DeepWiki provides real-time updated project documentation with more comprehensive and accurate content, suitable for quickly understanding the latest project information.
GitHub Access: https://github.com/apache/hugegraph
This is the multi-page printable view of this section. Click here to print.
DeepWiki provides real-time updated project documentation with more comprehensive and accurate content, suitable for quickly understanding the latest project information.
GitHub Access: https://github.com/apache/hugegraph
HugeGraph-Server is the core server component of the HugeGraph project. It includes submodules such as graph-core, backend, and API.
The Core module implements the TinkerPop interfaces. The Backend module manages data storage. Starting from 1.7.0, supported backends include RocksDB (the default standalone backend), HStore (distributed), HBase, and Memory. The API module provides an HTTP server that converts client requests into calls to the Core module.
⚠️ Important Change: Starting from version 1.7.0, legacy backends such as MySQL, PostgreSQL, Cassandra, and ScyllaDB have been removed. If you need to use these backends, please use version 1.5.x or earlier.
The documentation uses both
HugeGraph-ServerandHugeGraphServer, and the same pattern applies to other components. The two names are nearly interchangeable:HugeGraph-Serverusually refers to the server-side codebase, whileHugeGraphServerrefers to the running service process.
Use Java 11 to run HugeGraph-Server. Versions earlier than 1.5.0 kept basic compatibility with Java 8, but Java 11 is recommended.
Before continuing, run java -version to confirm your JDK version.
Note: Running HugeGraph-Server on Java 8 loses some security protections and may reduce performance. Please upgrade as soon as possible. Java 8 is no longer supported starting from 1.7.0.
There are four ways to deploy HugeGraph-Server components:
Note: For production environments or environments exposed to the public network, you must use Java 11 and enable Auth authentication to avoid security risks.
You can refer to the Docker deployment guide.
You can use docker run -itd --name=server -p 8080:8080 -e PASSWORD=xxx hugegraph/hugegraph:1.7.0 to quickly start a HugeGraph-Server instance with a built-in RocksDB backend.
Optional:
docker exec -it server bash to enter the container for troubleshooting or other maintenance operations.docker run -itd --name=server -p 8080:8080 -e PRELOAD="true" hugegraph/hugegraph:1.7.0 to preload a built-in sample graph at startup. You can verify it through the RESTful API. See 5.1.8 for details.-e PASSWORD=xxx to enable authentication mode and set the admin password. See Config Authentication for details.If you use Docker Desktop, you can set the options as follows:
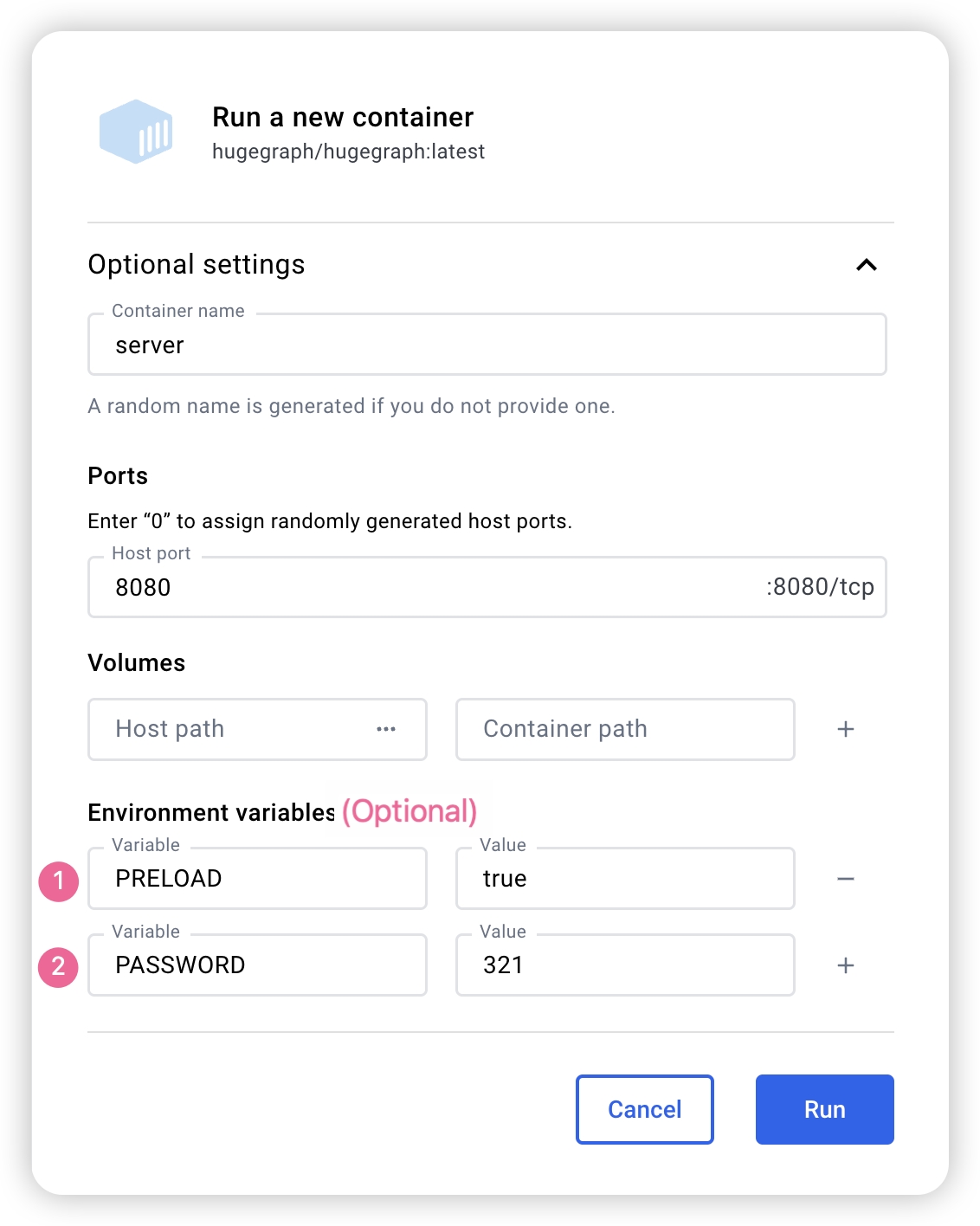
Note: The Docker Compose files use bridge networking (
hg-net) and work on Linux and Mac (Docker Desktop). For the 3-node distributed cluster on Mac (Docker Desktop), allocate at least 12 GB of memory (Settings → Resources → Memory). On Linux, Docker uses host memory directly.
If you want a single, unified setup for multiple HugeGraph services, you can use docker compose.
Two compose files are available in the docker/ directory:
docker/docker-compose.ymldocker/docker-compose.dev.ymlcd hugegraph/docker
# Keep the version aligned with the latest release, for example 1.x.0
HUGEGRAPH_VERSION=1.7.0 docker compose up -d
To enable authentication, add PASSWORD=xxx to the service environment in the compose file or pass -e PASSWORD=xxx to docker run.
See docker/README.md for the full setup guide.
Note:
HugeGraph Docker images are provided as a convenient way to start HugeGraph quickly, but they are not official ASF distribution artifacts. You can find more details in the ASF Release Distribution Policy.
We recommend using a release tag (such as
1.7.0or1.x.0) for stable deployments. Use thelatesttag only if you want the newest features still under development.
You could download the binary tarball from the download page of the ASF site like this:
# use the latest version, here is 1.7.0 for example
wget https://downloads.apache.org/hugegraph/{version}/apache-hugegraph-incubating-{version}.tar.gz
tar zxf *hugegraph*.tar.gz
# (Optional) verify the integrity with SHA512 (recommended)
shasum -a 512 apache-hugegraph-incubating-{version}.tar.gz
curl https://downloads.apache.org/hugegraph/{version}/apache-hugegraph-incubating-{version}.tar.gz.sha512
Please ensure that the wget/curl commands are installed before compiling the source code
Download HugeGraph source code in either of the following 2 ways (so as the other HugeGraph repos/modules):
# Way 1. download release package from the ASF site
wget https://downloads.apache.org/hugegraph/{version}/apache-hugegraph-incubating-src-{version}.tar.gz
tar zxf *hugegraph*.tar.gz
# (Optional) verify the integrity with SHA512 (recommended)
shasum -a 512 apache-hugegraph-incubating-src-{version}.tar.gz
curl https://downloads.apache.org/hugegraph/{version}/apache-hugegraph-incubating-{version}-src.tar.gz.sha512
# Way2 : clone the latest code by git way (e.g GitHub)
git clone https://github.com/apache/hugegraph.git
Compile and generate tarball
cd *hugegraph
# (Optional) use "-P stage" param if you build failed with the latest code(during pre-release period)
mvn package -DskipTests -ntp
The execution log is as follows:
......
[INFO] Reactor Summary for hugegraph 1.5.0:
[INFO]
[INFO] hugegraph .......................................... SUCCESS [ 2.405 s]
[INFO] hugegraph-core ..................................... SUCCESS [ 13.405 s]
[INFO] hugegraph-api ...................................... SUCCESS [ 25.943 s]
[INFO] hugegraph-cassandra ................................ SUCCESS [ 54.270 s]
[INFO] hugegraph-scylladb ................................. SUCCESS [ 1.032 s]
[INFO] hugegraph-rocksdb .................................. SUCCESS [ 34.752 s]
[INFO] hugegraph-mysql .................................... SUCCESS [ 1.778 s]
[INFO] hugegraph-palo ..................................... SUCCESS [ 1.070 s]
[INFO] hugegraph-hbase .................................... SUCCESS [ 32.124 s]
[INFO] hugegraph-postgresql ............................... SUCCESS [ 1.823 s]
[INFO] hugegraph-dist ..................................... SUCCESS [ 17.426 s]
[INFO] hugegraph-example .................................. SUCCESS [ 1.941 s]
[INFO] hugegraph-test ..................................... SUCCESS [01:01 min]
[INFO] ------------------------------------------------------------------------
[INFO] BUILD SUCCESS
[INFO] ------------------------------------------------------------------------
......
After successful execution, *hugegraph-*.tar.gz files will be generated in the hugegraph directory, which is the tarball generated by compilation.
HugeGraph-Tools provides a command-line tool for one-click deployment, users can use this tool to quickly download, decompress, configure and start HugeGraphServer and HugeGraph-Hubble with one click.
Of course, you should download the tarball of HugeGraph-Toolchain first.
# download toolchain binary package, it includes loader + tool + hubble
# please check the latest version (e.g. here is 1.7.0)
wget https://downloads.apache.org/hugegraph/1.7.0/apache-hugegraph-toolchain-incubating-1.7.0.tar.gz
tar zxf *hugegraph-*.tar.gz
# enter the tool's package
cd *hugegraph*/*tool*
note:
${version}is the version, The latest version can refer to Download Page, or click the link to download directly from the Download page
The general entry script for HugeGraph-Tools is bin/hugegraph, Users can use the help command to view its usage, here only the commands for one-click deployment are introduced.
bin/hugegraph deploy -v {hugegraph-version} -p {install-path} [-u {download-path-prefix}]
{hugegraph-version} indicates the version of HugeGraphServer and HugeGraphStudio to be deployed, users can view the conf/version-mapping.yaml file for version information, {install-path} specify the installation directory of HugeGraphServer and HugeGraphStudio, {download-path-prefix} optional, specify the download address of HugeGraphServer and HugeGraphStudio tarball, use default download URL if not provided, for example, to start HugeGraph-Server and HugeGraphStudio version 0.6, write the above command as bin/hugegraph deploy -v 0.6 -p services.
If you need to quickly start HugeGraph just for testing, then you only need to modify a few configuration items (see next section). For detailed configuration introduction, please refer to configuration document and introduction to configuration items
Startup is divided into “first startup” and “non-first startup”. On the first startup, you need to initialize the backend database before starting the service.
If the service was stopped manually, or needs to be started again for any other reason, you can usually start it directly because the backend database is persistent.
When HugeGraphServer starts, it connects to the backend storage and checks its version information. If the backend has not been initialized, or if it was initialized with an incompatible version (for example, old-version data), HugeGraphServer will fail to start and report an error.
If you need to access HugeGraphServer externally, modify the restserver.url configuration item in rest-server.properties (the default is http://127.0.0.1:8080) and change it to the machine name or IP address.
Since the configuration (hugegraph.properties) and startup steps required by various backends are slightly different, the following will introduce the configuration and startup of each backend one by one.
Note: Configure Server Authentication before starting HugeGraphServer if you need Auth mode (especially for production or public network environments).
Distributed storage is a new feature introduced after HugeGraph 1.5.0, which implements distributed data storage and computation based on HugeGraph-PD and HugeGraph-Store components.
To use the distributed storage engine, you need to deploy HugeGraph-PD and HugeGraph-Store first. See HugeGraph-PD Quick Start and HugeGraph-Store Quick Start.
After ensuring that both PD and Store services are started, modify the hugegraph.properties configuration of HugeGraph-Server:
backend=hstore
serializer=binary
task.scheduler_type=distributed
# PD service address, multiple PD addresses are separated by commas, configure PD's RPC port
pd.peers=127.0.0.1:8686,127.0.0.1:8687,127.0.0.1:8688
# Simple example (with authentication)
gremlin.graph=org.apache.hugegraph.auth.HugeFactoryAuthProxy
# Specify storage backend hstore
backend=hstore
serializer=binary
store=hugegraph
# Specify the task scheduler (for versions 1.7.0 and earlier, hstore storage is required)
task.scheduler_type=distributed
# pd config
pd.peers=127.0.0.1:8686
Then enable PD discovery in rest-server.properties (required for every HugeGraph-Server node):
usePD=true
# notice: must have this conf in 1.7.0
pd.peers=127.0.0.1:8686,127.0.0.1:8687,127.0.0.1:8688
# If auth is needed
# auth.authenticator=org.apache.hugegraph.auth.StandardAuthenticator
If configuring multiple HugeGraph-Server nodes, you need to modify the rest-server.properties configuration file for each node, for example:
Node 1 (Master node):
usePD=true
restserver.url=http://127.0.0.1:8081
gremlinserver.url=http://127.0.0.1:8181
pd.peers=127.0.0.1:8686
rpc.server_host=127.0.0.1
rpc.server_port=8091
server.id=server-1
server.role=master
Node 2 (Worker node):
usePD=true
restserver.url=http://127.0.0.1:8082
gremlinserver.url=http://127.0.0.1:8182
pd.peers=127.0.0.1:8686
rpc.server_host=127.0.0.1
rpc.server_port=8092
server.id=server-2
server.role=worker
Also, you need to modify the port configuration in gremlin-server.yaml for each node:
Node 1:
host: 127.0.0.1
port: 8181
Node 2:
host: 127.0.0.1
port: 8182
Initialize the database:
cd *hugegraph-${version}
bin/init-store.sh
Start the Server:
bin/start-hugegraph.sh
The startup sequence for using the distributed storage engine is:
Verify that the service is started properly:
curl http://localhost:8081/graphs
# Should return: {"graphs":["hugegraph"]}
The sequence to stop the services should be the reverse of the startup sequence:
bin/stop-hugegraph.sh
Run the full distributed cluster (3 PD + 3 Store + 3 Server) with Docker Compose:
cd hugegraph/docker
HUGEGRAPH_VERSION=1.7.0 docker compose -f docker-compose-3pd-3store-3server.yml up -d
Services communicate via container hostnames on the hg-net bridge network. Configuration is injected via environment variables:
# Server configuration
HG_SERVER_BACKEND: hstore
HG_SERVER_PD_PEERS: pd0:8686,pd1:8686,pd2:8686
Verify the cluster:
curl http://localhost:8080/versions
curl http://localhost:8620/v1/stores
To view runtime logs for any container use docker logs <container-name> (e.g. docker logs hg-pd0).
See docker/README.md for the full environment variable reference, port table, and troubleshooting guide.
Update hugegraph.properties
backend=memory
serializer=text
The data of the Memory backend is stored in memory and cannot be persisted. It does not need to initialize the backend. This is the only backend that does not require initialization.
Start server
bin/start-hugegraph.sh
Starting HugeGraphServer...
Connecting to HugeGraphServer (http://127.0.0.1:8080/graphs)....OK
The prompted url is the same as the restserver.url configured in rest-server.properties
RocksDB is an embedded database that does not require manual installation and deployment. GCC version >= 4.3.0 (GLIBCXX_3.4.10) is required. If not, GCC needs to be upgraded in advance
Update hugegraph.properties
backend=rocksdb
serializer=binary
rocksdb.data_path=.
rocksdb.wal_path=.
Initialize the database (required on the first startup, or a new configuration was manually added under ‘conf/graphs/’)
cd *hugegraph-${version}
bin/init-store.sh
Start server
bin/start-hugegraph.sh
Starting HugeGraphServer...
Connecting to HugeGraphServer (http://127.0.0.1:8080/graphs)....OK
ToplingDB (Beta): As a high-performance alternative to RocksDB, please refer to the configuration guide: ToplingDB Quick Start
⚠️ Deprecated: This backend has been removed starting from HugeGraph 1.7.0. If you need to use it, please refer to version 1.5.x documentation.
users need to install Cassandra by themselves, requiring version 3.0 or above, download link
Update hugegraph.properties
backend=cassandra
serializer=cassandra
# cassandra backend config
cassandra.host=localhost
cassandra.port=9042
cassandra.username=
cassandra.password=
#cassandra.connect_timeout=5
#cassandra.read_timeout=20
#cassandra.keyspace.strategy=SimpleStrategy
#cassandra.keyspace.replication=3
Initialize the database (required on the first startup, or a new configuration was manually added under ‘conf/graphs/’)
cd *hugegraph-${version}
bin/init-store.sh
Initing HugeGraph Store...
2017-12-01 11:26:51 1424 [main] [INFO ] org.apache.hugegraph.HugeGraph [] - Opening backend store: 'cassandra'
2017-12-01 11:26:52 2389 [main] [INFO ] org.apache.hugegraph.backend.store.cassandra.CassandraStore [] - Failed to connect keyspace: hugegraph, try init keyspace later
2017-12-01 11:26:52 2472 [main] [INFO ] org.apache.hugegraph.backend.store.cassandra.CassandraStore [] - Failed to connect keyspace: hugegraph, try init keyspace later
2017-12-01 11:26:52 2557 [main] [INFO ] org.apache.hugegraph.backend.store.cassandra.CassandraStore [] - Failed to connect keyspace: hugegraph, try init keyspace later
2017-12-01 11:26:53 2797 [main] [INFO ] org.apache.hugegraph.backend.store.cassandra.CassandraStore [] - Store initialized: huge_graph
2017-12-01 11:26:53 2945 [main] [INFO ] org.apache.hugegraph.backend.store.cassandra.CassandraStore [] - Store initialized: huge_schema
2017-12-01 11:26:53 3044 [main] [INFO ] org.apache.hugegraph.backend.store.cassandra.CassandraStore [] - Store initialized: huge_index
2017-12-01 11:26:53 3046 [pool-3-thread-1] [INFO ] org.apache.hugegraph.backend.Transaction [] - Clear cache on event 'store.init'
2017-12-01 11:26:59 9720 [main] [INFO ] org.apache.hugegraph.HugeGraph [] - Opening backend store: 'cassandra'
2017-12-01 11:27:00 9805 [main] [INFO ] org.apache.hugegraph.backend.store.cassandra.CassandraStore [] - Failed to connect keyspace: hugegraph1, try init keyspace later
2017-12-01 11:27:00 9886 [main] [INFO ] org.apache.hugegraph.backend.store.cassandra.CassandraStore [] - Failed to connect keyspace: hugegraph1, try init keyspace later
2017-12-01 11:27:00 9955 [main] [INFO ] org.apache.hugegraph.backend.store.cassandra.CassandraStore [] - Failed to connect keyspace: hugegraph1, try init keyspace later
2017-12-01 11:27:00 10175 [main] [INFO ] org.apache.hugegraph.backend.store.cassandra.CassandraStore [] - Store initialized: huge_graph
2017-12-01 11:27:00 10321 [main] [INFO ] org.apache.hugegraph.backend.store.cassandra.CassandraStore [] - Store initialized: huge_schema
2017-12-01 11:27:00 10413 [main] [INFO ] org.apache.hugegraph.backend.store.cassandra.CassandraStore [] - Store initialized: huge_index
2017-12-01 11:27:00 10413 [pool-3-thread-1] [INFO ] org.apache.hugegraph.backend.Transaction [] - Clear cache on event 'store.init'
Start server
bin/start-hugegraph.sh
Starting HugeGraphServer...
Connecting to HugeGraphServer (http://127.0.0.1:8080/graphs)....OK
⚠️ Deprecated: This backend has been removed starting from HugeGraph 1.7.0. If you need to use it, please refer to version 1.5.x documentation.
users need to install ScyllaDB by themselves, version 2.1 or above is recommended, download link
Update hugegraph.properties
backend=scylladb
serializer=scylladb
# cassandra backend config
cassandra.host=localhost
cassandra.port=9042
cassandra.username=
cassandra.password=
#cassandra.connect_timeout=5
#cassandra.read_timeout=20
#cassandra.keyspace.strategy=SimpleStrategy
#cassandra.keyspace.replication=3
Since the scylladb database itself is an “optimized version” based on cassandra, if the user does not have scylladb installed, they can also use cassandra as the backend storage directly. They only need to change the backend and serializer to scylladb, and the host and post point to the seeds and port of the cassandra cluster. Yes, but it is not recommended to do so, it will not take advantage of scylladb itself.
Initialize the database (required on the first startup, or a new configuration was manually added under ‘conf/graphs/’)
cd *hugegraph-${version}
bin/init-store.sh
Start server
bin/start-hugegraph.sh
Starting HugeGraphServer...
Connecting to HugeGraphServer (http://127.0.0.1:8080/graphs)....OK
users need to install HBase by themselves, requiring version 2.0 or above,download link
Update hugegraph.properties
backend=hbase
serializer=hbase
# hbase backend config
hbase.hosts=localhost
hbase.port=2181
# Note: recommend to modify the HBase partition number by the actual/env data amount & RS amount before init store
# it may influence the loading speed a lot
#hbase.enable_partition=true
#hbase.vertex_partitions=10
#hbase.edge_partitions=30
Initialize the database (required on the first startup, or a new configuration was manually added under ‘conf/graphs/’)
cd *hugegraph-${version}
bin/init-store.sh
Start server
bin/start-hugegraph.sh
Starting HugeGraphServer...
Connecting to HugeGraphServer (http://127.0.0.1:8080/graphs)....OK
for more other backend configurations, please refer tointroduction to configuration options
⚠️ Deprecated: This backend has been removed starting from HugeGraph 1.7.0. If you need to use it, please refer to version 1.5.x documentation.
Because MySQL is licensed under the GPL and incompatible with the Apache License, users must install MySQL themselves, download link
Download the MySQL driver package, such as mysql-connector-java-8.0.30.jar, and place it in the lib directory of HugeGraph-Server.
Update hugegraph.properties to configure the database URL, username, and password.
store is the database name; it will be created automatically if it doesn’t exist.
backend=mysql
serializer=mysql
store=hugegraph
# mysql backend config
jdbc.driver=com.mysql.cj.jdbc.Driver
jdbc.url=jdbc:mysql://127.0.0.1:3306
jdbc.username=
jdbc.password=
jdbc.reconnect_max_times=3
jdbc.reconnect_interval=3
jdbc.ssl_mode=false
Initialize the database (required for first startup or when manually adding new configurations to conf/graphs/)
cd *hugegraph-${version}
bin/init-store.sh
Start server
bin/start-hugegraph.sh
Starting HugeGraphServer...
Connecting to HugeGraphServer (http://127.0.0.1:8080/graphs)....OK
Pass the -p true argument when starting the script to enable preload, which creates a sample graph.
bin/start-hugegraph.sh -p true
Starting HugeGraphServer in daemon mode...
Connecting to HugeGraphServer (http://127.0.0.1:8080/graphs)......OK
And use the RESTful API to request HugeGraphServer and get the following result:
> curl "http://localhost:8080/graphs/hugegraph/graph/vertices" | gunzip
{"vertices":[{"id":"2:lop","label":"software","type":"vertex","properties":{"name":"lop","lang":"java","price":328}},{"id":"1:josh","label":"person","type":"vertex","properties":{"name":"josh","age":32,"city":"Beijing"}},{"id":"1:marko","label":"person","type":"vertex","properties":{"name":"marko","age":29,"city":"Beijing"}},{"id":"1:peter","label":"person","type":"vertex","properties":{"name":"peter","age":35,"city":"Shanghai"}},{"id":"1:vadas","label":"person","type":"vertex","properties":{"name":"vadas","age":27,"city":"Hongkong"}},{"id":"2:ripple","label":"software","type":"vertex","properties":{"name":"ripple","lang":"java","price":199}}]}
This indicates the successful creation of the sample graph.
In 3.1 Use Docker container, we introduced how to deploy hugegraph-server with Docker. You can also switch storage backends or preload a sample graph by setting the corresponding parameters.
⚠️ Deprecated: Cassandra backend has been removed starting from HugeGraph 1.7.0. If you need to use it, please refer to version 1.5.x documentation.
When using Docker, we can use Cassandra as the backend storage. We highly recommend using docker-compose directly to manage both the server and Cassandra.
The sample docker-compose.yml can be obtained on GitHub, and you can start it with docker-compose up -d. (If using Cassandra 4.0 as the backend storage, it takes approximately two minutes to initialize. Please be patient.)
version: "3"
services:
graph:
image: hugegraph/hugegraph
container_name: cas-server
ports:
- 8080:8080
environment:
hugegraph.backend: cassandra
hugegraph.serializer: cassandra
hugegraph.cassandra.host: cas-cassandra
hugegraph.cassandra.port: 9042
networks:
- ca-network
depends_on:
- cassandra
healthcheck:
test: ["CMD", "bin/gremlin-console.sh", "--" ,"-e", "scripts/remote-connect.groovy"]
interval: 10s
timeout: 30s
retries: 3
cassandra:
image: cassandra:4
container_name: cas-cassandra
ports:
- 7000:7000
- 9042:9042
security_opt:
- seccomp:unconfined
networks:
- ca-network
healthcheck:
test: ["CMD", "cqlsh", "--execute", "describe keyspaces;"]
interval: 10s
timeout: 30s
retries: 5
networks:
ca-network:
volumes:
hugegraph-data:
In this YAML file, configuration parameters related to Cassandra need to be passed as environment variables in the format of hugegraph.<parameter_name>.
Specifically, the hugegraph.properties file contains settings such as backend=xxx and cassandra.host=xxx. To pass these settings through environment variables, prepend hugegraph. to the configuration keys, for example hugegraph.backend and hugegraph.cassandra.host.
Refer to 4 Config for the remaining settings.
Set the environment variable PRELOAD=true when starting Docker so that sample data is loaded during startup.
Use docker run
Use docker run -itd --name=server -p 8080:8080 -e PRELOAD=true hugegraph/hugegraph:1.7.0
Use docker-compose
Create a docker-compose.yml file like the following and set PRELOAD=true in the environment. example.groovy is a predefined script used to preload sample data. If needed, you can mount a new example.groovy script to change the preload data.
version: '3'
services:
server:
image: hugegraph/hugegraph:1.7.0
container_name: server
environment:
- PRELOAD=true
- PASSWORD=xxx
volumes:
- /path/to/yourscript:/hugegraph/scripts/example.groovy
ports:
- 8080:8080
Use docker-compose up -d to start the container.
And use the RESTful API to request HugeGraphServer and get the following result:
> curl "http://localhost:8080/graphs/hugegraph/graph/vertices" | gunzip
{"vertices":[{"id":"2:lop","label":"software","type":"vertex","properties":{"name":"lop","lang":"java","price":328}},{"id":"1:josh","label":"person","type":"vertex","properties":{"name":"josh","age":32,"city":"Beijing"}},{"id":"1:marko","label":"person","type":"vertex","properties":{"name":"marko","age":29,"city":"Beijing"}},{"id":"1:peter","label":"person","type":"vertex","properties":{"name":"peter","age":35,"city":"Shanghai"}},{"id":"1:vadas","label":"person","type":"vertex","properties":{"name":"vadas","age":27,"city":"Hongkong"}},{"id":"2:ripple","label":"software","type":"vertex","properties":{"name":"ripple","lang":"java","price":199}}]}
This indicates that the sample graph was created successfully.
Use jps to see a service process
jps
6475 HugeGraphServer
curl request RESTfulAPI
echo `curl -o /dev/null -s -w %{http_code} "http://localhost:8080/graphs/hugegraph/graph/vertices"`
Return 200, which means the server starts normally.
The RESTful API of HugeGraphServer includes various types of resources, typically including graph, schema, gremlin, traverser and task.
graph contains vertices、edgesschema contains vertexlabels、 propertykeys、 edgelabels、indexlabelsgremlin contains various Gremlin statements, such as g.v(), which can be executed synchronously or asynchronouslytraverser contains various advanced queries including shortest paths, intersections, N-step reachable neighbors, etc.task contains query and delete with asynchronous taskshugegraphcurl http://localhost:8080/graphs/hugegraph/graph/vertices
explanation
Since there are many vertices and edges in the graph, for list-type requests, such as getting all vertices, getting all edges, etc., the server will compress the data and return it, so when use curl, you get a bunch of garbled characters, you can redirect to gunzip for decompression. It is recommended to use the Chrome browser + Restlet plugin to send HTTP requests for testing.
curl "http://localhost:8080/graphs/hugegraph/graph/vertices" | gunzip
The current default configuration of HugeGraphServer can only be accessed locally, and the configuration can be modified so that it can be accessed on other machines.
vim conf/rest-server.properties
restserver.url=http://0.0.0.0:8080
response body:
{
"vertices": [
{
"id": "2lop",
"label": "software",
"type": "vertex",
"properties": {
"price": [
{
"id": "price",
"value": 328
}
],
"name": [
{
"id": "name",
"value": "lop"
}
],
"lang": [
{
"id": "lang",
"value": "java"
}
]
}
},
{
"id": "1josh",
"label": "person",
"type": "vertex",
"properties": {
"name": [
{
"id": "name",
"value": "josh"
}
],
"age": [
{
"id": "age",
"value": 32
}
]
}
},
...
]
}
For the detailed API, please refer to RESTful-API
You can also visit localhost:8080/swagger-ui/index.html to check the API.
When using Swagger UI to debug the API provided by HugeGraph, if HugeGraph Server turns on authentication mode, you can enter authentication information on the Swagger page.
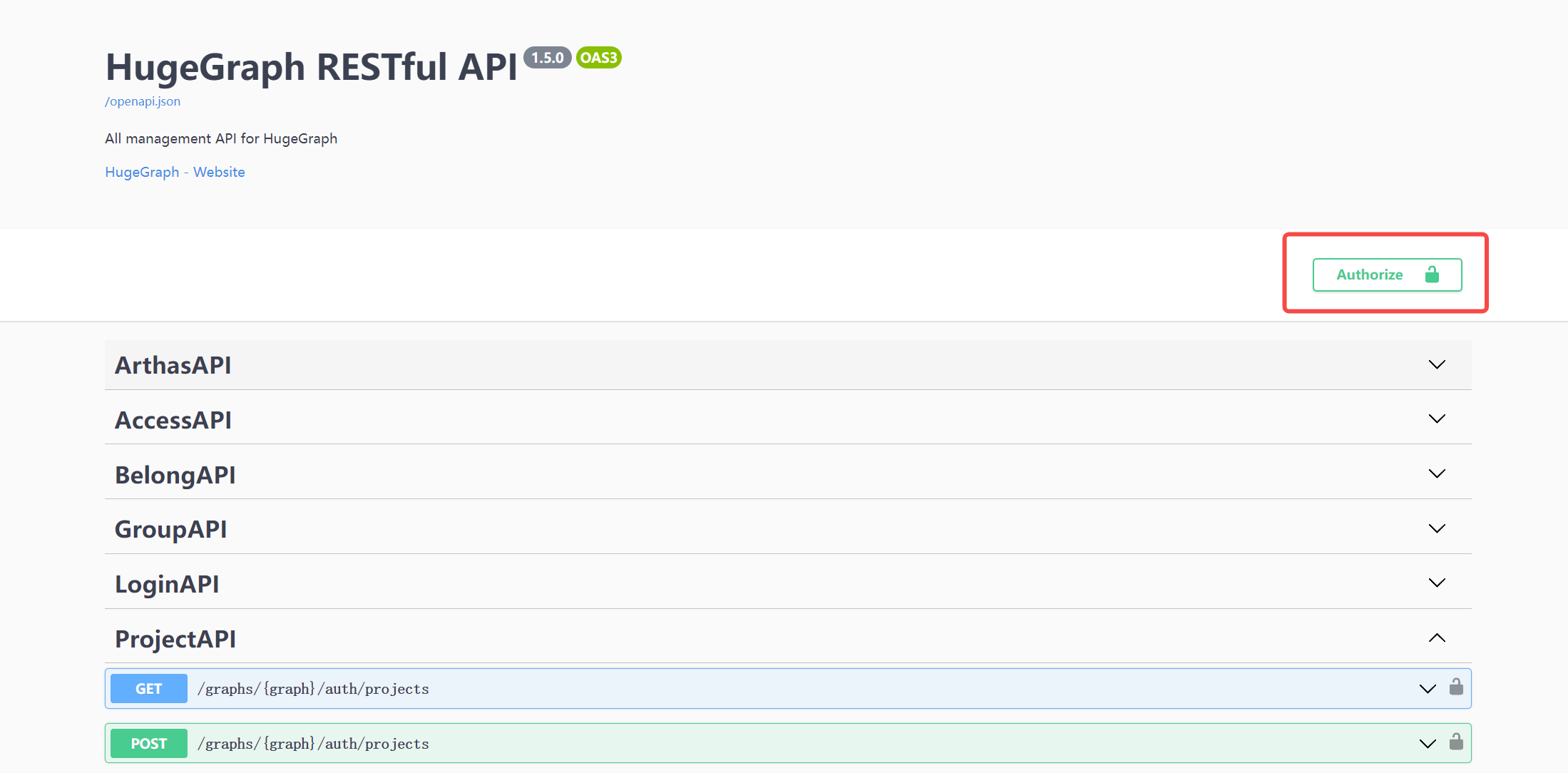
Currently, HugeGraph supports setting authentication information in two forms: Basic and Bearer.
$cd *hugegraph-${version}
$bin/stop-hugegraph.sh
Please refer to Setup Server in IDEA
HugeGraph-PD (Placement Driver) is the metadata management component of HugeGraph’s distributed version, responsible for managing the distribution of graph data and coordinating storage nodes. It plays a central role in distributed HugeGraph, maintaining cluster status and coordinating HugeGraph-Store storage nodes.
There are two ways to deploy the HugeGraph-PD component:
Download the latest version of HugeGraph-PD from the Apache HugeGraph official download page:
# Replace {version} with the latest version number, e.g., 1.5.0
wget https://downloads.apache.org/hugegraph/{version}/apache-hugegraph-incubating-{version}.tar.gz
tar zxf apache-hugegraph-incubating-{version}.tar.gz
cd apache-hugegraph-incubating-{version}/apache-hugegraph-pd-incubating-{version}
# 1. Clone the source code
git clone https://github.com/apache/hugegraph.git
# 2. Build the project
cd hugegraph
mvn clean install -DskipTests=true
# 3. After successful compilation, the PD module build artifacts will be located at
# apache-hugegraph-incubating-{version}/apache-hugegraph-pd-incubating-{version}
# target/apache-hugegraph-incubating-{version}.tar.gz
The HugeGraph-PD Docker image is available on Docker Hub as hugegraph/pd.
Note: The following steps assume you have already cloned or pulled the HugeGraph main repository locally, or at least have its
docker/directory available.
Use the docker compose setup to deploy the complete 3-node cluster (PD + Store + Server):
cd hugegraph/docker
# Keep the version aligned with the latest release, for example 1.x.0
HUGEGRAPH_VERSION=1.7.0 docker compose -f docker-compose-3pd-3store-3server.yml up -d
To run a single PD node via docker run, configuration is provided via environment variables:
docker run -d \
-p 8620:8620 \
-p 8686:8686 \
-p 8610:8610 \
-e HG_PD_GRPC_HOST=<your-ip> \
-e HG_PD_RAFT_ADDRESS=<your-ip>:8610 \
-e HG_PD_RAFT_PEERS_LIST=<your-ip>:8610 \
-e HG_PD_INITIAL_STORE_LIST=<store-ip>:8500 \
-v /path/to/data:/hugegraph-pd/pd_data \
--name hugegraph-pd \
hugegraph/pd:1.7.0
Environment variable reference:
| Variable | Required | Default | Description |
|---|---|---|---|
HG_PD_GRPC_HOST | Yes | — | This node’s hostname/IP for gRPC (e.g. pd0 in Docker, 192.168.1.10 on bare metal) |
HG_PD_RAFT_ADDRESS | Yes | — | This node’s Raft address (e.g. pd0:8610) |
HG_PD_RAFT_PEERS_LIST | Yes | — | All PD peers (e.g. pd0:8610,pd1:8610,pd2:8610) |
HG_PD_INITIAL_STORE_LIST | Yes | — | Expected store gRPC addresses (e.g. store0:8500,store1:8500,store2:8500) |
HG_PD_GRPC_PORT | No | 8686 | gRPC server port |
HG_PD_REST_PORT | No | 8620 | REST API port |
HG_PD_DATA_PATH | No | /hugegraph-pd/pd_data | Metadata storage path |
HG_PD_INITIAL_STORE_COUNT | No | 1 | Minimum stores required for cluster availability |
Note: In Docker bridge networking, use container hostnames (e.g.
pd0) forHG_PD_GRPC_HOSTandHG_PD_RAFT_ADDRESSinstead of IP addresses.
Deprecated aliases:
GRPC_HOST,RAFT_ADDRESS,RAFT_PEERS,PD_INITIAL_STORE_LISTstill work but log a deprecation warning. Use theHG_PD_*names for new deployments.
To view runtime logs for a running PD container use docker logs <container-name> (e.g. docker logs hg-pd0).
See docker/README.md for the full cluster setup guide.
The main configuration file for PD is conf/application.yml. Here are the key configuration items:
spring:
application:
name: hugegraph-pd
grpc:
# gRPC port for cluster mode
port: 8686
host: 127.0.0.1
server:
# REST service port
port: 8620
pd:
# Storage path
data-path: ./pd_data
# Auto-expansion check cycle (seconds)
patrol-interval: 1800
# Minimum number of Store nodes required for cluster availability
initial-store-count: 1
# Store configuration information, format is IP:gRPC port
initial-store-list: 127.0.0.1:8500
raft:
# Cluster mode
address: 127.0.0.1:8610
# Raft addresses of all PD nodes in the cluster
peers-list: 127.0.0.1:8610
store:
# Store offline time (seconds). After this time, the store is considered permanently unavailable
max-down-time: 172800
# Whether to enable store monitoring data storage
monitor_data_enabled: true
# Monitoring data interval
monitor_data_interval: 1 minute
# Monitoring data retention time
monitor_data_retention: 1 day
initial-store-count: 1
partition:
# Default number of replicas per partition
default-shard-count: 1
# Default maximum number of replicas per machine
store-max-shard-count: 12
For multi-node deployment, you need to modify the port and address configurations for each node to ensure proper communication between nodes.
In the PD installation directory, execute:
./bin/start-hugegraph-pd.sh
After successful startup, you can see logs similar to the following in logs/hugegraph-pd-stdout.log:
YYYY-mm-dd xx:xx:xx [main] [INFO] o.a.h.p.b.HugePDServer - Started HugePDServer in x.xxx seconds (JVM running for x.xxx)
In the PD installation directory, execute:
./bin/stop-hugegraph-pd.sh
Confirm that the PD service is running properly:
curl http://localhost:8620/actuator/health
If it returns {"status":"UP"}, it indicates that the PD service has been successfully started.
Additionally, you can verify Store node status through the PD API:
curl http://localhost:8620/v1/stores
If the response shows state as Up, the corresponding Store node is running normally. The example below shows a single Store node. In a healthy 3-node deployment, the storeId list should contain three IDs, and stateCountMap.Up, numOfService, and numOfNormalService should all be 3.
{
"message": "OK",
"data": {
"stores": [
{
"storeId": 8319292642220586694,
"address": "127.0.0.1:8500",
"raftAddress": "127.0.0.1:8510",
"version": "",
"state": "Up",
"deployPath": "/Users/{your_user_name}/hugegraph/apache-hugegraph-incubating-1.5.0/apache-hugegraph-store-incubating-1.5.0/lib/hg-store-node-1.5.0.jar",
"dataPath": "./storage",
"startTimeStamp": 1754027127969,
"registedTimeStamp": 1754027127969,
"lastHeartBeat": 1754027909444,
"capacity": 494384795648,
"available": 346535829504,
"partitionCount": 0,
"graphSize": 0,
"keyCount": 0,
"leaderCount": 0,
"serviceName": "127.0.0.1:8500-store",
"serviceVersion": "",
"serviceCreatedTimeStamp": 1754027127000,
"partitions": []
}
],
"stateCountMap": {
"Up": 1
},
"numOfService": 1,
"numOfNormalService": 1
},
"status": 0
}
HugeGraph-Store is the storage node component of HugeGraph’s distributed version, responsible for actually storing and managing graph data. It works in conjunction with HugeGraph-PD to form HugeGraph’s distributed storage engine, providing high availability and horizontal scalability.
There are two ways to deploy the HugeGraph-Store component:
Download the latest version of HugeGraph-Store from the Apache HugeGraph official download page:
# Replace {version} with the latest version number, e.g., 1.5.0
wget https://downloads.apache.org/hugegraph/{version}/apache-hugegraph-incubating-{version}.tar.gz
tar zxf apache-hugegraph-incubating-{version}.tar.gz
cd apache-hugegraph-incubating-{version}/apache-hugegraph-hstore-incubating-{version}
# 1. Clone the source code
git clone https://github.com/apache/hugegraph.git
# 2. Build the project
cd hugegraph
mvn clean install -DskipTests=true
# 3. After successful compilation, the Store module build artifacts will be located at
# apache-hugegraph-incubating-{version}/apache-hugegraph-hstore-incubating-{version}
# target/apache-hugegraph-incubating-{version}.tar.gz
The HugeGraph-Store Docker image is available on Docker Hub as hugegraph/store.
Note: The following steps assume you have already cloned or pulled the HugeGraph main repository locally, or at least have its
docker/directory available.
Use the compose file to deploy the complete 3-node cluster (PD + Store + Server):
cd hugegraph/docker
# Keep the version aligned with the latest release, for example 1.x.0
HUGEGRAPH_VERSION=1.7.0 docker compose -f docker-compose-3pd-3store-3server.yml up -d
To run a single Store node via docker run:
docker run -d \
-p 8520:8520 \
-p 8500:8500 \
-p 8510:8510 \
-e HG_STORE_PD_ADDRESS=<pd-ip>:8686 \
-e HG_STORE_GRPC_HOST=<your-ip> \
-e HG_STORE_RAFT_ADDRESS=<your-ip>:8510 \
-v /path/to/storage:/hugegraph-store/storage \
--name hugegraph-store \
hugegraph/store:1.7.0
Environment variable reference:
| Variable | Required | Default | Description |
|---|---|---|---|
HG_STORE_PD_ADDRESS | Yes | — | PD gRPC addresses (e.g. pd0:8686,pd1:8686,pd2:8686) |
HG_STORE_GRPC_HOST | Yes | — | This node’s hostname/IP for gRPC (e.g. store0) |
HG_STORE_RAFT_ADDRESS | Yes | — | This node’s Raft address (e.g. store0:8510) |
HG_STORE_GRPC_PORT | No | 8500 | gRPC server port |
HG_STORE_REST_PORT | No | 8520 | REST API port |
HG_STORE_DATA_PATH | No | /hugegraph-store/storage | Data storage path |
Note: In Docker bridge networking, use container hostnames (e.g.
store0) forHG_STORE_GRPC_HOSTinstead of IP addresses.
Deprecated aliases:
PD_ADDRESS,GRPC_HOST,RAFT_ADDRESSstill work but log a deprecation warning. Use theHG_STORE_*names for new deployments.
The main configuration file for Store is conf/application.yml. Here are the key configuration items:
pdserver:
# PD service address, multiple PD addresses are separated by commas (configure PD's gRPC port)
address: 127.0.0.1:8686
grpc:
# gRPC service address
host: 127.0.0.1
port: 8500
netty-server:
max-inbound-message-size: 1000MB
raft:
# raft cache queue size
disruptorBufferSize: 1024
address: 127.0.0.1:8510
max-log-file-size: 600000000000
# Snapshot generation time interval, in seconds
snapshotInterval: 1800
server:
# REST service address
port: 8520
app:
# Storage path, supports multiple paths separated by commas
data-path: ./storage
#raft-path: ./storage
spring:
application:
name: store-node-grpc-server
profiles:
active: default
include: pd
logging:
config: 'file:./conf/log4j2.xml'
level:
root: info
For multi-node deployment, you need to modify the following configurations for each Store node:
grpc.port (RPC port) for each noderaft.address (Raft protocol port) for each nodeserver.port (REST port) for each nodeapp.data-path (data storage path) for each nodeEnsure that the PD service is already started, then in the Store installation directory, execute:
./bin/start-hugegraph-store.sh
After successful startup, you can see logs similar to the following in logs/hugegraph-store-server.log:
YYYY-mm-dd xx:xx:xx [main] [INFO] o.a.h.s.n.StoreNodeApplication - Started StoreNodeApplication in x.xxx seconds (JVM running for x.xxx)
In the Store installation directory, execute:
./bin/stop-hugegraph-store.sh
Below is a configuration example for a three-node deployment:
For the three Store nodes, the main configuration differences are as follows:
Node A:
grpc:
port: 8500
raft:
address: 127.0.0.1:8510
server:
port: 8520
app:
data-path: ./storage-a
Node B:
grpc:
port: 8501
raft:
address: 127.0.0.1:8511
server:
port: 8521
app:
data-path: ./storage-b
Node C:
grpc:
port: 8502
raft:
address: 127.0.0.1:8512
server:
port: 8522
app:
data-path: ./storage-c
All nodes should point to the same PD cluster:
pdserver:
address: 127.0.0.1:8686,127.0.0.1:8687,127.0.0.1:8688
The distributed Store cluster definition is included in docker/docker-compose-3pd-3store-3server.yml. Each Store node gets its own hostname and environment variables:
# store0
HG_STORE_PD_ADDRESS: pd0:8686,pd1:8686,pd2:8686
HG_STORE_GRPC_HOST: store0
HG_STORE_GRPC_PORT: "8500"
HG_STORE_REST_PORT: "8520"
HG_STORE_RAFT_ADDRESS: store0:8510
HG_STORE_DATA_PATH: /hugegraph-store/storage
# store1
HG_STORE_PD_ADDRESS: pd0:8686,pd1:8686,pd2:8686
HG_STORE_GRPC_HOST: store1
HG_STORE_RAFT_ADDRESS: store1:8510
# store2
HG_STORE_PD_ADDRESS: pd0:8686,pd1:8686,pd2:8686
HG_STORE_GRPC_HOST: store2
HG_STORE_RAFT_ADDRESS: store2:8510
Store nodes start only after all PD nodes pass healthchecks (/v1/health), enforced via depends_on: condition: service_healthy.
To view runtime logs for a running Store container use docker logs <container-name> (e.g. docker logs hg-store0).
See docker/README.md for the full setup guide.
Confirm that the Store service is running properly:
curl http://localhost:8520/actuator/health
If it returns {"status":"UP"}, it indicates that the Store service has been successfully started.
Additionally, you can check the status of Store nodes in the cluster through the PD API:
curl http://localhost:8620/v1/stores
If Store is configured successfully, the response should include status information for the current node, and state: "Up" means the node is running normally.
The example below shows a single Store node. If all three nodes are configured correctly and running, the storeId list should contain three IDs, and stateCountMap.Up, numOfService, and numOfNormalService should all be 3.
{
"message": "OK",
"data": {
"stores": [
{
"storeId": 8319292642220586694,
"address": "127.0.0.1:8500",
"raftAddress": "127.0.0.1:8510",
"version": "",
"state": "Up",
"deployPath": "/Users/{your_user_name}/hugegraph/apache-hugegraph-incubating-1.5.0/apache-hugegraph-store-incubating-1.5.0/lib/hg-store-node-1.5.0.jar",
"dataPath": "./storage",
"startTimeStamp": 1754027127969,
"registedTimeStamp": 1754027127969,
"lastHeartBeat": 1754027909444,
"capacity": 494384795648,
"available": 346535829504,
"partitionCount": 0,
"graphSize": 0,
"keyCount": 0,
"leaderCount": 0,
"serviceName": "127.0.0.1:8500-store",
"serviceVersion": "",
"serviceCreatedTimeStamp": 1754027127000,
"partitions": []
}
],
"stateCountMap": {
"Up": 1
},
"numOfService": 1,
"numOfNormalService": 1
},
"status": 0
}