to traverse for each vertex during the query process. Optional, default is 10000.
- skip_degree: Used to set the minimum number of edges to skip super vertices during the query process. If the number of adjacent edges for a vertex is greater than skip_degree, the vertex is completely skipped. Optional, default is 0 (not enabled), which means no skipping. (Note: When this configuration is enabled, the traversal will attempt to access skip_degree edges of a vertex, not just max_degree edges. This incurs additional traversal overhead and may have a significant impact on query performance. Please enable it after understanding and confirming.)
- capacity: Maximum number of vertices to be visited during the traversal process. Optional, default is 10000000.
3.2.9.2 Usage Method
Method & Url
GET http://localhost:8080/graphs/{graph}/traversers/allshortestpaths?source="A"&target="Z"&max_depth=10
Response Status
200
Response Body
{
"paths":[
{
"objects": [
"A",
"B",
"C",
"Z"
]
},
{
"objects": [
"A",
"M",
"N",
"Z"
]
}
]
}
3.2.9.3 Use Cases
Used to find all shortest paths between two vertices, for example:
- In a social network, finding all shortest paths between two users, representing all the closest friend relationship chains.
- In a device association network, finding all shortest association relationships between two devices.
3.2.10 Weighted Shortest Path
3.2.10.1 Function Introduction
Find a weighted shortest path between a starting vertex and a target vertex based on the direction, edge type (optional), maximum depth, and edge weight property.
Params
- source: ID of the starting vertex, required.
- target: ID of the target vertex, required.
- direction: Direction in which the starting vertex expands (OUT, IN, BOTH). Optional, default is BOTH.
- label: Edge type, optional. Default represents all edge labels.
- weight: Edge weight property, required. It must be a numeric property.
- max_degree: Maximum number of adjacent edges to traverse for each vertex during the query process. Optional, default is 10000.
- skip_degree: Used to set the minimum number of edges to skip super vertices during the query process. If the number of adjacent edges for a vertex is greater than skip_degree, the vertex is completely skipped. Optional, default is 0 (not enabled), which means no skipping. (Note: When this configuration is enabled, the traversal will attempt to access skip_degree edges of a vertex, not just max_degree edges. This incurs additional traversal overhead and may have a significant impact on query performance. Please enable it after understanding and confirming.)
- capacity: Maximum number of vertices to be visited during the traversal process. Optional, default is 10000000.
- with_vertex: true to include complete vertex information (all vertices in the path) in the result, false to only return vertex IDs. Optional, default is false.
3.2.10.2 Usage Method
Method & Url
GET http://localhost:8080/graphs/{graph}/traversers/weightedshortestpath?source="1:marko"&target="2:ripple"&weight="weight"&with_vertex=true
Response Status
200
Response Body
{
"path": {
"weight": 2.0,
"vertices": [
"1:marko",
"1:josh",
"2:ripple"
]
},
"vertices": [
{
"id": "1:marko",
"label": "person",
"type": "vertex",
"properties": {
"name": "marko",
"age": 29,
"city": "Beijing"
}
},
{
"id": "1:josh",
"label": "person",
"type": "vertex",
"properties": {
"name": "josh",
"age": 32,
"city": "Beijing"
}
},
{
"id": "2:ripple",
"label": "software",
"type": "vertex",
"properties": {
"name": "ripple",
"lang": "java",
"price": 199
}
}
]
}
3.2.10.3 Use Cases
Used to find the weighted shortest path between two vertices, for example:
- In a transportation network, finding the transportation method that requires the least cost from city A to city B.
3.2.11 Single Source Shortest Path
3.2.11.1 Function Introduction
Starting from a vertex, find the shortest paths from that vertex to other vertices in the graph (optional with weight).
Params
- source: ID of the starting vertex, required.
- direction: Direction in which the starting vertex expands (OUT, IN, BOTH). Optional, default is BOTH.
- label: Edge type, optional. Default represents all edge labels.
- weight: Edge weight property, optional. It must be a numeric property. If not provided or the edges don’t have this property, the weight is considered as 1.0.
- max_degree: Maximum number of adjacent edges to traverse for each vertex during the query process. Optional, default is 10000.
- skip_degree: Used to set the minimum number of edges to skip super vertices during the query process. If the number of adjacent edges for a vertex is greater than skip_degree, the vertex is completely skipped. Optional, default is 0 (not enabled), which means no skipping. (Note: When this configuration is enabled, the traversal will attempt to access skip_degree edges of a vertex, not just max_degree edges. This incurs additional traversal overhead and may have a significant impact on query performance. Please enable it after understanding and confirming.)
- capacity: Maximum number of vertices to be visited during the traversal process. Optional, default is 10000000.
- limit: Number of target vertices to be queried and the number of shortest paths to be returned. Optional, default is 10.
- with_vertex: true to include complete vertex information (all vertices in the path) in the result, false to only return vertex IDs. Optional, default is false.
3.2.11.2 Usage Method
Method & Url
GET http://localhost:8080/graphs/{graph}/traversers/singlesourceshortestpath?source="1:marko"&with_vertex=true
Response Status
200
Response Body
{
"paths": {
"2:ripple": {
"weight": 2.0,
"vertices": [
"1:marko",
"1:josh",
"2:ripple"
]
},
"1:josh": {
"weight": 1.0,
"vertices": [
"1:marko",
"1:josh"
]
},
"1:vadas": {
"weight": 1.0,
"vertices": [
"1:marko",
"1:vadas"
]
},
"1:peter": {
"weight": 2.0,
"vertices": [
"1:marko",
"2:lop",
"1:peter"
]
},
"2:lop": {
"weight": 1.0,
"vertices": [
"1:marko",
"2:lop"
]
}
},
"vertices": [
{
"id": "2:ripple",
"label": "software",
"type": "vertex",
"properties": {
"name": "ripple",
"lang": "java",
"price": 199
}
},
{
"id": "1:marko",
"label": "person",
"type": "vertex",
"properties": {
"name": "marko",
"age": 29,
"city": "Beijing"
}
},
{
"id": "1:josh",
"label": "person",
"type": "vertex",
"properties": {
"name": "josh",
"age": 32,
"city": "Beijing"
}
},
{
"id": "1:vadas",
"label": "person",
"type": "vertex",
"properties": {
"name": "vadas",
"age": 27,
"city": "Hongkong"
}
},
{
"id": "1:peter",
"label": "person",
"type": "vertex",
"properties": {
"name": "peter",
"age": 35,
"city": "Shanghai"
}
},
{
"id": "2:lop",
"label": "software",
"type": "vertex",
"properties": {
"name": "lop",
"lang": "java",
"price": 328
}
}
]
}
3.2.11.3 Use Cases
Used to find the weighted shortest path from one vertex to other vertices, for example:
- Finding the shortest travel time by bus from Beijing to all other cities in the country.
3.2.12 Multi Node Shortest Path
3.2.12.1 Function Introduction
Finds the shortest paths between pairs of specified vertices.
Params
- vertices: Defines the starting vertices, required. It can be specified in the following ways:
- ids: Provide a list of vertex IDs as starting vertices.
- label and properties: If no IDs are specified, use the combined conditions of label and properties to query the starting vertices.
- label: Vertex type.
- properties: Query the starting vertices based on property values.
Note: Property values in properties can be a list, indicating that the value of the key can be any value in the list.
- step: Represents the path from the starting vertices to the destination vertices, required. The structure of the step is as follows:
- direction: Represents the direction of the edges (OUT, IN, BOTH). Default is BOTH.
- labels: List of edge types.
- properties: Filters the edges based on property values.
- max_degree: Maximum number of adjacent edges to traverse for each vertex during the query process. Default is 10000. (Note: Before version 0.12, the step only supported “degree” as the parameter name. Starting from version 0.12, “max_degree” is used uniformly, and “degree” is still supported for backward compatibility.)
- skip_degree: Used to set the minimum number of edges to skip super vertices during the query process. If the number of adjacent edges for a vertex is greater than skip_degree, the vertex is completely skipped. Optional, default is 0 (not enabled), which means no skipping. (Note: When this configuration is enabled, the traversal will attempt to access skip_degree edges of a vertex, not just max_degree edges. This incurs additional traversal overhead and may have a significant impact on query performance. Please enable it after understanding and confirming.)
- max_depth: Number of steps, required.
- capacity: Maximum number of vertices to be visited during the traversal process. Optional, default is 10000000.
- with_vertex: true to include complete vertex information (all vertices in the path) in the result, false to only return vertex IDs. Optional, default is false.
3.2.12.2 Usage Method
Method & Url
POST http://localhost:8080/graphs/{graph}/traversers/multinodeshortestpath
Request Body
{
"vertices": {
"ids": ["382:marko", "382:josh", "382:vadas", "382:peter", "383:lop", "383:ripple"]
},
"step": {
"direction": "BOTH",
"properties": {
}
},
"max_depth": 10,
"capacity": 100000000,
"with_vertex": true
}
Response Status
200
Response Body
{
"paths": [
{
"objects": [
"382:peter",
"383:lop"
]
},
{
"objects": [
"382:peter",
"383:lop",
"382:marko"
]
},
{
"objects": [
"382:peter",
"383:lop",
"382:josh"
]
},
{
"objects": [
"382:peter",
"383:lop",
"382:marko",
"382:vadas"
]
},
{
"objects": [
"383:lop",
"382:marko"
]
},
{
"objects": [
"383:lop",
"382:josh"
]
},
{
"objects": [
"383:lop",
"382:marko",
"382:vadas"
]
},
{
"objects": [
"382:peter",
"383:lop",
"382:josh",
"383:ripple"
]
},
{
"objects": [
"382:marko",
"382:josh"
]
},
{
"objects": [
"383:lop",
"382:josh",
"383:ripple"
]
},
{
"objects": [
"382:marko",
"382:vadas"
]
},
{
"objects": [
"382:marko",
"382:josh",
"383:ripple"
]
},
{
"objects": [
"382:josh",
"383:ripple"
]
},
{
"objects": [
"382:josh",
"382:marko",
"382:vadas"
]
},
{
"objects": [
"382:vadas",
"382:marko",
"382:josh",
"383:ripple"
]
}
],
"vertices": [
{
"id": "382:peter",
"label": "person",
"type": "vertex",
"properties": {
"name": "peter",
"age": 29,
"city": "Shanghai"
}
},
{
"id": "383:lop",
"label": "software",
"type": "vertex",
"properties": {
"name": "lop",
"lang": "java",
"price": 328
}
},
{
"id": "382:marko",
"label": "person",
"type": "vertex",
"properties": {
"name": "marko",
"age": 29,
"city": "Beijing"
}
},
{
"id": "382:josh",
"label": "person",
"type": "vertex",
"properties": {
"name": "josh",
"age": 32,
"city": "Beijing"
}
},
{
"id": "382:vadas",
"label": "person",
"type": "vertex",
"properties": {
"name": "vadas",
"age": 27,
"city": "Hongkong"
}
},
{
"id": "383:ripple",
"label": "software",
"type": "vertex",
"properties": {
"name": "ripple",
"lang": "java",
"price": 199
}
}
]
}
3.2.12.3 Use Cases
Used to find the shortest paths between multiple vertices, for example:
- Finding the shortest paths between multiple companies and their legal representatives.
3.2.13 Paths (GET, Basic Version)
3.2.13.1 Function Introduction
Finds all paths based on conditions such as the starting vertex, destination vertex, direction, edge types (optional), and maximum depth.
Params
- source: ID of the starting vertex, required.
- target: ID of the destination vertex, required.
- direction: Direction in which the starting vertex expands (OUT, IN, BOTH). Optional, default is BOTH.
- label: Edge type. Optional, default represents all edge labels.
- max_depth: Number of steps, required.
- max_degree: Maximum number of adjacent edges to traverse for each vertex during the query process. Optional, default is 10000.
- capacity: Maximum number of vertices to be visited during the traversal process. Optional, default is 10000000.
- limit: Maximum number of paths to be returned. Optional, default is 10.
3.2.13.2 Usage Method
Method & Url
GET http://localhost:8080/graphs/{graph}/traversers/paths?source="1:marko"&target="1:josh"&max_depth=5
Response Status
200
Response Body
{
"paths":[
{
"objects":[
"1:marko",
"1:josh"
]
},
{
"objects":[
"1:marko",
"2:lop",
"1:josh"
]
}
]
}
3.2.13.3 Use Cases
Used to find all paths between two vertices, for example:
- In a social network, finding all possible relationship paths between two users.
- In a device association network, finding all associated paths between two devices.
3.2.14 Paths (POST, Advanced Version)
3.2.14.1 Function Introduction
Finds all paths based on conditions such as the starting vertex, destination vertex, steps (step), and maximum depth.
Params
- sources: Defines the starting vertices, required. The specification methods include:
- ids: Provide the starting vertices through a list of vertex IDs.
- label and properties: If no IDs are specified, use the label and properties as combined conditions to query the starting vertices.
- label: Vertex type.
- properties: Query the starting vertices based on the values of their properties.
Note: The property values in properties can be a list, indicating that any value corresponding to the key is acceptable.
- targets: Defines the destination vertices, required. The specification methods include:
- ids: Provide the destination vertices through a list of vertex IDs.
- label and properties: If no IDs are specified, use the label and properties as combined conditions to query the destination vertices.
- label: Vertex type.
- properties: Query the destination vertices based on the values of their properties.
Note: The property values in properties can be a list, indicating that any value corresponding to the key is acceptable.
- step: Represents the path from the starting vertex to the destination vertex, required. The structure of Step is as follows:
- direction: Represents the direction of edges (OUT, IN, BOTH). The default is BOTH.
- labels: List of edge types.
- properties: Filters edges based on property values.
- max_degree: Maximum number of adjacent edges to traverse for each vertex during the query process. Default is 10000. (Note: Prior to version 0.12, step only supported degree as a parameter name. Starting from version 0.12, max_degree is used uniformly and degree writing is backward compatible.)
- skip_degree: Used to set the minimum number of edges to be discarded for super vertices during the query process. When the number of adjacent edges for a vertex is greater than skip_degree, the vertex is completely discarded. Optional, if enabled, it must satisfy the constraint
skip_degree >= max_degree. Default is 0 (not enabled), which means no points are skipped. (Note: When this configuration is enabled, the traversal will attempt to visit skip_degree edges of a vertex, not just max_degree edges. This incurs additional traversal overhead and may have a significant impact on query performance. Please make sure to understand before enabling it.)
- max_depth: Number of steps, required.
- nearest: When nearest is true, it means the shortest path length from the starting vertex to the result vertex is depth, and there is no shorter path. When nearest is false, it means there is a path of length depth from the starting vertex to the result vertex (not necessarily the shortest path and can have cycles). Optional, default is true.
- capacity: Maximum number of vertices to be visited during the traversal process. Optional, default is 10000000.
- limit: Maximum number of paths to be returned. Optional, default is 10.
- with_vertex: When true, the results include complete vertex information (all vertices in the path). When false, only the vertex IDs are returned. Optional, default is false.
3.2.14.2 Usage Method
Method & Url
POST http://localhost:8080/graphs/{graph}/traversers/paths
Request Body
{
"sources": {
"ids": ["1:marko"]
},
"targets": {
"ids": ["1:peter"]
},
"step": {
"direction": "BOTH",
"properties": {
"weight": "P.gt(0.01)"
}
},
"max_depth": 10,
"capacity": 100000000,
"limit": 10000000,
"with_vertex": false
}
Response Status
200
Response Body
{
"paths": [
{
"objects": [
"1:marko",
"1:josh",
"2:lop",
"1:peter"
]
},
{
"objects": [
"1:marko",
"2:lop",
"1:peter"
]
}
]
}
3.2.14.3 Use Cases
Used to find all paths between two vertices, for example:
- In a social network, finding all possible relationship paths between two users.
- In a device association network, finding all associated paths between two devices.
3.2.15 Customized Paths
3.2.15.1 Function Introduction
Finds all paths that meet the specified conditions based on a batch of starting vertices, edge rules (including direction, edge types, and property filters), and maximum depth.
Params
- sources: Defines the starting vertices, required. The specification methods include:
- ids: Provide the starting vertices through a list of vertex IDs.
- label and properties: If no IDs are specified, use the label and properties as combined conditions to query the starting vertices.
- label: Vertex type.
- properties: Query the starting vertices based on the values of their properties.
Note: The property values in properties can be a list, indicating that any value corresponding to the key is acceptable.
- steps: Represents the path rules traversed from the starting vertices and is a list of Steps. Required. The structure of each Step is as follows:
- direction: Represents the direction of edges (OUT, IN, BOTH). The default is BOTH.
- labels: List of edge types.
- properties: Filters edges based on property values.
- weight_by: Calculates the weight of edges based on the specified property. It is effective when sort_by is not NONE and is mutually exclusive with default_weight.
- default_weight: The default weight to be used when there is no property to calculate the weight of edges. It is effective when sort_by is not NONE and is mutually exclusive with weight_by.
- max_degree: Maximum number of adjacent edges to traverse for each vertex during the query process. Default is 10000. (Note: Prior to version 0.12, step only supported degree as a parameter name. Starting from version 0.12, max_degree is used uniformly and degree writing is backward compatible.)
- sample: Used when sampling is needed for the edges that meet the conditions of a specific step. -1 means no sampling, and the default is to sample 100 edges.
- sort_by: Sorts the paths based on their weights. Optional, default is NONE:
- NONE: No sorting, default value.
- INCR: Sorts in ascending order based on path weights.
- DECR: Sorts in descending order based on path weights.
- capacity: Maximum number of vertices to be visited during the traversal process. Optional, default is 10000000.
- limit: Maximum number of paths to be returned. Optional, default is 10.
- with_vertex: When true, the results include complete vertex information (all vertices in the path). When false, only the vertex IDs are returned. Optional, default is false.
3.2.15.2 Usage Method
Method & Url
POST http://localhost:8080/graphs/{graph}/traversers/customizedpaths
Request Body
{
"sources":{
"ids":[
],
"label":"person",
"properties":{
"name":"marko"
}
},
"steps":[
{
"direction":"OUT",
"labels":[
"knows"
],
"weight_by":"weight",
"max_degree":-1
},
{
"direction":"OUT",
"labels":[
"created"
],
"default_weight":8,
"max_degree":-1,
"sample":1
}
],
"sort_by":"INCR",
"with_vertex":true,
"capacity":-1,
"limit":-1
}
Response Status
200
Response Body
{
"paths":[
{
"objects":[
"1:marko",
"1:josh",
"2:lop"
],
"weights":[
1,
8
]
}
],
"vertices":[
{
"id":"1:marko",
"label":"person",
"type":"vertex",
"properties":{
"city":[
{
"id":"1:marko>city",
"value":"Beijing"
}
],
"name":[
{
"id":"1:marko>name",
"value":"marko"
}
],
"age":[
{
"id":"1:marko>age",
"value":29
}
]
}
},
{
"id":"1:josh",
"label":"person",
"type":"vertex",
"properties":{
"city":[
{
"id":"1:josh>city",
"value":"Beijing"
}
],
"name":[
{
"id":"1:josh>name",
"value":"josh"
}
],
"age":[
{
"id":"1:josh>age",
"value":32
}
]
}
},
{
"id":"2:lop",
"label":"software",
"type":"vertex",
"properties":{
"price":[
{
"id":"2:lop>price",
"value":328
}
],
"name":[
{
"id":"2:lop>name",
"value":"lop"
}
],
"lang":[
{
"id":"2:lop>lang",
"value":"java"
}
]
}
}
]
}
3.2.15.3 Use Cases
Suitable for finding various complex sets of paths, for example:
- In a social network, finding the paths from users who have watched movies directed by Zhang Yimou to the influencers they follow (Zhang Yimou —> Movie —> User —> Influencer).
- In a risk control network, finding the paths from multiple high-risk users to the friends of their direct relatives (High-risk user —> Direct relative —> Friend).
3.2.16 Template Paths
3.2.16.1 Function Introduction
Finds all paths that meet the specified conditions based on a batch of starting vertices, edge rules (including direction, edge types, and property filters), and maximum depth.
Params
- sources: Defines the starting vertices, required. The specification methods include:
- ids: Provide the starting vertices through a list of vertex IDs.
- label and properties: If no IDs are specified, use the label and properties as combined conditions to query the starting vertices.
- label: Vertex type.
- properties: Query the starting vertices based on the values of their properties.
Note: The property values in properties can be a list, indicating that any value corresponding to the key is acceptable.
- targets: Defines the ending vertices, required. The specification methods include:
- ids: Provide the ending vertices through a list of vertex IDs.
- label and properties: If no IDs are specified, use the label and properties as combined conditions to query the ending vertices.
- label: Vertex type.
- properties: Query the ending vertices based on the values of their properties.
Note: The property values in properties can be a list, indicating that any value corresponding to the key is acceptable.
- steps: Represents the path rules traversed from the starting vertices and is a list of Steps. Required. The structure of each Step is as follows:
- direction: Represents the direction of edges (OUT, IN, BOTH). The default is BOTH.
- labels: List of edge types.
- properties: Filters edges based on property values.
- max_times: The number of times the current step can be repeated. When set to N, it means the starting vertices can pass through the current step 1-N times.
- max_degree: Maximum number of adjacent edges to traverse for each vertex during the query process. Default is 10000. (Note: Prior to version 0.12, step only supported degree as a parameter name. Starting from version 0.12, max_degree is used uniformly and degree writing is backward compatible.)
- skip_degree: Used to set the minimum number of edges to discard super vertices during the query process. When the number of adjacent edges of a vertex is greater than skip_degree, the vertex is completely discarded. Optional. If enabled, it must satisfy the
skip_degree >= max_degreeconstraint. Default is 0 (not enabled), which means no points are skipped. (Note: After enabling this configuration, traversing will attempt to access a vertex’s skip_degree edges, not just max_degree edges. This incurs additional traversal overhead and may have a significant impact on query performance. Please ensure understanding before enabling.)
- with_ring: Boolean value, true to include cycles; false to exclude cycles. Default is false.
- capacity: Maximum number of vertices to be visited during the traversal process. Optional, default is 10000000.
- limit: Maximum number of paths to be returned. Optional, default is 10.
- with_vertex: When true, the results include complete vertex information (all vertices in the path). When false, only the vertex IDs are returned. Optional, default is
false.
3.2.16.2 Usage Method
Method & Url
POST http://localhost:8080/graphs/{graph}/traversers/templatepaths
Request Body
{
"sources": {
"ids": [],
"label": "person",
"properties": {
"name": "vadas"
}
},
"targets": {
"ids": [],
"label": "software",
"properties": {
"name": "ripple"
}
},
"steps": [
{
"direction": "IN",
"labels": ["knows"],
"properties": {
},
"max_degree": 10000,
"skip_degree": 100000
},
{
"direction": "OUT",
"labels": ["created"],
"properties": {
},
"max_degree": 10000,
"skip_degree": 100000
},
{
"direction": "IN",
"labels": ["created"],
"properties": {
},
"max_degree": 10000,
"skip_degree": 100000
},
{
"direction": "OUT",
"labels": ["created"],
"properties": {
},
"max_degree": 10000,
"skip_degree": 100000
}
],
"capacity": 10000,
"limit": 10,
"with_vertex": true
}
Response Status
200
Response Body
{
"paths": [
{
"objects": [
"1:vadas",
"1:marko",
"2:lop",
"1:josh",
"2:ripple"
]
}
],
"vertices": [
{
"id": "2:ripple",
"label": "software",
"type": "vertex",
"properties": {
"name": "ripple",
"lang": "java",
"price": 199
}
},
{
"id": "1:marko",
"label": "person",
"type": "vertex",
"properties": {
"name": "marko",
"age": 29,
"city": "Beijing"
}
},
{
"id": "1:josh",
"label": "person",
"type": "vertex",
"properties": {
"name": "josh",
"age": 32,
"city": "Beijing"
}
},
{
"id": "1:vadas",
"label": "person",
"type": "vertex",
"properties": {
"name": "vadas",
"age": 27,
"city": "Hongkong"
}
},
{
"id": "2:lop",
"label": "software",
"type": "vertex",
"properties": {
"name": "lop",
"lang": "java",
"price": 328
}
}
]
}
3.2.16.3 Use Cases
Suitable for finding various complex template paths, such as personA -(Friend)-> personB -(Classmate)-> personC, where the “Friend” and “Classmate” edges can have a maximum depth of 3 and 4 layers, respectively.
3.2.17 Crosspoints
3.2.17.1 Function Introduction
Finds the intersection points based on the specified conditions, including starting vertices, destination vertices, direction, edge types (optional), and maximum depth.
Params
- source: ID of the starting vertex, required.
- target: ID of the destination vertex, required.
- direction: The direction from the starting vertex to the destination vertex. The reverse direction is used from the destination vertex to the starting vertex. When set to BOTH, the direction is not considered (OUT, IN, BOTH). Optional, default is BOTH.
- label: Edge type, optional. Default represents all edge labels.
- max_depth: Number of steps, required.
- max_degree: Maximum number of adjacent edges to traverse for each vertex during the query process. Optional, default is 10000.
- capacity: Maximum number of vertices to be visited during the traversal process. Optional, default is 10000000.
- limit: Maximum number of intersection points to be returned. Optional, default is 10.
3.2.17.2 Usage Method
Method & Url
GET http://localhost:8080/graphs/{graph}/traversers/crosspoints?source="2:lop"&target="2:ripple"&max_depth=5&direction=IN
Response Status
200
Response Body
{
"crosspoints":[
{
"crosspoint":"1:josh",
"objects":[
"2:lop",
"1:josh",
"2:ripple"
]
}
]
}
3.2.17.3 Use Cases
Used to find the intersection points and their paths between two vertices, such as:
- In a social network, finding the topics or influencers that two users have in common.
- In a family relationship, finding common ancestors.
3.2.18 Customized Crosspoints
3.2.18.1 Function Introduction
Finds the intersection of destination vertices that satisfy the specified conditions, including starting vertices, multiple edge rules (including direction, edge type, and property filters), and maximum depth.
Params
sources: Defines the starting vertices, required. The specified options include:
- ids: Provides a list of vertex IDs as starting vertices.
- label and properties: If no IDs are specified, uses the combined conditions of label and properties to query the starting vertices.
- label: Type of the vertex.
- properties: Queries the starting vertices based on property values.
Note: Property values in properties can be a list, indicating that the value of the key can be any item in the list.
path_patterns: Represents the path rules to be followed from the starting vertices. It is a list of rules. Required. Each rule is a PathPattern.
- Each PathPattern consists of a list of steps, where each step has the following structure:
- direction: Indicates the direction of the edge (OUT, IN, BOTH). Default is BOTH.
- labels: List of edge types.
- properties: Filters the edges based on property values.
- max_degree: Maximum number of adjacent edges to traverse for each vertex during the query process. Default is 10000.
- skip_degree: Sets the minimum number of edges to discard super vertices during the query process. If the number of adjacent edges for a vertex is greater than skip_degree, the vertex is completely discarded. Optional. If enabled, it must satisfy the constraint
skip_degree >= max_degree. Default is 0 (not enabled), which means no vertices are skipped. Note: When this configuration is enabled, the traversal process will attempt to visit skip_degree edges of a vertex, not just max_degree edges. This incurs additional traversal overhead and may significantly impact query performance. Please make sure you understand it before enabling.
- Each PathPattern consists of a list of steps, where each step has the following structure:
capacity: Maximum number of vertices to be visited during the traversal process. Optional. Default is 10000000.
limit: Maximum number of paths to be returned. Optional. Default is 10.
with_path: When set to true, returns the paths where the intersection points are located. When set to false, does not return the paths. Optional. Default is false.
with_vertex: Optional. Default is false.
- When set to true, the result includes complete vertex information (all vertices in the paths):
- When with_path is true, it returns complete information of all vertices in the paths.
- When with_path is false, it returns complete information of all intersection points.
- When set to false, only the vertex IDs are returned.
- When set to true, the result includes complete vertex information (all vertices in the paths):
3.2.18.2 Usage Method
Method & Url
POST http://localhost:8080/graphs/{graph}/traversers/customizedcrosspoints
Request Body
{
"sources":{
"ids":[
"2:lop",
"2:ripple"
]
},
"path_patterns":[
{
"steps":[
{
"direction":"IN",
"labels":[
"created"
],
"max_degree":-1
}
]
}
],
"with_path":true,
"with_vertex":true,
"capacity":-1,
"limit":-1
}
Response Status
200
Response Body
{
"crosspoints":[
"1:josh"
],
"paths":[
{
"objects":[
"2:ripple",
"1:josh"
]
},
{
"objects":[
"2:lop",
"1:josh"
]
}
],
"vertices":[
{
"id":"2:ripple",
"label":"software",
"type":"vertex",
"properties":{
"price":[
{
"id":"2:ripple>price",
"value":199
}
],
"name":[
{
"id":"2:ripple>name",
"value":"ripple"
}
],
"lang":[
{
"id":"2:ripple>lang",
"value":"java"
}
]
}
},
{
"id":"1:josh",
"label":"person",
"type":"vertex",
"properties":{
"city":[
{
"id":"1:josh>city",
"value":"Beijing"
}
],
"name":[
{
"id":"1:josh>name",
"value":"josh"
}
],
"age":[
{
"id":"1:josh>age",
"value":32
}
]
}
},
{
"id":"2:lop",
"label":"software",
"type":"vertex",
"properties":{
"price":[
{
"id":"2:lop>price",
"value":328
}
],
"name":[
{
"id":"2:lop>name",
"value":"lop"
}
],
"lang":[
{
"id":"2:lop>lang",
"value":"java"
}
]
}
}
]
}
3.2.18.3 Use Cases
Used to query a group of vertices that have intersections at the destination through multiple paths. For example:
- In a product knowledge graph, multiple models of smartphones, learning devices, and gaming devices belong to the top-level category of electronic devices through different lower-level category paths.
3.2.19 Rings
3.2.19.1 Function Introduction
Finds reachable cycles based on the specified conditions, including starting vertices, direction, edge types (optional), and maximum depth.
For example: 1 -> 25 -> 775 -> 14690 -> 25, where the cycle is 25 -> 775 -> 14690 -> 25.
Params
- source: Starting vertex ID, required.
- direction: Direction of edges emitted from the starting vertex (OUT, IN, BOTH). Optional. Default is BOTH.
- label: Edge type. Optional. Default represents all edge labels.
- max_depth: Number of steps. Required.
- source_in_ring: Whether the starting point is included in the cycle. Optional. Default is true.
- max_degree: Maximum number of adjacent edges to traverse for each vertex during the query process. Optional. Default is 10000.
- capacity: Maximum number of vertices to be visited during the traversal process. Optional. Default is 10000000.
- limit: Maximum number of reachable cycles to be returned. Optional. Default is 10.
3.2.19.2 Usage Method
Method & Url
GET http://localhost:8080/graphs/{graph}/traversers/rings?source="1:marko"&max_depth=2
Response Status
200
Response Body
{
"rings":[
{
"objects":[
"1:marko",
"1:josh",
"1:marko"
]
},
{
"objects":[
"1:marko",
"1:vadas",
"1:marko"
]
},
{
"objects":[
"1:marko",
"2:lop",
"1:marko"
]
}
]
}
3.2.19.3 Use Cases
Used to query cycles reachable from the starting vertex, for example:
- In a risk control project, querying individuals or devices involved in a circular guarantee that a user is connected to.
- In a device network, discovering devices that have circular references around a specific device.
3.2.20 Rays
3.2.20.1 Function Introduction
Finds paths that diverge from the starting vertex and reach boundary vertices based on the specified conditions, including starting vertices, direction, edge types (optional), and maximum depth.
For example: 1 -> 25 -> 775 -> 14690 -> 2289 -> 18379, where 18379 is the boundary vertex, meaning there are no edges emitted from 18379.
Params
- source: Starting vertex ID, required.
- direction: Direction of edges emitted from the starting vertex (OUT, IN, BOTH). Optional. Default is BOTH.
- label: Edge type. Optional. Default represents all edge labels.
- max_depth: Number of steps. Required.
- max_degree: Maximum number of adjacent edges to traverse for each vertex during the query process. Optional. Default is 10000.
- capacity: Maximum number of vertices to be visited during the traversal process. Optional. Default is 10000000.
- limit: Maximum number of non-cycle paths to be returned. Optional. Default is 10.
3.2.20.2 Usage Method
Method & Url
GET http://localhost:8080/graphs/{graph}/traversers/rays?source="1:marko"&max_depth=2&direction=OUT
Response Status
200
Response Body
{
"rays":[
{
"objects":[
"1:marko",
"1:vadas"
]
},
{
"objects":[
"1:marko",
"2:lop"
]
},
{
"objects":[
"1:marko",
"1:josh",
"2:ripple"
]
},
{
"objects":[
"1:marko",
"1:josh",
"2:lop"
]
}
]
}
3.2.20.3 Use Cases
Used to find paths from the starting vertex to boundary vertices based on a specific relationship, for example:
- In a family relationship, finding paths from a person to all descendants who do not have children.
- In a device network, discovering paths from a specific device to terminal devices.
3.2.21 Fusiform Similarity
3.2.21.1 Function Introduction
Queries a batch of “fusiform similar vertices” based on specified conditions. When two vertices share a certain relationship with many common vertices, they are considered “fusiform similar vertices.” For example, if “Reader A” has read 100 books, readers who have read 80 or more of these 100 books can be defined as “fusiform similar vertices” of “Reader A.”
Params
sources: Starting vertices, required. Specify using:
- ids: Provide a list of vertex IDs as starting vertices.
- label and properties: If ids are not specified, use the combined conditions of label and properties to query the starting vertices.
- label: Vertex type.
- properties: Query the starting vertices based on the values of their properties.
Note: Property values in properties can be a list, indicating that the value of the key can be any value in the list.
label: Edge type. Optional. Default represents all edge labels.
direction: Direction in which the starting vertex diverges (OUT, IN, BOTH). Optional. Default is BOTH.
min_neighbors: Minimum number of neighbors. If the number of neighbors is less than this threshold, the starting vertex is not considered a “fusiform similar vertex.” For example, if you want to find “fusiform similar vertices” of books read by “Reader A,” and min_neighbors is set to 100, it means that “Reader A” must have read at least 100 books to have “fusiform similar vertices.” Required.
alpha: Similarity, representing the proportion of common neighbors between the starting vertex and “fusiform similar vertices” to all neighbors of the starting vertex. Required.
min_similars: Minimum number of “fusiform similar vertices.” Only when the number of “fusiform similar vertices” of the starting vertex is greater than or equal to this value, the starting vertex and its “fusiform similar vertices” will be returned. Optional. Default is 1.
top: Returns the top highest similarity “fusiform similar vertices” of a starting vertex. Required. 0 means all.
group_property: Used together with min_groups. Returns the starting vertex and its “fusiform similar vertices” only if there are at least min_groups different values for a certain attribute of the starting vertex and its “fusiform similar vertices.” For example, when recommending “out-of-town” book buddies for “Reader A,” set group_property to the “city” attribute of readers and min_group to at least 2. Optional. If not specified, no filtering based on attributes is needed.
min_groups: Used together with group_property. Only meaningful when group_property is set.
max_degree: Maximum number of adjacent edges to traverse for each vertex during the query process. Optional. Default is 10000.
capacity: Maximum number of vertices to be visited during the traversal process. Optional. Default is 10000000.
limit: Maximum number of results to be returned (one starting vertex and its “fusiform similar vertices” count as one result). Optional. Default is 10.
with_intermediary: Whether to return the starting vertex and the intermediate vertices that are commonly related to the “fusiform
similar vertices.” Default is false.
- with_vertex: Optional. Default is false.
- true: Returns complete vertex information in the results.
- false: Only returns vertex IDs.
3.2.21.2 Usage Method
Method & Url
POST http://localhost:8080/graphspaces/DEFAULT/graphs/hugegraph/traversers/fusiformsimilarity
Request Body
{
"sources":{
"ids":[],
"label": "person",
"properties": {
"name":"p1"
}
},
"label":"read",
"direction":"OUT",
"min_neighbors":8,
"alpha":0.75,
"min_similars":1,
"top":0,
"group_property":"city",
"min_group":2,
"max_degree": 10000,
"capacity": -1,
"limit": -1,
"with_intermediary": false,
"with_vertex":true
}
Response Status
200
Response Body
{
"similars": {
"3:p1": [
{
"id": "3:p2",
"score": 0.8888888888888888,
"intermediaries": [
]
},
{
"id": "3:p3",
"score": 0.7777777777777778,
"intermediaries": [
]
}
]
},
"vertices": [
{
"id": "3:p1",
"label": "person",
"type": "vertex",
"properties": {
"name": "p1",
"city": "Beijing"
}
},
{
"id": "3:p2",
"label": "person",
"type": "vertex",
"properties": {
"name": "p2",
"city": "Shanghai"
}
},
{
"id": "3:p3",
"label": "person",
"type": "vertex",
"properties": {
"name": "p3",
"city": "Beijing"
}
}
]
}
3.2.21.3 Use Cases
Used to query vertices that have high similarity with a group of vertices. For example:
- Readers with similar book lists to a specific reader.
- Players who play similar games to a specific player.
3.2.22 Vertices
3.2.22.1 Batch Query Vertices by Vertex IDs
Params
- ids: List of vertex IDs to be queried.
Method & Url
GET http://localhost:8080/graphspaces/DEFAULT/graphs/hugegraph/traversers/vertices?ids="1:marko"&ids="2:lop"
Response Status
200
Response Body
{
"vertices":[
{
"id":"1:marko",
"label":"person",
"type":"vertex",
"properties":{
"city":[
{
"id":"1:marko>city",
"value":"Beijing"
}
],
"name":[
{
"id":"1:marko>name",
"value":"marko"
}
],
"age":[
{
"id":"1:marko>age",
"value":29
}
]
}
},
{
"id":"2:lop",
"label":"software",
"type":"vertex",
"properties":{
"price":[
{
"id":"2:lop>price",
"value":328
}
],
"name":[
{
"id":"2:lop>name",
"value":"lop"
}
],
"lang":[
{
"id":"2:lop>lang",
"value":"java"
}
]
}
}
]
}
3.2.22.2 Get Vertex Shard Information
Obtain vertex shard information by specifying the shard size split_size (can be used in conjunction with Scan in 3.2.21.3 to retrieve vertices).
Params
- split_size: Shard size, required.
Method & Url
GET http://localhost:8080/graphspaces/DEFAULT/graphs/hugegraph/traversers/vertices/shards?split_size=67108864
Response Status
200
Response Body
{
"shards":[
{
"start": "0",
"end": "2165893",
"length": 0
},
{
"start": "2165893",
"end": "4331786",
"length": 0
},
{
"start": "4331786",
"end": "6497679",
"length": 0
},
{
"start": "6497679",
"end": "8663572",
"length": 0
},
......
]
}
3.2.22.3 Batch Retrieve Vertices Based on Shard Information
Retrieve vertices in batches based on the specified shard information (refer to 3.2.21.2 Shard for obtaining shard information).
Params
- start: Shard start position, required.
- end: Shard end position, required.
- page: Page position for pagination, optional. Default is null, no pagination. When page is “”, it represents the first page of pagination starting from the position indicated by start.
- page_limit: The upper limit of the number of vertices per page when retrieving vertices with pagination, optional. Default is 100000.
Method & Url
GET http://localhost:8080/graphspaces/DEFAULT/graphs/hugegraph/traversers/vertices/scan?start=0&end=4294967295
Response Status
200
Response Body
{
"vertices":[
{
"id":"2:ripple",
"label":"software",
"type":"vertex",
"properties":{
"price":[
{
"id":"2:ripple>price",
"value":199
}
],
"name":[
{
"id":"2:ripple>name",
"value":"ripple"
}
],
"lang":[
{
"id":"2:ripple>lang",
"value":"java"
}
]
}
},
{
"id":"1:vadas",
"label":"person",
"type":"vertex",
"properties":{
"city":[
{
"id":"1:vadas>city",
"value":"Hongkong"
}
],
"name":[
{
"id":"1:vadas>name",
"value":"vadas"
}
],
"age":[
{
"id":"1:vadas>age",
"value":27
}
]
}
},
{
"id":"1:peter",
"label":"person",
"type":"vertex",
"properties":{
"city":[
{
"id":"1:peter>city",
"value":"Shanghai"
}
],
"name":[
{
"id":"1:peter>name",
"value":"peter"
}
],
"age":[
{
"id":"1:peter>age",
"value":35
}
]
}
},
{
"id":"1:josh",
"label":"person",
"type":"vertex",
"properties":{
"city":[
{
"id":"1:josh>city",
"value":"Beijing"
}
],
"name":[
{
"id":"1:josh>name",
"value":"josh"
}
],
"age":[
{
"id":"1:josh>age",
"value":32
}
]
}
},
{
"id":"1:marko",
"label":"person",
"type":"vertex",
"properties":{
"city":[
{
"id":"1:marko>city",
"value":"Beijing"
}
],
"name":[
{
"id":"1:marko>name",
"value":"marko"
}
],
"age":[
{
"id":"1:marko>age",
"value":29
}
]
}
},
{
"id":"2:lop",
"label":"software",
"type":"vertex",
"properties":{
"price":[
{
"id":"2:lop>price",
"value":328
}
],
"name":[
{
"id":"2:lop>name",
"value":"lop"
}
],
"lang":[
{
"id":"2:lop>lang",
"value":"java"
}
]
}
}
]
}
3.2.22.4 Use Cases
- Querying vertices by ID list, which can be used for batch vertex queries. For example, after querying multiple paths in a path search, you can further query all vertex properties of a specific path.
- Retrieving shards and querying vertices by shard, which can be used to traverse all vertices.
3.2.23 Edges
3.2.23.1 Batch Retrieve Edges Based on Edge IDs
Params
- ids: List of edge IDs to be queried.
Method & Url
GET http://localhost:8080/graphspaces/DEFAULT/graphs/hugegraph/traversers/edges?ids="S1:josh>1>>S2:lop"&ids="S1:josh>1>>S2:ripple"
Response Status
200
Response Body
{
"edges": [
{
"id": "S1:josh>1>>S2:lop",
"label": "created",
"type": "edge",
"inVLabel": "software",
"outVLabel": "person",
"inV": "2:lop",
"outV": "1:josh",
"properties": {
"date": "20091111",
"weight": 0.4
}
},
{
"id": "S1:josh>1>>S2:ripple",
"label": "created",
"type": "edge",
"inVLabel": "software",
"outVLabel": "person",
"inV": "2:ripple",
"outV": "1:josh",
"properties": {
"date": "20171210",
"weight": 1
}
}
]
}
3.2.23.2 Retrieve Edge Shard Information
Retrieve shard information for edges by specifying the shard size (split_size). This can be used in conjunction with the Scan operation described in section 3.2.22.3 to retrieve edges.
Params
- split_size: Shard size, required field.
Method & Url
GET http://localhost:8080/graphspaces/DEFAULT/graphs/hugegraph/traversers/edges/shards?split_size=4294967295
Response Status
200
Response Body
{
"shards":[
{
"start": "0",
"end": "1073741823",
"length": 0
},
{
"start": "1073741823",
"end": "2147483646",
"length": 0
},
{
"start": "2147483646",
"end": "3221225469",
"length": 0
},
{
"start": "3221225469",
"end": "4294967292",
"length": 0
},
{
"start": "4294967292",
"end": "4294967295",
"length": 0
}
]
}
3.2.23.3 Batch Retrieve Edges Based on Shard Information
Batch retrieve edges by specifying shard information (refer to section 3.2.22.2 for shard retrieval).
Params
- start: Shard starting position, required field.
- end: Shard ending position, required field.
- page: Page position for pagination, optional field. Default is null, which means no pagination. When
pageis empty, it indicates the first page of pagination starting from the position indicated bystart. - page_limit: Upper limit of the number of edges per page for paginated retrieval, optional field. Default is 100000.
Method & Url
GET http://localhost:8080/graphspaces/DEFAULT/graphs/hugegraph/traversers/edges/scan?start=0&end=3221225469
Response Status
200
Response Body
{
"edges":[
{
"id":"S1:peter>2>>S2:lop",
"label":"created",
"type":"edge",
"inVLabel":"software",
"outVLabel":"person",
"inV":"2:lop",
"outV":"1:peter",
"properties":{
"weight":0.2,
"date":"20170324"
}
},
{
"id":"S1:josh>2>>S2:lop",
"label":"created",
"type":"edge",
"inVLabel":"software",
"outVLabel":"person",
"inV":"2:lop",
"outV":"1:josh",
"properties":{
"weight":0.4,
"date":"20091111"
}
},
{
"id":"S1:josh>2>>S2:ripple",
"label":"created",
"type":"edge",
"inVLabel":"software",
"outVLabel":"person",
"inV":"2:ripple",
"outV":"1:josh",
"properties":{
"weight":1,
"date":"20171210"
}
},
{
"id":"S1:marko>1>20130220>S1:josh",
"label":"knows",
"type":"edge",
"inVLabel":"person",
"outVLabel":"person",
"inV":"1:josh",
"outV":"1:marko",
"properties":{
"weight":1,
"date":"20130220"
}
},
{
"id":"S1:marko>1>20160110>S1:vadas",
"label":"knows",
"type":"edge",
"inVLabel":"person",
"outVLabel":"person",
"inV":"1:vadas",
"outV":"1:marko",
"properties":{
"weight":0.5,
"date":"20160110"
}
},
{
"id":"S1:marko>2>>S2:lop",
"label":"created",
"type":"edge",
"inVLabel":"software",
"outVLabel":"person",
"inV":"2:lop",
"outV":"1:marko",
"properties":{
"weight":0.4,
"date":"20171210"
}
}
]
}
3.2.23.4 Use Cases
- Querying edges based on ID list, suitable for batch retrieval of edges.
- Retrieving shard information and querying edges based on shards, useful for traversing all edges.
1.11 - Rank API
4.1 Rank API overview
Not only the Graph iteration (traverser) method, HugeGraph-Server also provide Rank API for recommendation purpose.
You can use it to recommend some vertexes much closer to a vertex.
4.2 Details of Rank API
4.2.1 Personal Rank API
A typical scenario for Personal Rank algorithm is in recommendation application. According to the out edges of a vertex,
recommend some other vertices that having the same or similar edges.
Here is a use case: According to someone’s reading habit or reading history, we can recommend some books he may be interested or some book pal.
For Example:
- Suppose we have a vertex, Person type, and named tom.He like 5 books
a,b,c,d,e. If we want to recommend some book pal and books for tom, an easier idea is let’s check whoever also liked these books (common hobby based). - Now, we need someone else, like neo, he like three books
b,d,f. And Jay, he like 4 booksc,d,e,g, and Lee, he also like 4 booksa,d,e,f. - For we don’t need to recommend books tom already read, the recommend-list should only contain the books Tom’s book pal already read but tom haven’t read yet. Such as book “f” and “g”, and with priority f > g.
- Now, we recompute Tom’s personal rank value, we will get a sorted TopN book pal or book recommend-list. (Choose OTHER_LABEL,for Only Book purpose)
4.2.1.0 Data Preparation
The case above is simple. Here we also provide a public test dataset MovieLens for use case. You should download the dataset. The load it into HugeGraph with HugeGraph-Loader. To make it simple, we ignore all properties data of user and move. only field id is enough. we also ignore the value of edge rating.
The metadata for input file and mapping file as follows:
////////////////////////////////////////////////////////////
// UserID::Gender::Age::Occupation::Zip-code
// MovieID::Title::Genres
// UserID::MovieID::Rating::Timestamp
////////////////////////////////////////////////////////////
// Define schema
schema.propertyKey("id").asInt().ifNotExist().create();
schema.propertyKey("rate").asInt().ifNotExist().create();
schema.vertexLabel("user")
.properties("id")
.primaryKeys("id")
.ifNotExist()
.create();
schema.vertexLabel("movie")
.properties("id")
.primaryKeys("id")
.ifNotExist()
.create();
schema.edgeLabel("rating")
.sourceLabel("user")
.targetLabel("movie")
.properties("rate")
.ifNotExist()
.create();
{
"vertices": [
{
"label": "user",
"input": {
"type": "file",
"path": "users.dat",
"format": "TEXT",
"delimiter": "::",
"header": ["UserID", "Gender", "Age", "Occupation", "Zip-code"]
},
"ignored": ["Gender", "Age", "Occupation", "Zip-code"],
"mapping": {
"UserID": "id"
}
},
{
"label": "movie",
"input": {
"type": "file",
"path": "movies.dat",
"format": "TEXT",
"delimiter": "::",
"header": ["MovieID", "Title", "Genres"]
},
"ignored": ["Title", "Genres"],
"mapping": {
"MovieID": "id"
}
}
],
"edges": [
{
"label": "rating",
"source": ["UserID"],
"target": ["MovieID"],
"input": {
"type": "file",
"path": "ratings.dat",
"format": "TEXT",
"delimiter": "::",
"header": ["UserID", "MovieID", "Rating", "Timestamp"]
},
"ignored": ["Timestamp"],
"mapping": {
"UserID": "id",
"MovieID": "id",
"Rating": "rate"
}
}
]
}
Note: modify the
input.pathto your local path.
4.2.1.1 Function Introduction
suitable for bipartite graph, will return all vertex or a list of its correlation which related to all source vertex.
Bipartite Graph is a special model in Graph Theory, as well as a special flow in network. The strongest feature is, it split all vertex in graph into two sets. The vertex in the set is not connected. However,the vertex in two sets may connect with each other.
Suppose we have one bipartite graph based on user and things. A random walk based PersonalRank algorithm should be likes this:
- Choose a user u as start vertex, let’s set the initial weight to be 1.0 . Go from Vu with probability alpha to a neighbor vertex, and (1-alpha) to stay.
- If we decide to go outside, we would like to choose an edge, such as
rating, to find a common judge.- Then choose the neighbors of current vertex randomly with uniform distribution, and reset the weights with uniform distribution.
- Compensate the source vertex’s weight with (1 - alpha)
- Repeat step 2;
- Convergence after reaching a certain number of steps or precision, then we got a recommend-list.
Params
Required:
- source: the id of source vertex
- label: edge label go from the source vertex, should connect two different type of vertex
Optional:
- alpha: the probability of going out for one vertex in each iteration,similar to the alpha of PageRank,required, value range is (0, 1], default 0.85.
- max_degree: in query process, the max iteration number of adjacency edge for a vertex, default
10000 - max_depth: iteration number,range [2, 50], default
5 - with_label:result filter,default
BOTH_LABEL,optional list as follows:- SAME_LABEL:Only keep vertex which has the same type as source vertex
- OTHER_LABEL:Only keep vertex which has different type as source vertex (the another part in bipartite graph)
- BOTH_LABEL:Keep both type vertex
- limit: max return vertex number,default
100 - max_diff: accuracy for convergence, default
0.0001(will implement soon) - sorted: whether sort the result by rank or not, true for descending sort, false for none, default
true
4.2.1.2 Usage
Method & Url
POST http://localhost:8080/graphspaces/DEFAULT/graphs/hugegraph/traversers/personalrank
Request Body
{
"source": "1:1",
"label": "rating",
"alpha": 0.6,
"max_depth": 15,
"with_label": "OTHER_LABEL",
"sorted": true,
"limit": 10
}
Response Status
200
Response Body
{
"2:2858": 0.0005014026017816927,
"2:1196": 0.0004336708357653617,
"2:1210": 0.0004128083140214213,
"2:593": 0.00038117341069881513,
"2:480": 0.00037005373269728036,
"2:1198": 0.000366641614652057,
"2:2396": 0.0003622362410538888,
"2:2571": 0.0003593312457300953,
"2:589": 0.00035922123055598566,
"2:110": 0.0003466135844390885
}
4.2.1.3 Suitable Scenario
In a bipartite graph build by two different type of vertex, recommend other most related vertex to one vertex. for example:
- Reading recommendation: find out the books should be recommended to someone first, It is also possible to recommend book pal with the highest common preferences at the same time (just like: WeChat “your friend also read xx " function)
- Social recommendation: find out other Poster who interested in same topics, or other News/Messages you may be interested with (Such as : “Hot News” function in Weibo)
- Commodity recommendation: according to someone’s shopping habit,find out a commodity list should recommend first, some online salesman may also be good (Such as : “You May Like” function in TaoBao)
4.2.2 Neighbor Rank API
4.2.2.0 Data Preparation
public class Loader {
public static void main(String[] args) {
HugeClient client = new HugeClient("http://127.0.0.1:8080", "hugegraph");
SchemaManager schema = client.schema();
schema.propertyKey("name").asText().ifNotExist().create();
schema.vertexLabel("person")
.properties("name")
.useCustomizeStringId()
.ifNotExist()
.create();
schema.vertexLabel("movie")
.properties("name")
.useCustomizeStringId()
.ifNotExist()
.create();
schema.edgeLabel("follow")
.sourceLabel("person")
.targetLabel("person")
.ifNotExist()
.create();
schema.edgeLabel("like")
.sourceLabel("person")
.targetLabel("movie")
.ifNotExist()
.create();
schema.edgeLabel("directedBy")
.sourceLabel("movie")
.targetLabel("person")
.ifNotExist()
.create();
GraphManager graph = client.graph();
Vertex O = graph.addVertex(T.label, "person", T.id, "O", "name", "O");
Vertex A = graph.addVertex(T.label, "person", T.id, "A", "name", "A");
Vertex B = graph.addVertex(T.label, "person", T.id, "B", "name", "B");
Vertex C = graph.addVertex(T.label, "person", T.id, "C", "name", "C");
Vertex D = graph.addVertex(T.label, "person", T.id, "D", "name", "D");
Vertex E = graph.addVertex(T.label, "movie", T.id, "E", "name", "E");
Vertex F = graph.addVertex(T.label, "movie", T.id, "F", "name", "F");
Vertex G = graph.addVertex(T.label, "movie", T.id, "G", "name", "G");
Vertex H = graph.addVertex(T.label, "movie", T.id, "H", "name", "H");
Vertex I = graph.addVertex(T.label, "movie", T.id, "I", "name", "I");
Vertex J = graph.addVertex(T.label, "movie", T.id, "J", "name", "J");
Vertex K = graph.addVertex(T.label, "person", T.id, "K", "name", "K");
Vertex L = graph.addVertex(T.label, "person", T.id, "L", "name", "L");
Vertex M = graph.addVertex(T.label, "person", T.id, "M", "name", "M");
O.addEdge("follow", A);
O.addEdge("follow", B);
O.addEdge("follow", C);
D.addEdge("follow", O);
A.addEdge("follow", B);
A.addEdge("like", E);
A.addEdge("like", F);
B.addEdge("like", G);
B.addEdge("like", H);
C.addEdge("like", I);
C.addEdge("like", J);
E.addEdge("directedBy", K);
F.addEdge("directedBy", B);
F.addEdge("directedBy", L);
G.addEdge("directedBy", M);
}
}
4.2.2.1 Function Introduction
In a general graph structure,find the first N vertices of each layer with the highest correlation with a given starting point and their relevance.
In graph words: to go out from the starting point, get the probability of going to each vertex of each layer.
Params
- source: id of source vertex,required
- alpha:the probability of going out for one vertex in each iteration,similar to the alpha of PageRank,required, value range is (0, 1]
- steps: a path rule for source vertex visited,it’s a list of Step,each Step map to a layout in result,required.The structure of each Step as follows:
- direction:the direction of edge(OUT, IN, BOTH), BOTH for default.
- labels:a list of edge types, will union all edge types
- max_degree:in query process, the max iteration number of adjacency edge for a vertex, default
10000(Note: before v0.12 step only support degree as parameter name, from v0.12, use max_degree, compatible with degree) - top: retains only the top N results with the highest weight in each layer of the results, default 100, max 1000
- capacity: the maximum number of vertexes visited during the traversal, optional, default 10000000
4.2.2.2 Usage
Method & Url
POST http://localhost:8080/graphspaces/DEFAULT/graphs/hugegraph/traversers/neighborrank
Request Body
{
"source":"O",
"steps":[
{
"direction":"OUT",
"labels":[
"follow"
],
"max_degree":-1,
"top":100
},
{
"direction":"OUT",
"labels":[
"follow",
"like"
],
"max_degree":-1,
"top":100
},
{
"direction":"OUT",
"labels":[
"directedBy"
],
"max_degree":-1,
"top":100
}
],
"alpha":0.9,
"capacity":-1
}
Response Status
200
Response Body
{
"ranks": [
{
"O": 1
},
{
"B": 0.4305,
"A": 0.3,
"C": 0.3
},
{
"G": 0.17550000000000002,
"H": 0.17550000000000002,
"I": 0.135,
"J": 0.135,
"E": 0.09000000000000001,
"F": 0.09000000000000001
},
{
"M": 0.15795,
"K": 0.08100000000000002,
"L": 0.04050000000000001
}
]
}
4.2.2.3 Suitable Scenario
Find the vertices in different layers for a given start point that should be most recommended
- For example, in the four-layered structure of the audience, friends, movies, and directors, according to the movies that a certain audience’s friends like, recommend movies for that audience, or recommend directors for those movies based on who made them.
1.12 - Variable API
5.1 Variables
Variables can be used to store data about the entire graph. The data is accessed and stored in the form of key-value pairs.
5.1.1 Creating or Updating a Key-Value Pair
Method & Url
PUT http://localhost:8080/graphspaces/DEFAULT/graphs/hugegraph/variables/name
Request Body
{
"data": "tom"
}
Response Status
200
Response Body
{
"name": "tom"
}
5.1.2 Listing all key-value pairs
Method & Url
GET http://localhost:8080/graphspaces/DEFAULT/graphs/hugegraph/variables
Response Status
200
Response Body
{
"name": "tom"
}
5.1.3 Listing a specific key-value pair
Method & Url
GET http://localhost:8080/graphspaces/DEFAULT/graphs/hugegraph/variables/name
Response Status
200
Response Body
{
"name": "tom"
}
5.1.4 Deleting a specific key-value pair
Method & Url
DELETE http://localhost:8080/graphspaces/DEFAULT/graphs/hugegraph/variables/name
Response Status
204
1.13 - Graphs API
6.1 Graphs
Important Reminder: Since HugeGraph 1.7.0, dynamic graph creation must enable authentication mode. For non-authentication mode, please refer to Graph Configuration File to statically create graphs through configuration files.
6.1.1 List all graphs in the graphspace
Params
Path parameters
- graphspace: Graphspace name
Method & Url
GET http://localhost:8080/graphspaces/DEFAULT/graphs
Response Status
200
Response Body
{
"graphs": [
"hugegraph",
"hugegraph1"
]
}
6.1.2 Get details of the graph
Params
Path parameters
- graphspace: Graphspace name
- graph: Graph name
Method & Url
GET http://localhost:8080/graphspaces/DEFAULT/graphs/hugegraph
Response Status
200
Response Body
{
"name": "hugegraph",
"backend": "cassandra"
}
6.1.3 Clear all data of a graph, include: schema, vertex, edge and index, This operation requires administrator privileges
Params
Path parameters
- graphspace: Graphspace name
- graph: Graph name
Query parameters
Since emptying the graph is a dangerous operation, we have added parameters for confirmation to the API to avoid false calls by users:
- confirm_message: default by
I'm sure to delete all data
Method & Url
DELETE http://localhost:8080/graphspaces/DEFAULT/graphs/hugegraph/clear?confirm_message=I%27m+sure+to+delete+all+data
Response Status
204
6.1.4 Clone graph, this operation requires administrator privileges
Params
Path parameters
- graphspace: Graphspace name
- graph: Name of the new graph to create
Query parameters
- clone_graph_name: name of an existed graph. To clone from an existing graph, the user can choose to transfer the configuration file, which will replace the configuration in the existing graph
Method & Url
POST http://localhost:8080/graphspaces/DEFAULT/graphs/cloneGraph?clone_graph_name=hugegraph
Request Body [Optional]
Clone a non-auth mode graph (set Content-Type: application/json)
{
"gremlin.graph": "org.apache.hugegraph.HugeFactory",
"backend": "rocksdb",
"serializer": "binary",
"store": "cloneGraph",
"rocksdb.data_path": "./rks-data-xx",
"rocksdb.wal_path": "./rks-data-xx"
}
Note:
- The data/wal_path can’t be the same as the existing graph (use separate directories)
- Replace “gremlin.graph=org.apache.hugegraph.auth.HugeFactoryAuthProxy” to enable auth mode
Response Status
200
Response Body
{
"name": "cloneGraph",
"backend": "rocksdb"
}
6.1.5 Create graph, this operation requires administrator privileges
Params
Path parameters
- graphspace: Graphspace name
- graph: Graph name
Method & Url
POST http://localhost:8080/graphspaces/DEFAULT/graphs/hugegraph2
Request Body
Create a graph (set Content-Type: application/json)
gremlin.graph Configuration:
- Auth mode:
"gremlin.graph": "org.apache.hugegraph.auth.HugeFactoryAuthProxy"(Recommended) - Non-auth mode:
"gremlin.graph": "org.apache.hugegraph.HugeFactory"
Note!!
- In version 1.7.0, dynamic graph creation would cause a NPE. This issue has been fixed in PR#2912. The current master version and versions after 1.7.0 do not have this problem.
- For version 1.7.0 and earlier, if the backend is hstore, you must add “task.scheduler_type”: “distributed” in the request body. Also ensure HugeGraph-Server is properly configured with PD, see HStore Configuration.
RocksDB Example:
{
"gremlin.graph": "org.apache.hugegraph.auth.HugeFactoryAuthProxy",
"backend": "rocksdb",
"serializer": "binary",
"store": "hugegraph2",
"rocksdb.data_path": "./rks-data-xx",
"rocksdb.wal_path": "./rks-data-xx"
}
HStore Example (for version 1.7.0 and earlier):
{
"gremlin.graph": "org.apache.hugegraph.auth.HugeFactoryAuthProxy",
"backend": "hstore",
"serializer": "binary",
"store": "hugegraph2",
"task.scheduler_type": "distributed",
"pd.peers": "127.0.0.1:8686"
}
Note: The data/wal_path can’t be the same as the existing graph (use separate directories)
Response Status
200
Response Body
{
"name": "hugegraph2",
"backend": "rocksdb"
}
6.1.6 Delete graph and its data
Params
Path parameters
- graphspace: Graphspace name
- graph: Graph name
Query parameters
Since deleting a graph is a dangerous operation, we have added parameters for confirmation to the API to avoid false calls by users:
- confirm_message: default by
I'm sure to drop the graph
Method & Url
DELETE http://localhost:8080/graphspaces/DEFAULT/graphs/graphA?confirm_message=I%27m%20sure%20to%20drop%20the%20graph
Response Status
204
Note: For HugeGraph 1.5.0 and earlier versions, if you need to create or drop a graph, please still use the legacy
text/plain(properties) style request body instead of JSON.
6.2 Conf
6.2.1 Get configuration for a graph, This operation requires administrator privileges
Params
Path parameters
- graphspace: Graphspace name
- graph: Graph name
Method & Url
GET http://localhost:8080/graphspaces/DEFAULT/graphs/hugegraph/conf
Response Status
200
Response Body
# gremlin entrence to create graph
gremlin.graph=org.apache.hugegraph.HugeFactory
# cache config
#schema.cache_capacity=1048576
#graph.cache_capacity=10485760
#graph.cache_expire=600
# schema illegal name template
#schema.illegal_name_regex=\s+|~.*
#vertex.default_label=vertex
backend=cassandra
serializer=cassandra
store=hugegraph
...=
6.3 Mode
Allowed graph mode values are: NONE, RESTORING, MERGING, LOADING
- None mode is regular mode
- Not allowed to create schema with specified id
- Not support creating vertex with id for AUTOMATIC id strategy
- LOADING mode used to load data via hugegraph-loader.
- When adding vertices / edges, it is not checked whether the required attributes are passed in
Restore has two different modes: Restoring and Merging
- Restoring mode is used to restore schema and graph data to a new graph.
- Support create schema with specified id
- Support create vertex with id for AUTOMATIC id strategy
- Merging mode is used to merge schema and graph data to an existing graph.
- Not allowed to create schema with specified id
- Support create vertex with id for AUTOMATIC id strategy
Under normal circumstances, the graph mode is None. When you need to restore the graph, you need to temporarily modify the graph mode to Restoring or Merging as needed. When you complete the restore, change the graph mode to None.
6.3.1 Get graph mode
Params
Path parameters
- graphspace: Graphspace name
- graph: Graph name
Method & Url
GET http://localhost:8080/graphspaces/DEFAULT/graphs/hugegraph/mode
Response Status
200
Response Body
{
"mode": "NONE"
}
Allowed graph mode values are: NONE, RESTORING, MERGING
6.3.2 Modify graph mode. This operation requires administrator privileges
Params
Path parameters
- graphspace: Graphspace name
- graph: Graph name
Method & Url
PUT http://localhost:8080/graphspaces/DEFAULT/graphs/hugegraph/mode
Request Body
"RESTORING"
Allowed graph mode values are: NONE, RESTORING, MERGING
Response Status
200
Response Body
{
"mode": "RESTORING"
}
6.3.3 Get graph’s read mode
Params
Path parameters
- graphspace: Graphspace name
- graph: Graph name
Method & Url
GET http://localhost:8080/graphspaces/DEFAULT/graphs/hugegraph/graph_read_mode
Response Status
200
Response Body
{
"graph_read_mode": "ALL"
}
6.3.4 Modify graph’s read mode. This operation requires administrator privileges
Params
Path parameters
- graphspace: Graphspace name
- graph: Graph name
Method & Url
PUT http://localhost:8080/graphspaces/DEFAULT/graphs/hugegraph/graph_read_mode
Request Body
"OLTP_ONLY"
Allowed read mode values are: ALL, OLTP_ONLY, OLAP_ONLY
Response Status
200
Response Body
{
"graph_read_mode": "OLTP_ONLY"
}
6.4 Snapshot
6.4.1 Create a snapshot
Params
Path parameters
- graphspace: Graphspace name
- graph: Graph name
Method & Url
PUT http://localhost:8080/graphspaces/DEFAULT/graphs/hugegraph/snapshot_create
Response Status
200
Response Body
{
"hugegraph": "snapshot_created"
}
6.4.2 Resume a snapshot
Params
Path parameters
- graphspace: Graphspace name
- graph: Graph name
Method & Url
PUT http://localhost:8080/graphspaces/DEFAULT/graphs/hugegraph/snapshot_resume
Response Status
200
Response Body
{
"hugegraph": "snapshot_resumed"
}
6.5 Compact
6.5.1 Manually compact graph, This operation requires administrator privileges
Params
Path parameters
- graphspace: Graphspace name
- graph: Graph name
Method & Url
PUT http://localhost:8080/graphspaces/DEFAULT/graphs/hugegraph/compact
Response Status
200
Response Body
{
"nodes": 1,
"cluster_id": "local",
"servers": {
"local": "OK"
}
}
1.14 - Task API
7.1 Task
7.1.1 List all async tasks in graph
Params
- status: the status of asyncTasks
- limit: the max number of tasks to return
Method & Url
GET http://localhost:8080/graphspaces/DEFAULT/graphs/hugegraph/tasks?status=success
Response Status
200
Response Body
{
"tasks": [{
"task_name": "hugegraph.traversal().V()",
"task_progress": 0,
"task_create": 1532943976585,
"task_status": "success",
"task_update": 1532943976736,
"task_result": "0",
"task_retries": 0,
"id": 2,
"task_type": "gremlin",
"task_callable": "org.apache.hugegraph.api.job.GremlinAPI$GremlinJob",
"task_input": "{\"gremlin\":\"hugegraph.traversal().V()\",\"bindings\":{},\"language\":\"gremlin-groovy\",\"aliases\":{\"hugegraph\":\"graph\"}}"
}]
}
7.1.2 View the details of an async task
Method & Url
GET http://localhost:8080/graphspaces/DEFAULT/graphs/hugegraph/tasks/2
Response Status
200
Response Body
{
"task_name": "hugegraph.traversal().V()",
"task_progress": 0,
"task_create": 1532943976585,
"task_status": "success",
"task_update": 1532943976736,
"task_result": "0",
"task_retries": 0,
"id": 2,
"task_type": "gremlin",
"task_callable": "org.apache.hugegraph.api.job.GremlinAPI$GremlinJob",
"task_input": "{\"gremlin\":\"hugegraph.traversal().V()\",\"bindings\":{},\"language\":\"gremlin-groovy\",\"aliases\":{\"hugegraph\":\"graph\"}}"
}
7.1.3 Delete task information of an async task,won’t delete the task itself
Method & Url
DELETE http://localhost:8080/graphspaces/DEFAULT/graphs/hugegraph/tasks/2
Response Status
204
7.1.4 Cancel an async task, the task should be able to be canceled
If you already created an async task via Gremlin API as follows:
"for (int i = 0; i < 10; i++) {" +
"hugegraph.addVertex(T.label, 'man');" +
"hugegraph.tx().commit();" +
"try {" +
"sleep(1000);" +
"} catch (InterruptedException e) {" +
"break;" +
"}" +
"}"
Method & Url
PUT http://localhost:8080/graphspaces/DEFAULT/graphs/hugegraph/tasks/2?action=cancel
cancel it in 10s. if more than 10s, the task may already be finished, then can’t be cancelled.
Response Status
202
Response Body
{
"cancelled": true
}
At this point, the number of vertices whose label is man must be less than 10.
1.15 - Gremlin API
8.1 Gremlin
⚠️ SEC Reminder: Safe Usage of Native Query Endpoints in Production Environments
The flexibility of Graph Query Languages (such as Gremlin/Cypher) inherently introduces certain potential security risks. To ensure core security, please avoid exposing any related native query endpoints directly to the public network. In production scenarios where internal exposure is required, you must enable the Authentication System (Auth) combined with an IP Whitelist as a dual-security mechanism to strictly control user execution permissions. Additionally, it is advised to use an Audit Log to audit the specific statements executed and to adopt Containerized Deployment (Docker/K8s) to enhance system-level security isolation.
8.1.1 Sending a gremlin statement (GET) to HugeGraphServer for synchronous execution
Params
- gremlin: The gremlin statement to be sent to
HugeGraphServerfor execution - bindings: Used to bind parameters. Key is a string, and the value is the bound value (can only be a string or number). This functionality is similar to MySQL’s Prepared Statement and is used to speed up statement execution.
- language: The language type of the sent statement. Default is
gremlin-groovy. - aliases: Adds aliases for existing variables in the graph space.
Querying vertices
Method & Url
GET http://127.0.0.1:8080/gremlin?gremlin=hugegraph.traversal().V('1:marko')
Response Status
200
Response Body
{
"requestId": "c6ef47a8-b634-4b07-9d38-6b3b69a3a556",
"status": {
"message": "",
"code": 200,
"attributes": {}
},
"result": {
"data": [{
"id": "1:marko",
"label": "person",
"type": "vertex",
"properties": {
"city": [{
"id": "1:marko>city",
"value": "Beijing"
}],
"name": [{
"id": "1:marko>name",
"value": "marko"
}],
"age": [{
"id": "1:marko>age",
"value": 29
}]
}
}],
"meta": {}
}
}
8.1.2 Sending a gremlin statement (POST) to HugeGraphServer for synchronous execution
Method & Url
POST http://localhost:8080/gremlin
Querying vertices
Request Body
{
"gremlin": "hugegraph.traversal().V('1:marko')",
"bindings": {},
"language": "gremlin-groovy",
"aliases": {}
}
Response Status
200
Response Body
{
"requestId": "c6ef47a8-b634-4b07-9d38-6b3b69a3a556",
"status": {
"message": "",
"code": 200,
"attributes": {}
},
"result": {
"data": [{
"id": "1:marko",
"label": "person",
"type": "vertex",
"properties": {
"city": [{
"id": "1:marko>city",
"value": "Beijing"
}],
"name": [{
"id": "1:marko>name",
"value": "marko"
}],
"age": [{
"id": "1:marko>age",
"value": 29
}]
}
}],
"meta": {}
}
}
Note:
Here we directly use the graph object (
hugegraph), first retrieve its traversal iterator (traversal()), and then retrieve the vertices. Instead of writinggraph.traversal().V()org.V(), you can use aliases to operate on the graph and traversal iterator. In this case,hugegraphis a native variable, and__g_hugegraphis an additional variable added by HugeGraphServer. Each graph will have a corresponding traversal iterator object in this format (__g_${graph}).
The structure of the response body is different from the RESTful API structure of other vertices or edges. Users may need to parse it manually.
Querying edges
Request Body
{
"gremlin": "g.E('S1:marko>2>>S2:lop')",
"bindings": {},
"language": "gremlin-groovy",
"aliases": {
"graph": "hugegraph",
"g": "__g_hugegraph"
}
}
Response Status
200
Response Body
{
"requestId": "3f117cd4-eedc-4e08-a106-ee01d7bb8249",
"status": {
"message": "",
"code": 200,
"attributes": {}
},
"result": {
"data": [{
"id": "S1:marko>2>>S2:lop",
"label": "created",
"type": "edge",
"inVLabel": "software",
"outVLabel": "person",
"inV": "2:lop",
"outV": "1:marko",
"properties": {
"weight": 0.4,
"date": "20171210"
}
}],
"meta": {}
}
}
8.1.3 Sending a gremlin statement (POST) to HugeGraphServer for asynchronous execution
Method & Url
POST http://localhost:8080/graphspaces/DEFAULT/graphs/hugegraph/jobs/gremlin
Querying vertices
Request Body
{
"gremlin": "g.V('1:marko')",
"bindings": {},
"language": "gremlin-groovy",
"aliases": {}
}
Note:
Asynchronous execution of Gremlin statements does not currently support aliases. You can use
graphto represent the graph you want to operate on, or directly use the name of the graph, such ashugegraph. Additionally,grepresents the traversal, which is equivalent tograph.traversal()orhugegraph.traversal().
Response Status
201
Response Body
{
"task_id": 1
}
Note:
You can query the execution status of an asynchronous task by using
GET http://localhost:8080/graphspaces/DEFAULT/graphs/hugegraph/tasks/1(where “1” is the task_id). For more information, refer to the Asynchronous Task RESTful API.
Querying edges
Request Body
{
"gremlin": "g.E('S1:marko>2>>S2:lop')",
"bindings": {},
"language": "gremlin-groovy",
"aliases": {}
}
Response Status
201
Response Body
{
"task_id": 2
}
Note:
You can query the execution status of an asynchronous task by using
GET http://localhost:8080/graphspaces/DEFAULT/graphs/hugegraph/tasks/2(where “2” is the task_id). For more information, refer to the Asynchronous Task RESTful API.
1.16 - Cypher API
9.1 Cypher
9.1.1 Sending a cypher statement (GET) to HugeGraphServer for synchronous execution
Method & Url
GET /graphspaces/{graphspace}/graphs/{graph}/cypher?cypher={cypher}
Params
Path parameters
- graphspace: Graphspace name
- graph: Graph name
Query parameters
- cypher: Cypher statement
Example
GET http://localhost:8080/graphspaces/DEFAULT/graphs/hugecypher1/cypher?cypher=match(n:person) return n.name as name order by n.name limit 1
Response Status
200
Response Body
{
"requestId": "766b9f48-2f10-40d9-951a-3027d0748ab7",
"status": {
"message": "",
"code": 200,
"attributes": {
}
},
"result": {
"data": [
{
"name": "hello"
}
],
"meta": {
}
}
}
9.1.2 Sending a cypher statement (POST) to HugeGraphServer for synchronous execution
Method & Url
POST /graphspaces/{graphspace}/graphs/{graph}/cypher
Params
Path parameters
- graphspace: Graphspace name
- graph: Graph name
Body
{cypher}
- cypher: Cypher statement
Note:
It is not in JSON format, but a plain text Cypher statement.
Example
POST http://localhost:8080/graphspaces/DEFAULT/graphs/hugecypher1/cypher
Request Body
match(n:person) return n.name as name order by n.name limit 1
Response Status
200
Response Body
{
"requestId": "f096bee0-e249-498f-b5a3-ea684fc84f57",
"status": {
"message": "",
"code": 200,
"attributes": {
}
},
"result": {
"data": [
{
"name": "hello"
}
],
"meta": {
}
}
}
1.17 - Authentication API
Version Change Notice:
- 1.7.0+: Auth API paths use GraphSpace format, such as
/graphspaces/DEFAULT/auth/users, and group/target IDs match their names (e.g.,admin)- 1.5.x and earlier: Auth API paths include graph name, and group/target IDs use format like
-69:grant. See HugeGraph 1.5.x RESTful API
10.1 User Authentication and Access Control
To enable authentication and related configurations, please refer to the Authentication Configuration documentation.
Overview of User Authentication and Access Control:
HugeGraph supports multi-user authentication and fine-grained access control. It adopts a 4-tier design based on “User-User Group-Operation-Resource” to flexibly control user roles and permissions. Resources describe data in the graph database, such as vertices that meet certain conditions. Each resource consists of three elements: type, label, and properties. There are a total of 18 types and combinations of any label and properties to form resources. The internal condition of a resource is an “AND” relationship, while the condition between multiple resources is an “OR” relationship. Users can belong to one or more user groups, and each user group can have permissions for any number of resources. The types of operations include read, write, delete, execute, etc. HugeGraph supports dynamically creating users, user groups, and resources, and supports dynamically assigning or revoking permissions. During the initialization of the database, a super administrator user is created, and subsequently, various role users can be created by the super administrator. If a newly created user is assigned sufficient permissions, they can create or manage more users.
Example:
user(name=boss) -belong-> group(name=all) -access(read)-> target(graph=graph1, resource={label: person, city: Beijing})
Description: User ‘boss’ has read permission for people in the ‘graph1’ graph from Beijing.
Interface Description:
The user authentication and access control interface includes 5 categories: UserAPI, GroupAPI, TargetAPI, BelongAPI, AccessAPI. Note Before 1.5.0, the format of ids such as group/target was similar to -69:grant. After 1.7.0, the id and name were consistent. Such as admin HugeGraph 1.5 x RESTful API
10.2 User (User) API
The user interface includes APIs for creating users, deleting users, modifying users, and querying user-related information.
10.2.1 Create User
Params
- user_name: User name
- user_password: User password
- user_phone: User phone number
- user_email: User email
Both user_name and user_password are required.
Request Body
{
"user_name": "boss",
"user_password": "******",
"user_phone": "182****9088",
"user_email": "123@xx.com"
}
Method & Url
POST http://localhost:8080/graphspaces/DEFAULT/auth/users
Response Status
201
Response Body
In the response message, the password is encrypted as ciphertext.
{
"user_password": "******",
"user_email": "123@xx.com",
"user_update": "2020-11-17 14:31:07.833",
"user_name": "boss",
"user_creator": "admin",
"user_phone": "182****9088",
"id": "boss",
"user_create": "2020-11-17 14:31:07.833"
}
10.2.2 Delete User
Params
- id: User ID to be deleted
Method & Url
DELETE http://localhost:8080/graphspaces/DEFAULT/auth/users/test
Response Status
204
Response Body
1
10.2.3 Modify User
Params
- id: User ID to be modified
Method & Url
PUT http://localhost:8080/graphspaces/DEFAULT/auth/users/test
Request Body
Modify user_name, user_password, and user_phone.
{
"user_name": "test",
"user_password": "******",
"user_phone": "183****9266"
}
Response Status
200
Response Body
The returned result is the entire user object including the modified content.
{
"user_password": "******",
"user_update": "2020-11-12 10:29:30.455",
"user_name": "test",
"user_creator": "admin",
"user_phone": "183****9266",
"id": "test",
"user_create": "2020-11-12 10:27:13.601"
}
10.2.4 Query User List
Params
- limit: Upper limit of the number of results returned
Method & Url
GET http://localhost:8080/graphspaces/DEFAULT/auth/users
Response Status
200
Response Body
{
"users": [
{
"user_password": "******",
"user_update": "2020-11-11 11:41:12.254",
"user_name": "admin",
"user_creator": "system",
"id": "admin",
"user_create": "2020-11-11 11:41:12.254"
}
]
}
10.2.5 Query a User
Params
- id: User ID to be queried
Method & Url
GET http://localhost:8080/graphspaces/DEFAULT/auth/users/admin
Response Status
200
Response Body
{
"users": [
{
"user_password": "******",
"user_update": "2020-11-11 11:41:12.254",
"user_name": "admin",
"user_creator": "system",
"id": "admin",
"user_create": "2020-11-11 11:41:12.254"
}
]
}
10.2.6 Query Roles of a User
Method & Url
GET http://localhost:8080/graphspaces/DEFAULT/auth/users/boss/role
Response Status
200
Response Body
{
"roles": {
"hugegraph": {
"READ": [
{
"type": "ALL",
"label": "*",
"properties": null
}
]
}
}
}
10.3 Group (Group) API
Groups grant corresponding resource permissions, and users are assigned to different groups, thereby having different resource permissions. The group interface includes APIs for creating groups, deleting groups, modifying groups, and querying group-related information.
10.3.1 Create Group
Params
- group_name: Group name
- group_description: Group description
Request Body
{
"group_name": "all",
"group_description": "group can do anything"
}
Method & Url
POST http://localhost:8080/graphspaces/DEFAULT/auth/groups
Response Status
201
Response Body
{
"group_creator": "admin",
"group_name": "all",
"group_create": "2020-11-11 15:46:08.791",
"group_update": "2020-11-11 15:46:08.791",
"id": "-69:all",
"group_description": "group can do anything"
}
10.3.2 Delete Group
Params
- id: Group ID to be deleted
Method & Url
DELETE http://localhost:8080/graphspaces/DEFAULT/auth/groups/-69:grant
Response Status
204
Response Body
1
10.3.3 Modify Group
Params
- id: Group ID to be modified
Method & Url
PUT http://localhost:8080/graphspaces/DEFAULT/auth/groups/-69:grant
Request Body
Modify group_description
{
"group_name": "grant",
"group_description": "grant"
}
Response Status
200
Response Body
The returned result is the entire group object including the modified content.
{
"group_creator": "admin",
"group_name": "grant",
"group_create": "2020-11-12 09:50:58.458",
"group_update": "2020-11-12 09:57:58.155",
"id": "-69:grant",
"group_description": "grant"
}
10.3.4 Query Group List
Params
- limit: Upper limit of the number of results returned
Method & Url
GET http://localhost:8080/graphspaces/DEFAULT/auth/groups
Response Status
200
Response Body
{
"groups": [
{
"group_creator": "admin",
"group_name": "all",
"group_create": "2020-11-11 15:46:08.791",
"group_update": "2020-11-11 15:46:08.791",
"id": "-69:all",
"group_description": "group can do anything"
}
]
}
10.3.5 Query a Specific Group
Params
- id: Group ID to be queried
Method & Url
GET http://localhost:8080/graphspaces/DEFAULT/auth/groups/-69:all
Response Status
200
Response Body
{
"group_creator": "admin",
"group_name": "all",
"group_create": "2020-11-11 15:46:08.791",
"group_update": "2020-11-11 15:46:08.791",
"id": "-69:all",
"group_description": "group can do anything"
}
10.4 Resource (Target) API
Resources describe data in the graph database, such as vertices that meet certain criteria. Each resource includes three elements: type, label, and properties. There are 18 types in total, and the combination of any label and any properties forms a resource. The internal conditions of a resource are based on the AND relationship, while the conditions between multiple resources are based on the OR relationship.
The resource API includes creating, deleting, modifying, and querying resources.
10.4.1 Create Resource
Params
- target_name: Name of the resource
- target_graph: Graph of the resource
- target_url: URL of the resource
- target_resources: Resource definitions (list)
target_resources can include multiple target_resource, stored in the form of a list.
Each target_resource contains:
- type: Optional value: VERTEX, EDGE, etc. Can be filled with ALL, indicating it can be a vertex or edge.
- label: Optional value: name of a vertex or edge type. Can be filled with *, indicating any type.
- properties: Map type, can contain multiple key-value pairs of properties. Must match all property values. Property values can support conditional ranges (e.g., age: P.gte(18)). If properties are null, it means any property is allowed. If both the property name and value are ‘*’, it also means any property is allowed.
For example, a specific resource: “target_resources”: [{“type”:“VERTEX”,“label”:“person”,“properties”:{“city”:“Beijing”,“age”:“P.gte(20)”}}]
The resource definition means: a vertex of type ‘person’ with the city property set to ‘Beijing’ and the age property greater than or equal to 20.
Request Body
{
"target_name": "all",
"target_graph": "hugegraph",
"target_url": "127.0.0.1:8080",
"target_resources": [
{
"type": "ALL"
}
]
}
Method & Url
POST http://localhost:8080/graphspaces/DEFAULT/auth/targets
Response Status
201
Response Body
{
"target_creator": "admin",
"target_name": "all",
"target_url": "127.0.0.1:8080",
"target_graph": "hugegraph",
"target_create": "2020-11-11 15:32:01.192",
"target_resources": [
{
"type": "ALL",
"label": "*",
"properties": null
}
],
"id": "-77:all",
"target_update": "2020-11-11 15:32:01.192"
}
10.4.2 Delete Resource
Params
- id: Resource Id to be deleted
Method & Url
DELETE http://localhost:8080/graphspaces/DEFAULT/auth/targets/-77:gremlin
Response Status
204
Response Body
1
10.4.3 Modify Resource
Params
- id: Resource Id to be modified
Method & Url
PUT http://localhost:8080/graphspaces/DEFAULT/auth/targets/-77:gremlin
Request Body
Modify the ’type’ in the resource definition.
{
"target_name": "gremlin",
"target_graph": "hugegraph",
"target_url": "127.0.0.1:8080",
"target_resources": [
{
"type": "NONE"
}
]
}
Response Status
200
Response Body
The response contains the entire target group object, including the modified content.
{
"target_creator": "admin",
"target_name": "gremlin",
"target_url": "127.0.0.1:8080",
"target_graph": "hugegraph",
"target_create": "2020-11-12 09:34:13.848",
"target_resources": [
{
"type": "NONE",
"label": "*",
"properties": null
}
],
"id": "-77:gremlin",
"target_update": "2020-11-12 09:37:12.780"
}
10.4.4 Query Resource List
Params
- limit: Upper limit of the number of returned results.
Method & Url
GET http://localhost:8080/graphspaces/DEFAULT/auth/targets
Response Status
200
Response Body
{
"targets": [
{
"target_creator": "admin",
"target_name": "all",
"target_url": "127.0.0.1:8080",
"target_graph": "hugegraph",
"target_create": "2020-11-11 15:32:01.192",
"target_resources": [
{
"type": "ALL",
"label": "*",
"properties": null
}
],
"id": "-77:all",
"target_update": "2020-11-11 15:32:01.192"
},
{
"target_creator": "admin",
"target_name": "grant",
"target_url": "127.0.0.1:8080",
"target_graph": "hugegraph",
"target_create": "2020-11-11 15:43:24.841",
"target_resources": [
{
"type": "GRANT",
"label": "*",
"properties": null
}
],
"id": "-77:grant",
"target_update": "2020-11-11 15:43:24.841"
}
]
}
10.4.5 Query a Specific Resource
Params
- id: Id of the resource to query
Method & Url
GET http://localhost:8080/graphspaces/DEFAULT/auth/targets/-77:grant
Response Status
200
Response Body
{
"target_creator": "admin",
"target_name": "grant",
"target_url": "127.0.0.1:8080",
"target_graph": "hugegraph",
"target_create": "2020-11-11 15:43:24.841",
"target_resources": [
{
"type": "GRANT",
"label": "*",
"properties": null
}
],
"id": "-77:grant",
"target_update": "2020-11-11 15:43:24.841"
}
10.5 Association of Roles (Belong) API
The association between users and user groups allows a user to be associated with one or more user groups. User groups have permissions for related resources, and the permissions for different user groups can be understood as different roles. In other words, users are associated with roles.
The API for associating roles includes creating, deleting, modifying, and querying the association of roles for users.
10.5.1 Create an Association of Roles for a User
Params
- user: User ID
- group: User group ID
- belong_description: Description
Request Body
{
"user": "boss",
"group": "-69:all"
}
Method & Url
POST http://localhost:8080/graphspaces/DEFAULT/auth/belongs
Response Status
201
Response Body
{
"belong_create": "2020-11-11 16:19:35.422",
"belong_creator": "admin",
"belong_update": "2020-11-11 16:19:35.422",
"id": "Sboss>-82>>S-69:all",
"user": "boss",
"group": "-69:all"
}
10.5.2 Delete an Association of Roles
Params
- id: ID of the association of roles to delete
Method & Url
DELETE http://localhost:8080/graphspaces/DEFAULT/auth/belongs/Sboss>-82>>S-69:grant
Response Status
204
Response Body
1
10.5.3 Modify an Association of Roles
An association of roles can only be modified for its description. The user and group properties cannot be modified. If you need to modify an association of roles, you need to delete the existing association and create a new one.
Params
- id: ID of the association of roles to modify
Method & Url
PUT http://localhost:8080/graphspaces/DEFAULT/auth/belongs/Sboss>-82>>S-69:grant
Request Body
Modify the belong_description field
{
"belong_description": "update test"
}
Response Status
200
Response Body
The response includes the modified content as well as the entire association of roles object
{
"belong_description": "update test",
"belong_create": "2020-11-12 10:40:21.720",
"belong_creator": "admin",
"belong_update": "2020-11-12 10:42:47.265",
"id": "Sboss>-82>>S-69:grant",
"user": "boss",
"group": "-69:grant"
}
10.5.4 Query List of Associations of Roles
Params
- limit: Upper limit on the number of results to return
Method & Url
GET http://localhost:8080/graphspaces/DEFAULT/auth/belongs
Response Status
200
Response Body
{
"belongs": [
{
"belong_create": "2020-11-11 16:19:35.422",
"belong_creator": "admin",
"belong_update": "2020-11-11 16:19:35.422",
"id": "Sboss>-82>>S-69:all",
"user": "boss",
"group": "-69:all"
}
]
}
10.5.5 View a Specific Association of Roles
Params
- id: The id of the association of roles to be queried
Method & Url
GET http://localhost:8080/graphspaces/DEFAULT/auth/belongs/Sboss>-82>>S-69:all
Response Status
200
Response Body
{
"belong_create": "2020-11-11 16:19:35.422",
"belong_creator": "admin",
"belong_update": "2020-11-11 16:19:35.422",
"id": "Sboss>-82>>S-69:all",
"user": "boss",
"group": "-69:all"
}
10.6 Authorization (Access) API
Grant permissions to user groups for resources, including operations such as READ, WRITE, DELETE, EXECUTE, etc. The authorization API includes: creating, deleting, modifying, and querying permissions.
10.6.1 Create Authorization (Granting permissions to user groups for resources)
Params
- group: Group ID
- target: Resource ID
- access_permission: Permission grant
- access_description: Authorization description
Access permissions:
- READ: Read operations, including all queries such as querying the schema, retrieving vertices/edges, aggregating vertex and edge counts (VERTEX_AGGR/EDGE_AGGR), and reading the graph’s status (STATUS), variables (VAR), tasks (TASK), etc.
- WRITE: Write operations, including creating and updating operations, such as adding property keys to the schema or adding/updating properties of vertices.
- DELETE: Delete operations, including deleting metadata, vertices, or edges.
- EXECUTE: Execute operations, including executing Gremlin queries, executing tasks, and executing metadata functions.
Request Body
{
"group": "-69:all",
"target": "-77:all",
"access_permission": "READ"
}
Method & Url
POST http://localhost:8080/graphspaces/DEFAULT/auth/accesses
Response Status
201
Response Body
{
"access_permission": "READ",
"access_create": "2020-11-11 15:54:54.008",
"id": "S-69:all>-88>11>S-77:all",
"access_update": "2020-11-11 15:54:54.008",
"access_creator": "admin",
"group": "-69:all",
"target": "-77:all"
}
10.6.2 Delete Authorization
Params
- id: The ID of the authorization to be deleted
Method & Url
DELETE http://localhost:8080/graphspaces/DEFAULT/auth/accesses/S-69:all>-88>12>S-77:all
Response Status
204
Response Body
1
10.6.3 Modify Authorization
Authorization can only be modified for its description. User group, resource, and permission cannot be modified. If you need to modify the authorization relationship, delete the original authorization and create a new one.
Params
- id: The ID of the authorization to be modified
Method & Url
PUT http://localhost:8080/graphspaces/DEFAULT/auth/accesses/S-69:all>-88>12>S-77:all
Request Body
Modify access_description
{
"access_description": "test"
}
Response Status
200
Response Body
The response includes the modified content as well as the entire authorization object.
{
"access_description": "test",
"access_permission": "WRITE",
"access_create": "2020-11-12 10:12:03.074",
"id": "S-69:all>-88>12>S-77:all",
"access_update": "2020-11-12 10:16:18.637",
"access_creator": "admin",
"group": "-69:all",
"target": "-77:all"
}
10.6.4 Query Authorization List
Params
- limit: The maximum number of results to return
Method & Url
GET http://localhost:8080/graphspaces/DEFAULT/auth/accesses
Response Status
200
Response Body
{
"accesses": [
{
"access_permission": "READ",
"access_create": "2020-11-11 15:54:54.008",
"id": "S-69:all>-88>11>S-77:all",
"access_update": "2020-11-11 15:54:54.008",
"access_creator": "admin",
"group": "-69:all",
"target": "-77:all"
}
]
}
10.6.5 Query a Specific Authorization
Params
- id: The ID of the authorization to be queried
Method & Url
GET http://localhost:8080/graphspaces/DEFAULT/auth/accesses/S-69:all>-88>11>S-77:all
Response Status
200
Response Body
{
"access_permission": "READ",
"access_create": "2020-11-11 15:54:54.008",
"id": "S-69:all>-88>11>S-77:all",
"access_update": "2020-11-11 15:54:54.008",
"access_creator": "admin",
"group": "-69:all",
"target": "-77:all"
}
10.7 Graphspace Manager (Manager) API
Note: Before using the following APIs, you need to create a graphspace first. For example, create a graphspace named
gs1via the Graphspace API. The examples below assume thatgs1already exists.
- The graphspace manager API is used to grant/revoke manager roles for users at the graphspace level, and to query the roles of the current user or other users in a graphspace. Supported role types include
SPACE,SPACE_MEMBER, andADMIN.
10.7.1 Check whether the current login user has a specific role
Params
- type: Role type to check, optional
Method & Url
GET http://localhost:8080/graphspaces/gs1/auth/managers/check?type=WRITE
Response Status
200
Response Body
"true"
The API returns the string true or false indicating whether the current user has the given role.
10.7.2 List graphspace managers
Params
- type: Role type, optional, used to filter by role
Method & Url
GET http://localhost:8080/graphspaces/gs1/auth/managers?type=SPACE
Response Status
200
Response Body
{
"managers": [
{
"user": "admin",
"type": "SPACE",
"create_time": "2024-01-10 09:30:00"
}
]
}
10.7.3 Grant/create a graphspace manager
- The following example grants user
bosstheSPACE_MEMBERrole in graphspacegs1.
Request Body
{
"user": "boss",
"type": "SPACE_MEMBER"
}
Method & Url
POST http://localhost:8080/graphspaces/gs1/auth/managers
Response Status
201
Response Body
{
"user": "boss",
"type": "SPACE_MEMBER",
"manager_creator": "admin",
"manager_create": "2024-01-10 09:45:12"
}
10.7.4 Revoke graphspace manager privileges
- The following example revokes the
SPACE_MEMBERrole of userbossin graphspacegs1.
Params
- user: User ID to revoke
- type: Role type to revoke
Method & Url
DELETE http://localhost:8080/graphspaces/gs1/auth/managers?user=boss&type=SPACE_MEMBER
Response Status
204
Response Body
1
10.7.5 Query roles of a specific user in a graphspace
Params
- user: User ID
Method & Url
GET http://localhost:8080/graphspaces/gs1/auth/managers/role?user=boss
Response Status
200
Response Body
{
"roles": {
"boss": [
"READ",
"SPACE_MEMBER"
]
}
}
1.18 - Metrics API
HugeGraph provides a metrics interface for obtaining monitoring information, such as statistics on each Gremlin execution time, cache size, etc. The metrics interface includes the following categories: basic metrics, statistical metrics, system metrics, and backend storage metrics.
1. Basic Metrics
1.1 Get All Basic Metrics
Params
- type: If the passed value is
json, it is returned in json format, otherwise it is returned in Promethaus format.
1.1.1 Method & Url
http://localhost:8080/metrics/?type=json
Response Status
200
Response Body
{
"gauges": {
"org.apache.hugegraph.backend.cache.Cache.edge-hugegraph.capacity": {
"value": 1000000
},
"org.apache.hugegraph.backend.cache.Cache.edge-hugegraph.expire": {
"value": 600000
},
"org.apache.hugegraph.backend.cache.Cache.edge-hugegraph.hits": {
"value": 0
},
"org.apache.hugegraph.backend.cache.Cache.edge-hugegraph.miss": {
"value": 0
},
"org.apache.hugegraph.backend.cache.Cache.edge-hugegraph.size": {
"value": 0
},
"org.apache.hugegraph.backend.cache.Cache.instances": {
"value": 7
},
"org.apache.hugegraph.backend.cache.Cache.schema-id-hugegraph.capacity": {
"value": 10000
},
"org.apache.hugegraph.backend.cache.Cache.schema-id-hugegraph.expire": {
"value": 0
},
"org.apache.hugegraph.backend.cache.Cache.schema-id-hugegraph.hits": {
"value": 0
},
"org.apache.hugegraph.backend.cache.Cache.schema-id-hugegraph.miss": {
"value": 0
},
"org.apache.hugegraph.backend.cache.Cache.schema-id-hugegraph.size": {
"value": 17
},
"org.apache.hugegraph.backend.cache.Cache.schema-name-hugegraph.capacity": {
"value": 10000
},
"org.apache.hugegraph.backend.cache.Cache.schema-name-hugegraph.expire": {
"value": 0
},
"org.apache.hugegraph.backend.cache.Cache.schema-name-hugegraph.hits": {
"value": 0
},
"org.apache.hugegraph.backend.cache.Cache.schema-name-hugegraph.miss": {
"value": 0
},
"org.apache.hugegraph.backend.cache.Cache.schema-name-hugegraph.size": {
"value": 17
},
"org.apache.hugegraph.backend.cache.Cache.token-hugegraph.capacity": {
"value": 10240
},
"org.apache.hugegraph.backend.cache.Cache.token-hugegraph.expire": {
"value": 600000
},
"org.apache.hugegraph.backend.cache.Cache.token-hugegraph.hits": {
"value": 0
},
"org.apache.hugegraph.backend.cache.Cache.token-hugegraph.miss": {
"value": 0
},
"org.apache.hugegraph.backend.cache.Cache.token-hugegraph.size": {
"value": 0
},
"org.apache.hugegraph.backend.cache.Cache.users-hugegraph.capacity": {
"value": 10240
},
"org.apache.hugegraph.backend.cache.Cache.users-hugegraph.expire": {
"value": 600000
},
"org.apache.hugegraph.backend.cache.Cache.users-hugegraph.hits": {
"value": 0
},
"org.apache.hugegraph.backend.cache.Cache.users-hugegraph.miss": {
"value": 0
},
"org.apache.hugegraph.backend.cache.Cache.users-hugegraph.size": {
"value": 0
},
"org.apache.hugegraph.backend.cache.Cache.users_pwd-hugegraph.capacity": {
"value": 10240
},
"org.apache.hugegraph.backend.cache.Cache.users_pwd-hugegraph.expire": {
"value": 600000
},
"org.apache.hugegraph.backend.cache.Cache.users_pwd-hugegraph.hits": {
"value": 0
},
"org.apache.hugegraph.backend.cache.Cache.users_pwd-hugegraph.miss": {
"value": 0
},
"org.apache.hugegraph.backend.cache.Cache.users_pwd-hugegraph.size": {
"value": 0
},
"org.apache.hugegraph.backend.cache.Cache.vertex-hugegraph.capacity": {
"value": 10000000
},
"org.apache.hugegraph.backend.cache.Cache.vertex-hugegraph.expire": {
"value": 600000
},
"org.apache.hugegraph.backend.cache.Cache.vertex-hugegraph.hits": {
"value": 0
},
"org.apache.hugegraph.backend.cache.Cache.vertex-hugegraph.miss": {
"value": 0
},
"org.apache.hugegraph.backend.cache.Cache.vertex-hugegraph.size": {
"value": 0
},
"org.apache.hugegraph.server.RestServer.max-write-threads": {
"value": 0
},
"org.apache.hugegraph.task.TaskManager.pending-tasks": {
"value": 0
},
"org.apache.hugegraph.task.TaskManager.workers": {
"value": 4
},
"org.apache.tinkerpop.gremlin.server.GremlinServer.gremlin-groovy.sessionless.class-cache.average-load-penalty": {
"value": 922769200
},
"org.apache.tinkerpop.gremlin.server.GremlinServer.gremlin-groovy.sessionless.class-cache.estimated-size": {
"value": 2
},
"org.apache.tinkerpop.gremlin.server.GremlinServer.gremlin-groovy.sessionless.class-cache.eviction-count": {
"value": 0
},
"org.apache.tinkerpop.gremlin.server.GremlinServer.gremlin-groovy.sessionless.class-cache.eviction-weight": {
"value": 0
},
"org.apache.tinkerpop.gremlin.server.GremlinServer.gremlin-groovy.sessionless.class-cache.hit-count": {
"value": 0
},
"org.apache.tinkerpop.gremlin.server.GremlinServer.gremlin-groovy.sessionless.class-cache.hit-rate": {
"value": 0
},
"org.apache.tinkerpop.gremlin.server.GremlinServer.gremlin-groovy.sessionless.class-cache.load-count": {
"value": 2
},
"org.apache.tinkerpop.gremlin.server.GremlinServer.gremlin-groovy.sessionless.class-cache.load-failure-count": {
"value": 0
},
"org.apache.tinkerpop.gremlin.server.GremlinServer.gremlin-groovy.sessionless.class-cache.load-failure-rate": {
"value": 0
},
"org.apache.tinkerpop.gremlin.server.GremlinServer.gremlin-groovy.sessionless.class-cache.load-success-count": {
"value": 2
},
"org.apache.tinkerpop.gremlin.server.GremlinServer.gremlin-groovy.sessionless.class-cache.long-run-compilation-count": {
"value": 0
},
"org.apache.tinkerpop.gremlin.server.GremlinServer.gremlin-groovy.sessionless.class-cache.miss-count": {
"value": 2
},
"org.apache.tinkerpop.gremlin.server.GremlinServer.gremlin-groovy.sessionless.class-cache.miss-rate": {
"value": 1
},
"org.apache.tinkerpop.gremlin.server.GremlinServer.gremlin-groovy.sessionless.class-cache.request-count": {
"value": 2
},
"org.apache.tinkerpop.gremlin.server.GremlinServer.gremlin-groovy.sessionless.class-cache.total-load-time": {
"value": 1845538400
},
"org.apache.tinkerpop.gremlin.server.GremlinServer.sessions": {
"value": 0
}
},
"counters": {
"favicon.ico/GET/FAILED_COUNTER": {
"count": 1
},
"favicon.ico/GET/TOTAL_COUNTER": {
"count": 1
},
"metrics/POST/FAILED_COUNTER": {
"count": 1
},
"metrics/POST/TOTAL_COUNTER": {
"count": 1
},
"metrics/backend/GET/SUCCESS_COUNTER": {
"count": 2
},
"metrics/backend/GET/TOTAL_COUNTER": {
"count": 2
},
"metrics/gauges/GET/SUCCESS_COUNTER": {
"count": 1
},
"metrics/gauges/GET/TOTAL_COUNTER": {
"count": 1
},
"metrics/system/GET/SUCCESS_COUNTER": {
"count": 2
},
"metrics/system/GET/TOTAL_COUNTER": {
"count": 2
},
"system/GET/FAILED_COUNTER": {
"count": 1
},
"system/GET/TOTAL_COUNTER": {
"count": 1
}
},
"histograms": {
"favicon.ico/GET/RESPONSE_TIME_HISTOGRAM": {
"count": 1,
"min": 1,
"mean": 1,
"max": 1,
"stddev": 0,
"p50": 1,
"p75": 1,
"p95": 1,
"p98": 1,
"p99": 1,
"p999": 1
},
"metrics/POST/RESPONSE_TIME_HISTOGRAM": {
"count": 1,
"min": 21,
"mean": 21,
"max": 21,
"stddev": 0,
"p50": 21,
"p75": 21,
"p95": 21,
"p98": 21,
"p99": 21,
"p999": 21
},
"metrics/backend/GET/RESPONSE_TIME_HISTOGRAM": {
"count": 2,
"min": 6,
"mean": 12.6852124529148,
"max": 20,
"stddev": 6.992918475157571,
"p50": 6,
"p75": 20,
"p95": 20,
"p98": 20,
"p99": 20,
"p999": 20
},
"metrics/gauges/GET/RESPONSE_TIME_HISTOGRAM": {
"count": 1,
"min": 7,
"mean": 7,
"max": 7,
"stddev": 0,
"p50": 7,
"p75": 7,
"p95": 7,
"p98": 7,
"p99": 7,
"p999": 7
},
"metrics/system/GET/RESPONSE_TIME_HISTOGRAM": {
"count": 2,
"min": 0,
"mean": 8.942674506664073,
"max": 40,
"stddev": 16.665399873223066,
"p50": 0,
"p75": 0,
"p95": 40,
"p98": 40,
"p99": 40,
"p999": 40
},
"system/GET/RESPONSE_TIME_HISTOGRAM": {
"count": 1,
"min": 2,
"mean": 2,
"max": 2,
"stddev": 0,
"p50": 2,
"p75": 2,
"p95": 2,
"p98": 2,
"p99": 2,
"p999": 2
}
},
"meters": {
"org.apache.hugegraph.api.API.commit-succeed": {
"count": 0,
"mean_rate": 0,
"m15_rate": 0,
"m5_rate": 0,
"m1_rate": 0,
"rate_unit": "events/second"
},
"org.apache.hugegraph.api.API.expected-error": {
"count": 0,
"mean_rate": 0,
"m15_rate": 0,
"m5_rate": 0,
"m1_rate": 0,
"rate_unit": "events/second"
},
"org.apache.hugegraph.api.API.illegal-arg": {
"count": 0,
"mean_rate": 0,
"m15_rate": 0,
"m5_rate": 0,
"m1_rate": 0,
"rate_unit": "events/second"
},
"org.apache.hugegraph.api.API.unknown-error": {
"count": 0,
"mean_rate": 0,
"m15_rate": 0,
"m5_rate": 0,
"m1_rate": 0,
"rate_unit": "events/second"
},
"org.apache.tinkerpop.gremlin.server.GremlinServer.errors": {
"count": 0,
"mean_rate": 0,
"m15_rate": 0,
"m5_rate": 0,
"m1_rate": 0,
"rate_unit": "events/second"
}
},
"timers": {
"org.apache.hugegraph.api.auth.AccessAPI.create": {
"count": 0,
"min": 0,
"mean": 0,
"max": 0,
"stddev": 0,
"p50": 0,
"p75": 0,
"p95": 0,
"p98": 0,
"p99": 0,
"p999": 0,
"duration_unit": "milliseconds",
"mean_rate": 0,
"m15_rate": 0,
"m5_rate": 0,
"m1_rate": 0,
"rate_unit": "calls/second"
},
"org.apache.hugegraph.api.auth.AccessAPI.delete": {
"count": 0,
"min": 0,
"mean": 0,
"max": 0,
"stddev": 0,
"p50": 0,
"p75": 0,
"p95": 0,
"p98": 0,
"p99": 0,
"p999": 0,
"duration_unit": "milliseconds",
"mean_rate": 0,
"m15_rate": 0,
"m5_rate": 0,
"m1_rate": 0,
"rate_unit": "calls/second"
},
"org.apache.hugegraph.api.auth.AccessAPI.get": {
"count": 0,
"min": 0,
"mean": 0,
"max": 0,
"stddev": 0,
"p50": 0,
"p75": 0,
"p95": 0,
"p98": 0,
"p99": 0,
"p999": 0,
"duration_unit": "milliseconds",
"mean_rate": 0,
"m15_rate": 0,
"m5_rate": 0,
"m1_rate": 0,
"rate_unit": "calls/second"
},
"org.apache.hugegraph.api.auth.AccessAPI.list": {
"count": 0,
"min": 0,
"mean": 0,
"max": 0,
"stddev": 0,
"p50": 0,
"p75": 0,
"p95": 0,
"p98": 0,
"p99": 0,
"p999": 0,
"duration_unit": "milliseconds",
"mean_rate": 0,
"m15_rate": 0,
"m5_rate": 0,
"m1_rate": 0,
"rate_unit": "calls/second"
},
...
}
}
1.1.2 Method & Url
http://localhost:8080/metrics/
Response Status
200
Response Body
# HELP hugegraph_info
# TYPE hugegraph_info untyped
hugegraph_info{version="0.69",
} 1.0
# HELP org_apache_hugegraph_backend_cache_Cache_edge_hugegraph_capacity
# TYPE org_apache_hugegraph_backend_cache_Cache_edge_hugegraph_capacity gauge
org_apache_hugegraph_backend_cache_Cache_edge_hugegraph_capacity 1000000
# HELP org_apache_hugegraph_backend_cache_Cache_edge_hugegraph_expire
# TYPE org_apache_hugegraph_backend_cache_Cache_edge_hugegraph_expire gauge
org_apache_hugegraph_backend_cache_Cache_edge_hugegraph_expire 600000
# HELP org_apache_hugegraph_backend_cache_Cache_edge_hugegraph_hits
# TYPE org_apache_hugegraph_backend_cache_Cache_edge_hugegraph_hits gauge
org_apache_hugegraph_backend_cache_Cache_edge_hugegraph_hits 0
# HELP org_apache_hugegraph_backend_cache_Cache_edge_hugegraph_miss
# TYPE org_apache_hugegraph_backend_cache_Cache_edge_hugegraph_miss gauge
org_apache_hugegraph_backend_cache_Cache_edge_hugegraph_miss 0
# HELP org_apache_hugegraph_backend_cache_Cache_edge_hugegraph_size
# TYPE org_apache_hugegraph_backend_cache_Cache_edge_hugegraph_size gauge
org_apache_hugegraph_backend_cache_Cache_edge_hugegraph_size 0
# HELP org_apache_hugegraph_backend_cache_Cache_instances
# TYPE org_apache_hugegraph_backend_cache_Cache_instances gauge
org_apache_hugegraph_backend_cache_Cache_instances 7
# HELP org_apache_hugegraph_backend_cache_Cache_schema_id_hugegraph_capacity
# TYPE org_apache_hugegraph_backend_cache_Cache_schema_id_hugegraph_capacity gauge
org_apache_hugegraph_backend_cache_Cache_schema_id_hugegraph_capacity 10000
# HELP org_apache_hugegraph_backend_cache_Cache_schema_id_hugegraph_expire
# TYPE org_apache_hugegraph_backend_cache_Cache_schema_id_hugegraph_expire gauge
org_apache_hugegraph_backend_cache_Cache_schema_id_hugegraph_expire 0
# HELP org_apache_hugegraph_backend_cache_Cache_schema_id_hugegraph_hits
# TYPE org_apache_hugegraph_backend_cache_Cache_schema_id_hugegraph_hits gauge
org_apache_hugegraph_backend_cache_Cache_schema_id_hugegraph_hits 0
# HELP org_apache_hugegraph_backend_cache_Cache_schema_id_hugegraph_miss
# TYPE org_apache_hugegraph_backend_cache_Cache_schema_id_hugegraph_miss gauge
org_apache_hugegraph_backend_cache_Cache_schema_id_hugegraph_miss 0
# HELP org_apache_hugegraph_backend_cache_Cache_schema_id_hugegraph_size
# TYPE org_apache_hugegraph_backend_cache_Cache_schema_id_hugegraph_size gauge
org_apache_hugegraph_backend_cache_Cache_schema_id_hugegraph_size 17
# HELP org_apache_hugegraph_backend_cache_Cache_schema_name_hugegraph_capacity
# TYPE org_apache_hugegraph_backend_cache_Cache_schema_name_hugegraph_capacity gauge
org_apache_hugegraph_backend_cache_Cache_schema_name_hugegraph_capacity 10000
# HELP org_apache_hugegraph_backend_cache_Cache_schema_name_hugegraph_expire
# TYPE org_apache_hugegraph_backend_cache_Cache_schema_name_hugegraph_expire gauge
org_apache_hugegraph_backend_cache_Cache_schema_name_hugegraph_expire 0
# HELP org_apache_hugegraph_backend_cache_Cache_schema_name_hugegraph_hits
# TYPE org_apache_hugegraph_backend_cache_Cache_schema_name_hugegraph_hits gauge
org_apache_hugegraph_backend_cache_Cache_schema_name_hugegraph_hits 0
# HELP org_apache_hugegraph_backend_cache_Cache_schema_name_hugegraph_miss
# TYPE org_apache_hugegraph_backend_cache_Cache_schema_name_hugegraph_miss gauge
org_apache_hugegraph_backend_cache_Cache_schema_name_hugegraph_miss 0
# HELP org_apache_hugegraph_backend_cache_Cache_schema_name_hugegraph_size
# TYPE org_apache_hugegraph_backend_cache_Cache_schema_name_hugegraph_size gauge
org_apache_hugegraph_backend_cache_Cache_schema_name_hugegraph_size 17
...
1.2 Get Gauges Metrics
Method & Url
http://localhost:8080/metrics/gauges
Response Status
200
Response Body
{
"org.apache.hugegraph.backend.cache.Cache.edge-hugegraph.capacity": {
"value": 1000000
},
"org.apache.hugegraph.backend.cache.Cache.edge-hugegraph.expire": {
"value": 600000
},
"org.apache.hugegraph.backend.cache.Cache.edge-hugegraph.hits": {
"value": 0
},
"org.apache.hugegraph.backend.cache.Cache.edge-hugegraph.miss": {
"value": 0
},
"org.apache.hugegraph.backend.cache.Cache.edge-hugegraph.size": {
"value": 0
},
"org.apache.hugegraph.backend.cache.Cache.instances": {
"value": 7
},
"org.apache.hugegraph.backend.cache.Cache.schema-id-hugegraph.capacity": {
"value": 10000
},
"org.apache.hugegraph.backend.cache.Cache.schema-id-hugegraph.expire": {
"value": 0
},
"org.apache.hugegraph.backend.cache.Cache.schema-id-hugegraph.hits": {
"value": 0
},
"org.apache.hugegraph.backend.cache.Cache.schema-id-hugegraph.miss": {
"value": 0
},
"org.apache.hugegraph.backend.cache.Cache.schema-id-hugegraph.size": {
"value": 17
},
"org.apache.hugegraph.backend.cache.Cache.schema-name-hugegraph.capacity": {
"value": 10000
},
"org.apache.hugegraph.backend.cache.Cache.schema-name-hugegraph.expire": {
"value": 0
},
"org.apache.hugegraph.backend.cache.Cache.schema-name-hugegraph.hits": {
"value": 0
},
"org.apache.hugegraph.backend.cache.Cache.schema-name-hugegraph.miss": {
"value": 0
},
"org.apache.hugegraph.backend.cache.Cache.schema-name-hugegraph.size": {
"value": 17
},
"org.apache.hugegraph.backend.cache.Cache.token-hugegraph.capacity": {
"value": 10240
},
"org.apache.hugegraph.backend.cache.Cache.token-hugegraph.expire": {
"value": 600000
},
"org.apache.hugegraph.backend.cache.Cache.token-hugegraph.hits": {
"value": 0
},
"org.apache.hugegraph.backend.cache.Cache.token-hugegraph.miss": {
"value": 0
},
"org.apache.hugegraph.backend.cache.Cache.token-hugegraph.size": {
"value": 0
},
"org.apache.hugegraph.backend.cache.Cache.users-hugegraph.capacity": {
"value": 10240
},
"org.apache.hugegraph.backend.cache.Cache.users-hugegraph.expire": {
"value": 600000
},
"org.apache.hugegraph.backend.cache.Cache.users-hugegraph.hits": {
"value": 0
},
"org.apache.hugegraph.backend.cache.Cache.users-hugegraph.miss": {
"value": 0
},
"org.apache.hugegraph.backend.cache.Cache.users-hugegraph.size": {
"value": 0
},
"org.apache.hugegraph.backend.cache.Cache.users_pwd-hugegraph.capacity": {
"value": 10240
},
"org.apache.hugegraph.backend.cache.Cache.users_pwd-hugegraph.expire": {
"value": 600000
},
"org.apache.hugegraph.backend.cache.Cache.users_pwd-hugegraph.hits": {
"value": 0
},
"org.apache.hugegraph.backend.cache.Cache.users_pwd-hugegraph.miss": {
"value": 0
},
"org.apache.hugegraph.backend.cache.Cache.users_pwd-hugegraph.size": {
"value": 0
},
"org.apache.hugegraph.backend.cache.Cache.vertex-hugegraph.capacity": {
"value": 10000000
},
"org.apache.hugegraph.backend.cache.Cache.vertex-hugegraph.expire": {
"value": 600000
},
"org.apache.hugegraph.backend.cache.Cache.vertex-hugegraph.hits": {
"value": 0
},
"org.apache.hugegraph.backend.cache.Cache.vertex-hugegraph.miss": {
"value": 0
},
"org.apache.hugegraph.backend.cache.Cache.vertex-hugegraph.size": {
"value": 0
},
"org.apache.hugegraph.server.RestServer.max-write-threads": {
"value": 0
},
"org.apache.hugegraph.task.TaskManager.pending-tasks": {
"value": 0
},
"org.apache.hugegraph.task.TaskManager.workers": {
"value": 4
},
"org.apache.tinkerpop.gremlin.server.GremlinServer.gremlin-groovy.sessionless.class-cache.average-load-penalty": {
"value": 9.227692E8
},
"org.apache.tinkerpop.gremlin.server.GremlinServer.gremlin-groovy.sessionless.class-cache.estimated-size": {
"value": 2
},
"org.apache.tinkerpop.gremlin.server.GremlinServer.gremlin-groovy.sessionless.class-cache.eviction-count": {
"value": 0
},
"org.apache.tinkerpop.gremlin.server.GremlinServer.gremlin-groovy.sessionless.class-cache.eviction-weight": {
"value": 0
},
"org.apache.tinkerpop.gremlin.server.GremlinServer.gremlin-groovy.sessionless.class-cache.hit-count": {
"value": 0
},
"org.apache.tinkerpop.gremlin.server.GremlinServer.gremlin-groovy.sessionless.class-cache.hit-rate": {
"value": 0.0
},
"org.apache.tinkerpop.gremlin.server.GremlinServer.gremlin-groovy.sessionless.class-cache.load-count": {
"value": 2
},
"org.apache.tinkerpop.gremlin.server.GremlinServer.gremlin-groovy.sessionless.class-cache.load-failure-count": {
"value": 0
},
"org.apache.tinkerpop.gremlin.server.GremlinServer.gremlin-groovy.sessionless.class-cache.load-failure-rate": {
"value": 0.0
},
"org.apache.tinkerpop.gremlin.server.GremlinServer.gremlin-groovy.sessionless.class-cache.load-success-count": {
"value": 2
},
"org.apache.tinkerpop.gremlin.server.GremlinServer.gremlin-groovy.sessionless.class-cache.long-run-compilation-count": {
"value": 0
},
"org.apache.tinkerpop.gremlin.server.GremlinServer.gremlin-groovy.sessionless.class-cache.miss-count": {
"value": 2
},
"org.apache.tinkerpop.gremlin.server.GremlinServer.gremlin-groovy.sessionless.class-cache.miss-rate": {
"value": 1.0
},
"org.apache.tinkerpop.gremlin.server.GremlinServer.gremlin-groovy.sessionless.class-cache.request-count": {
"value": 2
},
"org.apache.tinkerpop.gremlin.server.GremlinServer.gremlin-groovy.sessionless.class-cache.total-load-time": {
"value": 1845538400
},
"org.apache.tinkerpop.gremlin.server.GremlinServer.sessions": {
"value": 0
}
}
1.3 Get Counters Metrics
Method & Url
GET http://localhost:8080/metrics/counters
Response Status
200
Response Body
{
"favicon.ico/GET/FAILED_COUNTER": {
"count": 1
},
"favicon.ico/GET/TOTAL_COUNTER": {
"count": 1
},
"metrics//GET/SUCCESS_COUNTER": {
"count": 2
},
"metrics//GET/TOTAL_COUNTER": {
"count": 2
},
"metrics/POST/FAILED_COUNTER": {
"count": 1
},
"metrics/POST/TOTAL_COUNTER": {
"count": 1
},
"metrics/backend/GET/SUCCESS_COUNTER": {
"count": 2
},
"metrics/backend/GET/TOTAL_COUNTER": {
"count": 2
},
"metrics/gauges/GET/SUCCESS_COUNTER": {
"count": 1
},
"metrics/gauges/GET/TOTAL_COUNTER": {
"count": 1
},
"metrics/statistics/GET/SUCCESS_COUNTER": {
"count": 2
},
"metrics/statistics/GET/TOTAL_COUNTER": {
"count": 2
},
"metrics/system/GET/SUCCESS_COUNTER": {
"count": 2
},
"metrics/system/GET/TOTAL_COUNTER": {
"count": 2
},
"metrics/timers/GET/SUCCESS_COUNTER": {
"count": 1
},
"metrics/timers/GET/TOTAL_COUNTER": {
"count": 1
},
"system/GET/FAILED_COUNTER": {
"count": 1
},
"system/GET/TOTAL_COUNTER": {
"count": 1
}
}
1.4 Get Histograms Metrics
Method & Url
GET http://localhost:8080/metrics/gauges
Response Status
200
Response Body
{
"favicon.ico/GET/RESPONSE_TIME_HISTOGRAM": {
"count": 1,
"min": 1,
"mean": 1.0,
"max": 1,
"stddev": 0.0,
"p50": 1.0,
"p75": 1.0,
"p95": 1.0,
"p98": 1.0,
"p99": 1.0,
"p999": 1.0
},
"metrics//GET/RESPONSE_TIME_HISTOGRAM": {
"count": 2,
"min": 10,
"mean": 10.0,
"max": 10,
"stddev": 0.0,
"p50": 10.0,
"p75": 10.0,
"p95": 10.0,
"p98": 10.0,
"p99": 10.0,
"p999": 10.0
},
"metrics/POST/RESPONSE_TIME_HISTOGRAM": {
"count": 1,
"min": 21,
"mean": 21.0,
"max": 21,
"stddev": 0.0,
"p50": 21.0,
"p75": 21.0,
"p95": 21.0,
"p98": 21.0,
"p99": 21.0,
"p999": 21.0
},
"metrics/backend/GET/RESPONSE_TIME_HISTOGRAM": {
"count": 2,
"min": 6,
"mean": 12.6852124529148,
"max": 20,
"stddev": 6.992918475157571,
"p50": 6.0,
"p75": 20.0,
"p95": 20.0,
"p98": 20.0,
"p99": 20.0,
"p999": 20.0
},
"metrics/gauges/GET/RESPONSE_TIME_HISTOGRAM": {
"count": 1,
"min": 7,
"mean": 7.0,
"max": 7,
"stddev": 0.0,
"p50": 7.0,
"p75": 7.0,
"p95": 7.0,
"p98": 7.0,
"p99": 7.0,
"p999": 7.0
},
"metrics/statistics/GET/RESPONSE_TIME_HISTOGRAM": {
"count": 2,
"min": 1,
"mean": 1.4551211076264199,
"max": 2,
"stddev": 0.49798181193626,
"p50": 1.0,
"p75": 2.0,
"p95": 2.0,
"p98": 2.0,
"p99": 2.0,
"p999": 2.0
},
"metrics/system/GET/RESPONSE_TIME_HISTOGRAM": {
"count": 2,
"min": 0,
"mean": 8.942674506664073,
"max": 40,
"stddev": 16.665399873223066,
"p50": 0.0,
"p75": 0.0,
"p95": 40.0,
"p98": 40.0,
"p99": 40.0,
"p999": 40.0
},
"metrics/timers/GET/RESPONSE_TIME_HISTOGRAM": {
"count": 1,
"min": 3,
"mean": 3.0,
"max": 3,
"stddev": 0.0,
"p50": 3.0,
"p75": 3.0,
"p95": 3.0,
"p98": 3.0,
"p99": 3.0,
"p999": 3.0
},
"system/GET/RESPONSE_TIME_HISTOGRAM": {
"count": 1,
"min": 2,
"mean": 2.0,
"max": 2,
"stddev": 0.0,
"p50": 2.0,
"p75": 2.0,
"p95": 2.0,
"p98": 2.0,
"p99": 2.0,
"p999": 2.0
}
}
1.5 Get Meters Metrics
Method & Url
GET http://localhost:8080/metrics/meters
Response Status
200
Response Body
{
"org.apache.hugegraph.api.API.commit-succeed": {
"count": 0,
"mean_rate": 0.0,
"m15_rate": 0.0,
"m5_rate": 0.0,
"m1_rate": 0.0,
"rate_unit": "events/second"
},
"org.apache.hugegraph.api.API.expected-error": {
"count": 0,
"mean_rate": 0.0,
"m15_rate": 0.0,
"m5_rate": 0.0,
"m1_rate": 0.0,
"rate_unit": "events/second"
},
"org.apache.hugegraph.api.API.illegal-arg": {
"count": 0,
"mean_rate": 0.0,
"m15_rate": 0.0,
"m5_rate": 0.0,
"m1_rate": 0.0,
"rate_unit": "events/second"
},
"org.apache.hugegraph.api.API.unknown-error": {
"count": 0,
"mean_rate": 0.0,
"m15_rate": 0.0,
"m5_rate": 0.0,
"m1_rate": 0.0,
"rate_unit": "events/second"
},
"org.apache.tinkerpop.gremlin.server.GremlinServer.errors": {
"count": 0,
"mean_rate": 0.0,
"m15_rate": 0.0,
"m5_rate": 0.0,
"m1_rate": 0.0,
"rate_unit": "events/second"
}
}
1.6 Get Timers Metrics
Method & Url
GET http://localhost:8080/metrics/timers
Response Status
200
Response Body
{
"org.apache.hugegraph.api.auth.AccessAPI.create": {
"count": 0,
"min": 0.0,
"mean": 0.0,
"max": 0.0,
"stddev": 0.0,
"p50": 0.0,
"p75": 0.0,
"p95": 0.0,
"p98": 0.0,
"p99": 0.0,
"p999": 0.0,
"duration_unit": "milliseconds",
"mean_rate": 0.0,
"m15_rate": 0.0,
"m5_rate": 0.0,
"m1_rate": 0.0,
"rate_unit": "calls/second"
},
"org.apache.hugegraph.api.auth.AccessAPI.delete": {
"count": 0,
"min": 0.0,
"mean": 0.0,
"max": 0.0,
"stddev": 0.0,
"p50": 0.0,
"p75": 0.0,
"p95": 0.0,
"p98": 0.0,
"p99": 0.0,
"p999": 0.0,
"duration_unit": "milliseconds",
"mean_rate": 0.0,
"m15_rate": 0.0,
"m5_rate": 0.0,
"m1_rate": 0.0,
"rate_unit": "calls/second"
},
...
}
2.Statistical Metrics
Params
- type: If the passed value is JSON, it is returned in JSON format, otherwise it is returned in Promethaus format.
2.1 Method & Url
GET http://localhost:8080/metrics/statistics
Response Status
# HELP hugegraph_info
# TYPE hugegraph_info untyped
hugegraph_info{version="0.69",
} 1.0
# HELP metrics_POST
# TYPE metrics_POST gauge
metrics_POST{name=FAILED_REQUEST,} 1
metrics_POST{name=MEAN_RESPONSE_TIME,} 21.0
metrics_POST{
name=MAX_RESPONSE_TIME,
} 21
metrics_POST{name=SUCCESS_REQUEST,
} 0
metrics_POST{
name=TOTAL_REQUEST,
} 1
# HELP metrics_backend_GET
# TYPE metrics_backend_GET gauge
metrics_backend_GET{name=FAILED_REQUEST,
} 0
metrics_backend_GET{
name=MEAN_RESPONSE_TIME,
} 12.6852124529148
metrics_backend_GET{
name=MAX_RESPONSE_TIME,
} 20
metrics_backend_GET{
name=SUCCESS_REQUEST,
} 2
metrics_backend_GET{name=TOTAL_REQUEST,} 2
# HELP system_GET
# TYPE system_GET gauge
system_GET{name=FAILED_REQUEST,} 1
system_GET{name=MEAN_RESPONSE_TIME,} 2.0
system_GET{name=MAX_RESPONSE_TIME,} 2
system_GET{
name=SUCCESS_REQUEST,
} 0
system_GET{name=TOTAL_REQUEST,
} 1
# HELP metrics_gauges_GET
# TYPE metrics_gauges_GET gauge
metrics_gauges_GET{name=FAILED_REQUEST,} 0
metrics_gauges_GET{name=MEAN_RESPONSE_TIME,
} 7.0
metrics_gauges_GET{
name=MAX_RESPONSE_TIME,
} 7
metrics_gauges_GET{
name=SUCCESS_REQUEST,
} 1
metrics_gauges_GET{
name=TOTAL_REQUEST,
} 1
# HELP favicon.ico_GET
# TYPE favicon.ico_GET gauge
favicon.ico_GET{name=FAILED_REQUEST,
} 1
favicon.ico_GET{
name=MEAN_RESPONSE_TIME,
} 1.0
favicon.ico_GET{name=MAX_RESPONSE_TIME,} 1
favicon.ico_GET{name=SUCCESS_REQUEST,} 0
favicon.ico_GET{
name=TOTAL_REQUEST,
} 1
# HELP metrics__GET
# TYPE metrics__GET gauge
metrics__GET{name=FAILED_REQUEST,} 0
metrics__GET{name=MEAN_RESPONSE_TIME,} 10.0
metrics__GET{name=MAX_RESPONSE_TIME,
} 10
metrics__GET{
name=SUCCESS_REQUEST,
} 2
metrics__GET{
name=TOTAL_REQUEST,
} 2
# HELP metrics_system_GET
# TYPE metrics_system_GET gauge
metrics_system_GET{name=FAILED_REQUEST,} 0
metrics_system_GET{name=MEAN_RESPONSE_TIME,
} 8.942674506664073
metrics_system_GET{
name=MAX_RESPONSE_TIME,
} 40
metrics_system_GET{name=SUCCESS_REQUEST,} 2
metrics_system_GET{name=TOTAL_REQUEST,
} 2
Response Body
200
2.2 Method & Url
GET http://localhost:8080/metrics/statistics?type=json
Response Status
200
Response Body
{
"metrics/POST": {
"FAILED_REQUEST": 1,
"MEAN_RESPONSE_TIME": 21,
"MAX_RESPONSE_TIME": 21,
"SUCCESS_REQUEST": 0,
"TOTAL_REQUEST": 1
},
"metrics/backend/GET": {
"FAILED_REQUEST": 0,
"MEAN_RESPONSE_TIME": 12.6852124529148,
"MAX_RESPONSE_TIME": 20,
"SUCCESS_REQUEST": 2,
"TOTAL_REQUEST": 2
},
"system/GET": {
"FAILED_REQUEST": 1,
"MEAN_RESPONSE_TIME": 2,
"MAX_RESPONSE_TIME": 2,
"SUCCESS_REQUEST": 0,
"TOTAL_REQUEST": 1
},
"metrics/gauges/GET": {
"FAILED_REQUEST": 0,
"MEAN_RESPONSE_TIME": 7,
"MAX_RESPONSE_TIME": 7,
"SUCCESS_REQUEST": 1,
"TOTAL_REQUEST": 1
},
"favicon.ico/GET": {
"FAILED_REQUEST": 1,
"MEAN_RESPONSE_TIME": 1,
"MAX_RESPONSE_TIME": 1,
"SUCCESS_REQUEST": 0,
"TOTAL_REQUEST": 1
},
"metrics//GET": {
"FAILED_REQUEST": 0,
"MEAN_RESPONSE_TIME": 10,
"MAX_RESPONSE_TIME": 10,
"SUCCESS_REQUEST": 2,
"TOTAL_REQUEST": 2
},
"metrics/system/GET": {
"FAILED_REQUEST": 0,
"MEAN_RESPONSE_TIME": 8.942674506664073,
"MAX_RESPONSE_TIME": 40,
"SUCCESS_REQUEST": 2,
"TOTAL_REQUEST": 2
}
}
3.System Metrics
System metrics mainly return the machine metrics, such as memory, threads, and other information.
Method & Url
GET http://localhost:8080/metrics/system
Response Status
200
Response Body
{
"basic": {
"mem": 1010,
"mem_total": 911,
"mem_used": 239,
"mem_free": 671,
"mem_unit": "MB",
"processors": 20,
"uptime": 137503,
"systemload_average": -1.0
},
"heap": {
"committed": 911,
"init": 254,
"used": 239,
"max": 3596
},
"nonheap": {
"committed": 98,
"init": 2,
"used": 95,
"max": 0
},
"thread": {
"peak": 82,
"daemon": 34,
"total_started": 108,
"count": 82
},
"class_loading": {
"count": 11495,
"loaded": 11495,
"unloaded": 0
},
"garbage_collector": {
"ps_scavenge_count": 16,
"ps_scavenge_time": 155,
"ps_marksweep_count": 3,
"ps_marksweep_time": 494,
"time_unit": "ms"
}
}
4.Backend Metrics
HugeGraph supports multiple backend storage, with backend metrics including memory, disk, and other information.
Method & Url
GET http://localhost:8080/metrics/backend
Response Status
200
Response Body
{
"hugegraph": {
"backend": "rocksdb",
"nodes": 1,
"cluster_id": "local",
"servers": {
"local": {
"mem_unit": "MB",
"disk_unit": "GB",
"mem_used": 0.1,
"mem_used_readable": "103.53 KB",
"disk_usage": 0.03,
"disk_usage_readable": "29.03 KB",
"block_cache_usage": 0.00359344482421875,
"block_cache_pinned_usage": 0.00359344482421875,
"block_cache_capacity": 304.0,
"estimate_table_readers_mem": 0.019697189331054688,
"size_all_mem_tables": 0.07421875,
"cur_size_all_mem_tables": 0.07421875,
"estimate_live_data_size": 5.536526441574097E-5,
"total_sst_files_size": 5.536526441574097E-5,
"live_sst_files_size": 5.536526441574097E-5,
"estimate_pending_compaction_bytes": 0.0,
"estimate_num_keys": 0,
"num_entries_active_mem_table": 0,
"num_entries_imm_mem_tables": 0,
"num_deletes_active_mem_table": 0,
"num_deletes_imm_mem_tables": 0,
"num_running_flushes": 0,
"mem_table_flush_pending": 0,
"num_running_compactions": 0,
"compaction_pending": 0,
"num_immutable_mem_table": 0,
"num_snapshots": 0,
"oldest_snapshot_time": 0,
"num_live_versions": 38,
"current_super_version_number": 38
}
}
}
}
1.19 - Other API
11.1 Other
11.1.1 View Version Information of HugeGraph
Method & Url
GET http://localhost:8080/versions
Response Status
200
Response Body
{
"versions": {
"version": "v1",
"core": "0.4.5.1",
"gremlin": "3.2.5",
"api": "0.13.2.0"
}
}
2 - HugeGraph Java Client
The code in this document is written in java, but its style is very similar to gremlin(groovy). The user only needs to replace the variable declaration in the code with def or remove it directly,
You can convert java code into groovy; in addition, each line of statement can be without a semicolon at the end, groovy considers a line to be a statement.
The gremlin(groovy) written by the user in HugeGraph-Studio can refer to the java code in this document, and some examples will be given below.
1 HugeGraph-Client
HugeGraph-Client is the general entry for operating graph. Users must first create a HugeGraph-Client object and establish a connection (pseudo connection) with HugeGraph-Server before they can obtain the operation entry objects of schema, graph and gremlin.
Currently, HugeGraph-Client only allows connections to existing graphs on the server, and cannot create custom graphs. After version 1.7.0, client has supported setting graphSpace, the default value for graphSpace is DEFAULT. Its creation method is as follows:
// HugeGraphServer address: "http://localhost:8080"
// Graph Name: "hugegraph"
HugeClient hugeClient = HugeClient.builder("http://localhost:8080", "hugegraph")
//.builder("http://localhost:8080", "graphSpaceName", "hugegraph")
.configTimeout(20) // 20s timeout
.configUser("**", "**") // enable auth
.build();
If the above process of creating HugeClient fails, an exception will be thrown, and the user needs to use try-catch. If successful, continue to get schema, graph and gremlin manager.
When operating through gremlin in HugeGraph-Hubble(or HugeGraph-Studio), HugeClient is not required and can be ignored.
2 Schema
2.1 SchemaManager
SchemaManager is used to manage four kinds of schema in HugeGraph, namely PropertyKey (property type), VertexLabel (vertex type), EdgeLabel (edge type) and IndexLabel (index label). A SchemaManager object can be created for schema information definition.
The user can obtain the SchemaManager object using the following methods:
SchemaManager schema = hugeClient.schema()
Create a schema object via gremlin in HugeGraph-Hubble:
schema = graph.schema()
The definition process of the 4 kinds of schema is described below.
2.2 PropertyKey
2.2.1 Interface and parameter introduction
PropertyKey is used to standardize the property constraints of vertices and edges, and properties of properties are not currently supported.
The constraint information that PropertyKey allows to define includes: name, datatype, cardinality, and userdata, which are introduced one by one below.
- name: The name of the property, used to distinguish different PropertyKeys, PropertyKeys with the same name are not allowed.
| interface | param | must set |
|---|---|---|
| propertyKey(String name) | name | y |
- datatype: property value type, you must select an explicit setting from the following table that conforms to the specific business scenario:
| interface | Java Class |
|---|---|
| asText() | String |
| asInt() | Integer |
| asDate() | Date |
| asUuid() | UUID |
| asBoolean() | Boolean |
| asByte() | Byte |
| asBlob() | Byte[] |
| asDouble() | Double |
| asFloat() | Float |
| asLong() | Long |
- cardinality: Whether the property value is single-valued or multivalued, in the case of multivalued, it is divided into allowing-duplicate values and not-allowing-duplicate values. This item is single by default. If necessary, you can select a setting from the following table:
| interface | cardinality | description |
|---|---|---|
| valueSingle() | single | single value |
| valueList() | list | multi-values that allow duplicate value |
| valueSet() | set | multi-values that not allow duplicate value |
- userdata: Users can add some constraints or additional information by themselves, and then check whether the incoming properties satisfy the constraints, or extract additional information when necessary:
| interface | description |
|---|---|
| userdata(String key, Object value) | The same key, the latter will cover the former |
2.2.2 Create PropertyKey
schema.propertyKey("name").asText().valueSet().ifNotExist().create()
The syntax of creating the above PropertyKey object through gremlin in HugeGraph-Hubble is exactly the same. If the user does not define the schema variable, it should be written like this:
graph.schema().propertyKey("name").asText().valueSet().ifNotExist().create()
In the following examples, the syntax of gremlin and java is exactly the same, so we won’t repeat them.
- ifNotExist(): Add a judgment mechanism for create, if the current PropertyKey already exists, it will not be created, otherwise the property will be created. If no ifNotExist() is added, an exception will be thrown if a property-key with the same name already exists. The same as below, and will not be repeated there.
2.2.3 Delete PropertyKey
schema.propertyKey("name").remove()
2.2.4 Query PropertyKey
// Get PropertyKey
schema.getPropertyKey("name")
// Get attributes of PropertyKey
schema.getPropertyKey("name").cardinality()
schema.getPropertyKey("name").dataType()
schema.getPropertyKey("name").name()
schema.getPropertyKey("name").userdata()
2.3 VertexLabel
2.3.1 Interface and parameter introduction
VertexLabel is used to define the vertex type and describe the constraint information of the vertex.
The constraint information that VertexLabel allows to define include: name, idStrategy, properties, primaryKeys and nullableKeys, which are introduced one by one below.
- name: The name of the VertexLabel, used to distinguish different VertexLabels, VertexLabels with the same name are not allowed.
| interface | param | must set |
|---|---|---|
| vertexLabel(String name) | name | y |
- idStrategy: Each VertexLabel can choose its own ID strategy. There are currently three strategies to choose from, namely Automatic (automatically generated), Customize (user input) and PrimaryKey (primary attribute key). Among them, Automatic uses the Snowflake algorithm to generate ID, Customize requires the user to pass in the ID of string or number type, and PrimaryKey allows the user to select several properties of VertexLabel as the basis for differentiation. HugeGraph will be spliced and generated ID according to the value of the primary properties. idStrategy uses Automatic by default, but if the user does not explicitly set idStrategy and calls the primaryKeys(…) method to set the primary property, then idStrategy will automatically use PrimaryKey.
| interface | idStrategy | description |
|---|---|---|
| useAutomaticId | AUTOMATIC | generate id automatically by Snowflake algorithm |
| useCustomizeStringId | CUSTOMIZE_STRING | passed id by user, must be string type |
| useCustomizeNumberId | CUSTOMIZE_NUMBER | passed id by user, must be number type |
| usePrimaryKeyId | PRIMARY_KEY | choose some important prop as primary key to splice id |
- properties: define the properties of the vertex, the incoming parameter is the name of the PropertyKey.
| interface | description |
|---|---|
| properties(String… properties) | allow to pass multi properties |
- primaryKeys: When the user selects the ID strategy of PrimaryKey, several primary properties need to be selected from the properties of VertexLabel as the basis for differentiation;
| interface | description |
|---|---|
| primaryKeys(String… keys) | allow to choose multi prop as primaryKeys |
Note that the selection of the ID strategy and the setting of primaryKeys have some mutual constraints, which cannot be called at will. The constraints are shown in the following table:
| useAutomaticId | useCustomizeStringId | useCustomizeNumberId | usePrimaryKeyId | |
|---|---|---|---|---|
| unset primaryKeys | AUTOMATIC | CUSTOMIZE_STRING | CUSTOMIZE_NUMBER | ERROR |
| set primaryKeys | ERROR | ERROR | ERROR | PRIMARY_KEY |
- nullableKeys: For properties set by the properties(…) method, all of them are non-nullable by default, that is, the property must be assigned a value when creating a vertex, which may impose too strict integrity requirements on user data. In order to avoid such strong constraints, the user can set some properties to be nullable through this method, so that the properties can be unassigned when adding vertices.
| interface | description |
|---|---|
| nullableKeys(String… properties) | allow to pass multi props |
Note: primaryKeys and nullableKeys cannot intersect, because a property cannot be both primary and nullable.
- enableLabelIndex: The user can specify whether to create an index for the label. If you don’t create it, you can’t globally search for the vertices and edges of the specified label. If you create it, you can search globally, like
g.V().hasLabel('person'), g.E().has('label', 'person')query, but the performance will be slower when inserting data, and it will take up more storage space. This defaults to true.
| interface | description |
|---|---|
| enableLabelIndex(boolean enable) | Whether to create a label index |
- userdata: Users can add some constraints or additional information by themselves, and then check whether the incoming properties meet the constraints, or extract additional information when necessary.
| interface | description |
|---|---|
| userdata(String key, Object value) | The same key, the latter will cover the former |
2.3.2 Create VertexLabel
// Use Automatic Id strategy
schema.vertexLabel("person").properties("name", "age").ifNotExist().create();
schema.vertexLabel("person").useAutomaticId().properties("name", "age").ifNotExist().create();
// Use Customize_String Id strategy
schema.vertexLabel("person").useCustomizeStringId().properties("name", "age").ifNotExist().create();
// Use Customize_Number Id strategy
schema.vertexLabel("person").useCustomizeNumberId().properties("name", "age").ifNotExist().create();
// Use PrimaryKey Id strategy
schema.vertexLabel("person").properties("name", "age").primaryKeys("name").ifNotExist().create();
schema.vertexLabel("person").usePrimaryKeyId().properties("name", "age").primaryKeys("name").ifNotExist().create();
2.3.3 Update VertexLabel
VertexLabel can append constraints, but only properties and nullableKeys, and the appended properties must also be added to the nullableKeys collection.
schema.vertexLabel("person").properties("price").nullableKeys("price").append();
2.3.4 Delete VertexLabel
schema.vertexLabel("person").remove();
2.3.5 Query VertexLabel
// Get VertexLabel
schema.getVertexLabel("name")
// Get attributes of VertexLabel
schema.getVertexLabel("person").idStrategy()
schema.getVertexLabel("person").primaryKeys()
schema.getVertexLabel("person").name()
schema.getVertexLabel("person").properties()
schema.getVertexLabel("person").nullableKeys()
schema.getVertexLabel("person").userdata()
2.4 EdgeLabel
2.4.1 Interface and parameter introduction
EdgeLabel is used to define the edge type and describe the constraint information of the edge.
The constraint information that EdgeLabel allows to define include: name, sourceLabel, targetLabel, frequency, properties, sortKeys and nullableKeys, which are introduced one by one below.
- name: The name of the EdgeLabel, used to distinguish different EdgeLabels, EdgeLabels with the same name are not allowed.
| interface | param | must set |
|---|---|---|
| edgeLabel(String name) | name | y |
sourceLabel: The name of the source vertex type of the edge link, only one is allowed;
targetLabel: The name of the target vertex type of the edge link, only one is allowed;
| interface | param | must set |
|---|---|---|
| sourceLabel(String label) | label | y |
| targetLabel(String label) | label | y |
- frequency: Indicating the number of times a relationship occurs between two specific vertices, which can be single (single) or multiple (frequency), the default is single.
| interface | frequency | description |
|---|---|---|
| singleTime() | single | a relationship can only occur once |
| multiTimes() | multiple | a relationship can occur many times |
- properties: Define the properties of the edge.
| interface | description |
|---|---|
| properties(String… properties) | allow to pass multi props |
- sortKeys: When the frequency of EdgeLabel is multiple, some properties are needed to distinguish the multiple relationships, so sortKeys (sorted keys) is introduced;
| interface | description |
|---|---|
| sortKeys(String… keys) | allow to choose multi prop as sortKeys |
- nullableKeys: Consistent with the concept of nullableKeys in vertices.
Note: sortKeys and nullableKeys also cannot intersect.
enableLabelIndex: It is consistent with the concept of enableLabelIndex in the vertex.
userdata: Users can add some constraints or additional information by themselves, and then check whether the incoming properties meet the constraints, or extract additional information when necessary.
| interface | description |
|---|---|
| userdata(String key, Object value) | The same key, the latter will cover the former |
2.4.2 Create EdgeLabel
schema.edgeLabel("knows").link("person", "person").properties("date").ifNotExist().create();
schema.edgeLabel("created").multiTimes().link("person", "software").properties("date").sortKeys("date").ifNotExist().create();
2.4.3 Update EdgeLabel
schema.edgeLabel("knows").properties("price").nullableKeys("price").append();
2.4.4 Delete EdgeLabel
schema.edgeLabel("knows").remove();
2.4.5 Query EdgeLabel
// Get EdgeLabel
schema.getEdgeLabel("knows")
// Get attributes of EdgeLabel
schema.getEdgeLabel("knows").frequency()
schema.getEdgeLabel("knows").sourceLabel()
schema.getEdgeLabel("knows").targetLabel()
schema.getEdgeLabel("knows").sortKeys()
schema.getEdgeLabel("knows").name()
schema.getEdgeLabel("knows").properties()
schema.getEdgeLabel("knows").nullableKeys()
schema.getEdgeLabel("knows").userdata()
2.5 IndexLabel
2.5.1 Interface and parameter introduction
IndexLabel is used to define the index type and describe the constraint information of the index, mainly for the convenience of query.
The constraint information that IndexLabel allows to define include: name, baseType, baseValue, indexFields, indexType, which are introduced one by one below.
- name: The name of the IndexLabel, used to distinguish different IndexLabels, IndexLabels with the same name are not allowed.
| interface | param | must set |
|---|---|---|
| indexLabel(String name) | name | y |
baseType: Indicates whether to index VertexLabel or EdgeLabel, used in conjunction with the baseValue below.
baseValue: Specifies the name of the VertexLabel or EdgeLabel to be indexed.
| interface | param | description |
|---|---|---|
| onV(String baseValue) | baseValue | build index for VertexLabel: ‘baseValue’ |
| onE(String baseValue) | baseValue | build index for EdgeLabel: ‘baseValue’ |
- indexFields: on which fields to index, it can be a joint index for multiple columns.
| interface | param | description |
|---|---|---|
| by(String… fields) | files | allow to build index for multi fields for secondary index |
- indexType: There are currently five types of indexes established, namely Secondary, Range, Search, Shard and Unique.
- Secondary Index supports exact matching secondary index, allow to build joint index, joint index supports index prefix search
- Single Property Secondary Index, support equality query, for example: the secondary index of the city property of the person vertex, you can use
g.V().has("city", "Beijing")to query all the vertices with “city attribute value is Beijing” - Joint Secondary Index, supports prefix query and equality query, such as: joint index of city and street properties of person vertex, you can use
g.V().has("city", "Beijing").has('street', 'Zhongguancun street ')to query all vertices of “city property value is Beijing and street property value is ZhongGuanCun”, org.V().has("city", "Beijing")to query all vertices of “city property value is Beijing”.
The query of Secondary Index is based on the query condition of “yes” or “equal”, and does not support “partial matching”.
- Single Property Secondary Index, support equality query, for example: the secondary index of the city property of the person vertex, you can use
- Range Index supports for range queries of numeric types
- Must be a single number or date attribute, for example: the range index of the age property of the person vertex, you can use
g.V().has("age", P.gt(18))to query the vertices with “age property value greater than 18” . In addition toP.gt(), also supportsP.gte(),P.lte(),P.lt(),P.eq(),P.between(),P.inside()andP.outside()etc.
- Must be a single number or date attribute, for example: the range index of the age property of the person vertex, you can use
- Search Index supports full-text search
- It must be a single text property, such as: full-text index of the address property of the person vertex, you can use
g.V().has("address", Text.contains('building')to query all vertices whose “address property contains a ‘building’”
The query of the Search Index is based on the query condition of “is” or “contains”.
- It must be a single text property, such as: full-text index of the address property of the person vertex, you can use
- Shard Index supports prefix matching + numeric range query
- The shard index of N properties supports range queries with equal prefixes. For example, the shard index of the city and age properties of the person vertex can use
g.V().has("city", "Beijing").has ("age", P.between(18, 30))Query “city property is Beijing and all vertices whose age is greater than or equal to 18 and less than 30”. - When all N properties are text properties in a Shard Index, it is equivalent to Secondary Index.
- When there is only one single number or date property in a Shard Index, it is equivalent to the Range Index.
Shard Index can have any number or date property, but at most one range search condition can be provided when querying, and the prefix properties of the Shard Search conditions must be “equals”.
- The shard index of N properties supports range queries with equal prefixes. For example, the shard index of the city and age properties of the person vertex can use
- Unique Index supports properties uniqueness constraints, that is, the value of properties can be limited to not repeat, and joint indexing is allowed, but querying is not supported now
- The unique index of single or multiple properties cannot be used for query, only the value of the property can be limited, and an error will be reported when there is a duplicate value.
- Secondary Index supports exact matching secondary index, allow to build joint index, joint index supports index prefix search
| interface | indexType | description |
|---|---|---|
| secondary() | Secondary | support prefix search |
| range() | Range | support range(numeric or date type) search |
| search() | Search | support full text search |
| shard() | Shard | support prefix + range(numeric or date type) search |
| unique() | Unique | support unique props value, not support search |
2.5.2 Create IndexLabel
schema.indexLabel("personByAge").onV("person").by("age").range().ifNotExist().create();
schema.indexLabel("createdByDate").onE("created").by("date").secondary().ifNotExist().create();
schema.indexLabel("personByLived").onE("person").by("lived").search().ifNotExist().create();
schema.indexLabel("personByCityAndAge").onV("person").by("city", "age").shard().ifNotExist().create();
schema.indexLabel("personById").onV("person").by("id").unique().ifNotExist().create();
2.5.3 Delete IndexLabel
schema.indexLabel("personByAge").remove()
2.5.4 Query IndexLabel
// Get IndexLabel
schema.getIndexLabel("personByAge")
// Get attributes of IndexLabel
schema.getIndexLabel("personByAge").baseType()
schema.getIndexLabel("personByAge").baseValue()
schema.getIndexLabel("personByAge").indexFields()
schema.getIndexLabel("personByAge").indexType()
schema.getIndexLabel("personByAge").name()
3 Graph
3.1 Vertex
Vertices are the most basic elements of a graph, and there can be many vertices in a graph. Here is an example of adding vertices:
Vertex marko = graph.addVertex(T.label, "person", "name", "marko", "age", 29);
Vertex lop = graph.addVertex(T.label, "software", "name", "lop", "lang", "java", "price", 328);
- The key to adding vertices is the vertex properties. The number of parameters of the vertex adding function must be an even number and satisfy the order of
key1 -> val1, key2 -> val2 ..., and the order between key-value pairs is free . - The parameter must contain a special key-value pair, namely
T.label -> "val", which is used to define the category of the vertex, so that the program can obtain the schema definition of the VertexLabel from the cache or backend, and then do subsequent constraint checks. The label in the example is defined as person. - If the vertex type’s ID policy is
AUTOMATIC, users are not allowed to pass in id key-value pairs. - If the ID policy of the vertex type is
CUSTOMIZE_STRING, the user needs to pass in the value of the id of the String type. The key-value pair is like:"T.id", "123456". - If the ID policy of the vertex type is
CUSTOMIZE_NUMBER, the user needs to pass in the value of the id of the Number type. The key-value pair is like:"T.id", 123456. - If the ID policy of the vertex type is
PRIMARY_KEY, the parameters must also contain the name and value of the properties corresponding to theprimaryKeys, if not set an exception will be thrown. For example, theprimaryKeysofpersonisname, in the example, the value ofnameis set tomarko. - For properties that are not nullableKeys, a value must be assigned.
- The remaining parameters are the settings of other properties of the vertex, but they are not required.
- After calling the
addVertexmethod, the vertices are inserted into the backend storage system immediately.
3.2 Edge
After added vertices, edges are also needed to form a complete graph. Here is an example of adding edges:
Edge knows1 = marko.addEdge("knows", vadas, "city", "Beijing");
- The function
addEdge()of the (source) vertex is to add an edge(relationship) between itself and another vertex. The first parameter of the function is the label of the edge, and the second parameter is the target vertex. The position and order of these two parameters are fixed. The subsequent parameters are the order ofkey1 -> val1, key2 -> val2 ..., set the properties of the edge, and the key-value pair order is free. - The source and target vertices must conform to the definitions of source-label and target label in EdgeLabel, and cannot be added arbitrarily.
- For properties that are not nullableKeys, a value must be assigned.
Note: When frequency is multiple, the value of the property type corresponding to sortKeys must be set.
4 GraphSpace
The client supports multiple GraphSpaces in one physical deployment, and each GraphSpace can contain multiple graphs.
- Compatibility: When no GraphSpace is specified, the “DEFAULT” space is used by default.
4.1 Create GraphSpace
GraphSpaceManager spaceManager = hugeClient.graphSpace();
// Define GraphSpace configuration
GraphSpace graphSpace = new GraphSpace();
graphSpace.setName("myGraphSpace");
graphSpace.setDescription("Business data graph space");
graphSpace.setMaxGraphNumber(10); // Maximum number of graphs
graphSpace.setMaxRoleNumber(100); // Maximum number of roles
// Create GraphSpace
spaceManager.createGraphSpace(graphSpace);
4.2 GraphSpace Interface Summary
| Category | Interface | Description |
|---|---|---|
| Manager - Query | listGraphSpace() | Get the list of all GraphSpaces |
| getGraphSpace(String name) | Get the specified GraphSpace | |
| Manager - Create/Update | createGraphSpace(GraphSpace) | Create a GraphSpace |
| updateGraphSpace(String, GraphSpace) | Update configuration | |
| Manager - Delete | removeGraphSpace(String) | Delete the specified GraphSpace |
| GraphSpace - Properties | getName() / getDescription() | Get name / description |
| getGraphNumber() | Get the number of graphs | |
| GraphSpace - Configuration | setDescription(String) | Set description |
| setMaxGraphNumber(int) | Set the maximum number of graphs |
5 Simple Example
Simple examples can reference HugeGraph-Client
3 - Gremlin-Console
Gremlin-Console is an interactive client developed by TinkerPop. Users can use this client to perform various operations on Graph. There are two main usage modes:
- Stand-alone offline mode
- Client/Server mode
Note: Gremlin-Console is only for users to quickly get started and experience, it is not recommended for use in production environments.
1 Stand-alone offline mode
Since the lib directory already contains the HugeCore jar package, and HugeGraph-Server has been registered in the Console as a plug-in, the users can write a groovy script directly to call the code of HugeGraph-Core, and then hand it over to the parsing engine in Gremlin-Console for execution. As a result, the users can operate the graph without starting the Server.
Here is an example, first modify the hugegraph.properties configuration to use the Memory backend (using other backends may encounter some initialization issues):
backend=memory
serializer=text
Then enter the following command:
> ./bin/gremlin-console.sh -- -i scripts/example.groovy
\,,,/
(o o)
-----oOOo-(3)-oOOo-----
plugin activated: HugeGraph
plugin activated: tinkerpop.server
plugin activated: tinkerpop.utilities
plugin activated: tinkerpop.tinkergraph
main dict load finished, time elapsed 644 ms
model load finished, time elapsed 35 ms.
>>>> query all vertices: size=6
>>>> query all edges: size=6
gremlin>
The
--here will be parsed by getopts as the last option, allowing the subsequent options to be passed to Gremlin-Console for processing.-irepresentsExecute the specified script and leave the console open on completion. For more options, you can refer to the source code of Gremlin-Console.
example.groovy is an example script under the scripts directory. This script inserts some data and queries the number of vertices and edges in the graph at the end.
You can continue to enter Gremlin statements to operate on the graph:
gremlin> g.V()
==>v[2:lop]
==>v[1:josh]
==>v[1:marko]
==>v[1:peter]
==>v[1:vadas]
==>v[2:ripple]
gremlin> g.E()
==>e[S1:josh>2>>S2:lop][1:josh-created->2:lop]
==>e[S1:josh>2>>S2:ripple][1:josh-created->2:ripple]
==>e[S1:marko>1>>S1:josh][1:marko-knows->1:josh]
==>e[S1:marko>1>>S1:vadas][1:marko-knows->1:vadas]
==>e[S1:marko>2>>S2:lop][1:marko-created->2:lop]
==>e[S1:peter>2>>S2:lop][1:peter-created->2:lop]
gremlin>
For more Gremlin statements, please refer to Tinkerpop Official Website
2 Client/Server mode
Because Gremlin-Console can only connect to HugeGraph-Server through WebSocket, HugeGraph-Server provides HTTP connections by default, so modify the configuration of gremlin-server first.
NOTE: After changing the connection method to WebSocket, HugeGraph-Client, HugeGraph-Loader, HugeGraph-Hubble and other supporting tools cannot be used.
# vim conf/gremlin-server.yaml
# ......
# If you want to start gremlin-server for gremlin-console (web-socket),
# please change `HttpChannelizer` to `WebSocketChannelizer` or comment this line.
channelizer: org.apache.tinkerpop.gremlin.server.channel.HttpChannelizer
# ......
Modify channelizer: org.apache.tinkerpop.gremlin.server.channel.HttpChannelizer to channelizer: org.apache.tinkerpop.gremlin.server.channel.WebSocketChannelizer or comment directly, and then follow the steps to start the Server.
Then enter Gremlin-Console:
> ./bin/gremlin-console.sh
\,,,/
(o o)
-----oOOo-(3)-oOOo-----
plugin activated: HugeGraph
plugin activated: tinkerpop.server
plugin activated: tinkerpop.utilities
plugin activated: tinkerpop.tinkergraph
To connect to the server, you need to specify the connection parameters in the configuration file, and there is a default remote.yaml file in the conf directory
# cat conf/remote.yaml
hosts: [localhost]
port: 8182
serializer: {
className: org.apache.tinkerpop.gremlin.driver.ser.GraphSONMessageSerializerV1d0,
config: {
serializeResultToString: false,
ioRegistries: [org.apache.hugegraph.io.HugeGraphIoRegistry]
}
}
gremlin> :remote connect tinkerpop.server conf/remote.yaml
==>Configured localhost/127.0.0.1:8182
After a successful connection, if the sample graph example.groovy is imported during the startup of HugeGraph-Server, you can directly perform queries in the console.
gremlin> :> hugegraph.traversal().V()
==>[id:2:lop,label:software,type:vertex,properties:[name:lop,lang:java,price:328]]
==>[id:1:josh,label:person,type:vertex,properties:[name:josh,age:32,city:Beijing]]
==>[id:1:marko,label:person,type:vertex,properties:[name:marko,age:29,city:Beijing]]
==>[id:1:peter,label:person,type:vertex,properties:[name:peter,age:35,city:Shanghai]]
==>[id:1:vadas,label:person,type:vertex,properties:[name:vadas,age:27,city:Hongkong]]
==>[id:2:ripple,label:software,type:vertex,properties:[name:ripple,lang:java,price:199]]
NOTE: In Client/Server mode, all operations related to the Server should be prefixed with
:>. If not added, it indicates local console operations.
You can also put multiple statements in a single string variable and send them to the Server at once:
gremlin> script = """
......1> graph = hugegraph;
......2> g = graph.traversal();
......3> g.V().toList().size();
......4> """
==>
graph = hugegraph;
g = graph.traversal();
g.V().toList().size();
gremlin> :> @script
==>6
gremlin>
For more information on the use of Gremlin-Console, please refer to Tinkerpop Official Website